最近做了一个甲骨文识别项目,在此分享一下。
文末附有源码。
视频展示:
基于opencv和深度学习的甲骨文识别
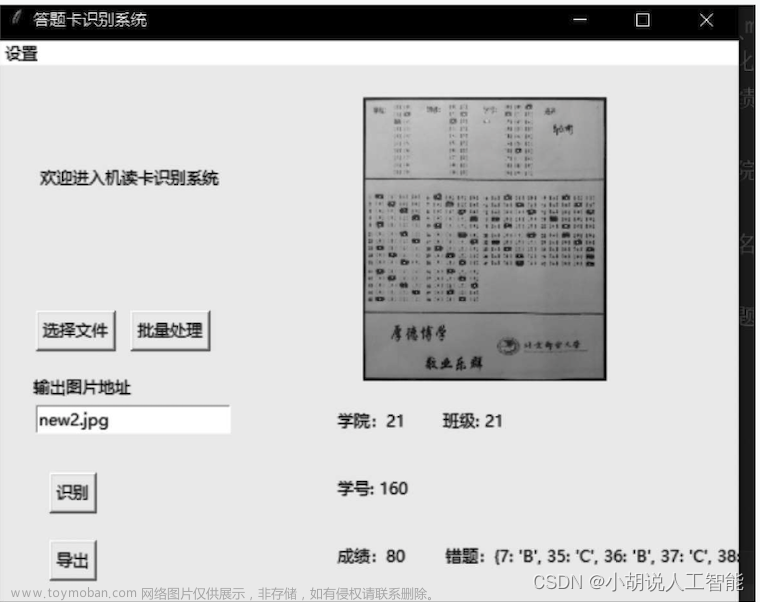
运行界面:
识别结果:
本文一共可识别1135个甲骨文,数据集已经放到下载链接中:
下面是代码部分:
读取数据:
import cv2 as cv
import os
import numpy as np
f=open('lab.txt',encoding='utf-8')
lines=f.readlines()
f.close()
split=0.2
np.random.seed(10)
np.random.shuffle(lines)
bb=int(len(lines)*(1-0.2))
vv=len(lines)-bb
train_lines=lines[:bb]
valid_lines=lines[bb:]
def generate(train=True,valid=False,batch_size=32):
while True:
ee=np.eye(1185)
if train:
linnns=train_lines
elif valid:
linnns=valid_lines
else:break
x=[]
y=[]
for lin in linnns:
lu_jing=lin.split()[0]
lab=lin.split()[1]
src=cv.imdecode(np.fromfile(lu_jing, dtype=np.uint8), 1)
h,w,d=src.shape[0],src.shape[1],src.shape[2]
if h==96 and w==96 and d==3:
src=(src/255).astype('float32')
ll=ee[int(lab)]
x.append(src)
y.append(ll)
if len(x)==batch_size:
x_train=np.array(x)
y_train=np.array(y)
x=[]
y=[]
yield x_train,y_train
if __name__ == '__main__':
generate()
训练网络模型:
from tensorflow.keras.layers import Conv2D,MaxPooling2D,Input,Flatten,Dense,Dropout
from tensorflow.keras import Model
from tensorflow.keras.callbacks import (EarlyStopping, ReduceLROnPlateau,
TensorBoard,ModelCheckpoint)
from get_data import generate,bb,vv
def mode(shape=(96,96,3)):
inputs=Input(shape=shape)
x=Conv2D(filters=6,kernel_size=5,strides=(1,1),padding='same',activation='relu')(inputs)
x=MaxPooling2D(pool_size=(2,2),strides=(2,2),padding='same')(x)
x=Conv2D(filters=16,kernel_size=3,strides=(1,1),padding='same',activation='relu')(x)
x = MaxPooling2D(pool_size=(2, 2), strides=(2, 2), padding='same')(x)
x=Flatten()(x)
x=Dense(1000,activation='relu')(x)
x=Dropout(rate=0.5)(x)
x=Dense(500,activation='relu')(x)
y = Dense(1185, activation='softmax')(x)
model=Model(inputs,y)
return model
modell=mode()
modell.summary()
if __name__ == '__main__':
modell.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
log_dir = 'logs/'
logging = TensorBoard(log_dir=log_dir)
checkpoint = ModelCheckpoint(log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='val_loss', save_weights_only=True, save_best_only=False, period=1)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=3, verbose=1)
early_stopping = EarlyStopping(monitor='val_loss', min_delta=0, patience=10, verbose=1)
TensorBoard = TensorBoard(log_dir='./model', histogram_freq=1)
batch_size=50
hist = modell.fit_generator(generate(batch_size=batch_size),
steps_per_epoch=bb//batch_size,
validation_data=generate(valid=True,batch_size=batch_size),
validation_steps=vv//batch_size,
epochs=50,
callbacks=[logging, checkpoint, reduce_lr, early_stopping])
预测:文章来源:https://www.toymoban.com/news/detail-851949.html
from model import modell
import cv2 as cv
import numpy as np
with open('answer.txt','r',encoding='utf-8') as f:
lines=f.readlines()
modell.load_weights('logs/ep030-loss0.037-val_loss0.024.h5')
def ppre(src):
#src=cv.imdecode(np.fromfile('ancient_3_exp/jia/丘/0/O000255_exp_1.png', dtype=np.uint8), 1)
src=np.reshape(src,(1,src.shape[0],src.shape[1],src.shape[2]))
src=(src/255).astype('float32')
pre=modell.predict(src)[0]
pre=np.argmax(pre)
return lines[pre]
if __name__ == '__main__':
src = cv.imdecode(np.fromfile('ancient_3_exp/jia/丘/0/O000255_exp_1.png', dtype=np.uint8), 1)
zti=ppre(src)
print(zti)
界面已经使用pyqt5做好,下载以后只需运行main.py程序即可,下图是程序目录:

如有疑问可私信作者。
下载地址:下载列表13文章来源地址https://www.toymoban.com/news/detail-851949.html
到了这里,关于基于深度学习和opencv的甲骨文识别系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!