前言
目前比较接近sora的开源路线是:Stable Video Diffusion(关于SVD的介绍请看此文的第4部分]) + Stable Diffusion3的结构(SD3的详细介绍见此文的第4部分)
- 其他的比如VDT虽然与sora架构最相似,但vdt本身因为没有做产品化 所以效果比较一般(加之vdt的权重在24年Q1之内还没有开放),如果想走这条路线,那需要做的改动还是比较大的
- 至于还有走基于videoGPT路线的,要做的就更多了,毕竟videoGPT都2021年的东西了
另,注意 如果此前对sora原理并不了解的,请先看本sora系列的上一篇文章:视频生成模型Sora的全面解析:从AI绘画、ViT到ViViT、DiT、VDT、NaViT等(含sora复现)「下文提到此文时会简称为:sora全面解析一文」,避免一脸懵
第一部分 Sora爆火之前,上海人工智能实验室一团队推出Latte
24年1月5日,受DiT、U-ViT在图像生成领域的成功,上海AI实验室的一个团队推出了把“DiT/U-ViT架构用到视频生成领域”的类sora开源系统Latte(其对应论文为:Latte: Latent Diffusion Transformer for Video Generation,其对应的GitHub地址为:GitHub - Vchitect/Latte: Latte: Latent Diffusion Transformer for Video Generation.)
通过本博客之前的文章可知,stable diffusion所基于的潜在扩散模型(Latent Diffusion Models, LDMs),通过在潜在空间而不是像素空间中进行扩散过程
LDMs首先利用预训练的变分自动编码器的编码器将输入数据样本压缩成较低维度的潜在编码。随后,它通过两个关键过程学习数据分布:扩散和去噪
- 扩散过程逐渐将高斯噪声引入潜在编码,生成扰动样本
,其中,遵循跨越个阶段的马尔可夫链
作为噪声调度器,其中 表示扩散的时间步 - 去噪过程中,需要不断预测噪声,其中变分下界的对数似然缩减为
其中,噪声估计使用去噪模型实现,并通过以下目标函数进行训练(说白了,就是不断减少预测噪声与真实噪声之间的差距)
且为了使用学习的逆过程协方差Σθ来训练扩散模型,需要优化完整的项,因此使用完整的进行训练,表示为。 此外,是使用实现
更多细节请参见上文提过多次的此文第二部分《图像生成发展起源:从VAE、VQ-VAE、扩散模型DDPM、DETR到ViT、Swin transformer》
而Latte将LDMs扩展到视频生成,具体为:
- 首先通过预训练的变分自动编码器VAE 将视频逐帧从像素空间压缩到潜在空间,然后视频 DiT 对隐式表征提取 token(提取视频patch组成tokens)
- 扩散过程在视频的潜在空间中进行,以建模潜在的空间和时间信息,其中噪声估计器通过transformer实现而非U-Net(即使用 Transformer 替换 U-Net 预测噪声的均值和方差,并且噪声是4维的)
过程中同时使用和训练所有模型 - 最后 VAE 解码器将特征映射回像素空间生成视频
1.1 整体流程:输入、主干网络(Latte的4种变体)、输出
1.1.1 输入
- 视频片段经VAE压缩后假设为,编码后得到 tokens ,维度为
其中,分别表示潜在空间中视频帧的数量、视频帧的高度、宽度和通道数(相当于总计F帧,然后每一帧的宽度、高度分别为H、W) - 和位置时空位置编码 相加构成Transformer的输入
1.1.2 主干网络:Latte的4种变体(类似VDT)
主干网络:考虑到输入视频的空间和时间信息之间的固有差异以及从输入视频中提取出大量标记,如下图所示:从分解输入视频的空间和时间维度的角度,设计了4种高效的基于Transformer的模型变体(有没发现,下图的变体3类似于sora全面解析一文介绍过的VDT),以有效捕获视频中的时空信息
首先是单注意力机制模块,每个模块中只包含时间或者空间注意力

-
时空交错式建模 (Variant 1):先空间transformer、后时间transformer交替进行
如上图a所示,这种变体的Transformer骨干由两种不同类型的Transformer块组成:空间Transformer块和时间Transformer块
前者专注于在具有相同时间索引的token之间仅捕获空间信息,而后者以“交错融合”的方式跨时间维度以捕获时间信息
假设我们有一个视频剪辑在潜在空间中,首先将转换为一个token序列: (和Sora把视频内容转化成一系列token的思路完全一致)
视频剪辑在潜在空间中的token总数是,而 表示每个token的维度,随后将时空位置嵌入加入到中,最后将得到的作为Transformer骨干的输入
从而可以将由重新整形成 (其中表示每个时间索引的token数量),作为空间Transformer块的输入,用于捕获空间信息
随后,包含空间信息的被重新调整成,作为时间Transformer块的输入,用于捕获时间信息
说白了,变体1的整个流程是首先将输入 reshape 成,维度为,其中,先过空间Transoformer block,然后 reshape 成,维度为,过时间 Transformer block,循环几次 -
时空顺序式建模 (Variant 2):先一组空间transformer 再一组时间transformer
与变体1中的时间“交错融合”设计相比,变体2采用“后期融合”方法来结合时空信息
如上图b所示,变体2有着与变体1相同数量的transformer块
与变体1类似,空间transformer块和时间transformer块的输入形状分别为和
说白了,变体2类似变体1,只是先一组空间再一组时序
接下来是,多注意力机制模块,每个模块中同时包含时间与空间注意力机制 (Open-sora所参考变体)
-
串联式时空注意力机制 (Variant 3):只统一用一个transformer 先空间维度计算 再时间维度计算
变体1和变体2主要关注Transformer块的因式分解, 变体3专注于分解Transformer块中的多头注意力
如上图c所示,该变体首先在空间维度上计算自注意力,然后在时间维度上计算自注意力。 因此,每个Transformer块都捕捉到了空间和时间信息
与变体1和变体2类似,空间多头自注意力、时间多头自注意力的输入分别为、
说白了,相当于a、b都使用完整的 Tranformer block 学习单一时间或空间信息,c是修改了Tranformer block 内部结构,MHA 先在空间维度计算自注意力,然后在时间维度计算
这样每个 Tranformer block 就相当于融合了时间和空间信息 -
并联式时空注意力机制 (Variant 4):只统一用一个transformer 但拆成两个部分 一部分计算空间 一部分计算时间
在这个变体中,将多头注意力MHA分解为两个组件,每个组件利用一半的注意力头,如上图d所示
使用不同的组件分别处理空间和时间维度中的token,这些不同组件的输入形状分别为和
一旦计算出两个不同的注意力操作,我们将重新调整形状为。然后被添加到中,作为Transformer块中下一个模块的输入
说白了,相当于在 Tranformer block 内部将 MHA 分成了两部分,一部分计算空间,一部分计算时间,最后再融合
1.1.3 输出
输出:在Transformer主干之后,一个关键的过程涉及解码视频token序列,以得到预测的噪声和预测的协方差。 这两个输出的形状与输入相同
1.2 视频 patch embedding、Timestep-class 信息融入、空间位置 embedding、学习策略
1.2.1 视频 patch embedding
对于视频patch的嵌入,有如下两种方法

- 均匀帧patch嵌入
采样的 F帧都使用 ViT 的 patch 方式,类似平面操作,这样 ,,和 表示每个 patch 的大小 - 压缩帧patch嵌入
使用 ViViT 的方式(ViViT的介绍见sora全面解析一文),在时序上采样,类似立体操作(相当于捕捉时间信息,并将ViT块嵌入方法从2D扩展到3D,然后沿时间维度提取管道),这样
很明显,第二种方法融入了时空信息,因此还需要使用3D转置卷积对“输出的潜在视频”进行时间维度的上采样,随后是标准线性解码器和重塑操作(an additional step entails integrating a 3D transposed convolution for temporal up sampling of the output latent videos, following the standard linear decoder and reshaping operation)
1.2.2 Timestep-class 信息融入

Timestep 以及 class 信息 注入到模型采用了两种方式:
- 直接作为 tokens 加到输入中
- 使用 DiT 的自适应层归一化 AdaLN 方式
即基于输入 通过 MLP 计算出 和 ,这样,其中 表示为transformer快中的隐藏嵌入
此外,还新增一个 scale 向量 ,对其进行回归操作,且应用在所有残差连接中,使得最终,取名为 S-AdaLN
1.2.3 空间位置 embedding
时序位置编码方式一般有两种选择,比如绝对位置编码和相对位置编码RoPE(实验证明两种方式区别不大),至于空间位置就是使用默认方式
1.2.4 学习策略:在DiT图像预训练模型基础上增加时间维度,且图像-视频联合训练
Latte 使用了DiT 在 ImageNet 上的预训练模型,并作了一些改进
- DiT 位置编码 embedding 维度是,但是 Latte 的时空位置编码 embedding 维度是 ,相当于因为需要带上时间维度的关系,在DiT的基础上复制了份
此外还去掉了 label embedding layer - 且考虑到「基于 CNN 的视频生成方法提出图像和视频同时训练」会对最终的效果提升明显,故Latte将该技术应用到了Transformer 架构中
具体做法是在视频后面随机添加一些同一数据集其它视频的帧用于图像生成任务,时序相关的 tokens 只作用在视频部分
第二部分 Colossal-AI团队推出基于STDiT架构的类Sora模型Open-Sora 1.0
2.1 Open-sora 1.0的架构设计
2.1.1 给文生图模型PixArt-α增加时间注意力层
模型采用了上面介绍过的 Diffusion Transformer(DiT)架构
- 作者团队以同样使用 DiT 架构的高质量开源文生图模型 PixArt-α [PixArt-α: Fast Training of Diffusion Transformer for Photorealistic Text-to-Image Synthesis] 为基座
- 然后在此基础上引入时间注意力层,将其扩展到了视频数据上
具体来说,整个架构包括一个预训练好的 VAE,一个文本编码器,和一个带有空间-时间注意力机制的STDiT模型(Spatial Temporal Diffusion Transformer,说白了,就是给DiT加上时空注意力,类似sora全面解析一文介绍过的VDT),STDiT的初始化版本则相当于给PixArt-alpha 加上时间注意力

整个模型的训练和推理流程如下
- 在训练阶段,首先采用预训练好的 Variational Autoencoder (VAE) 的编码器将视频数据进行压缩,然后在压缩之后的潜在空间中与文本嵌入(text embedding)一起训练 STDiT 扩散模型
- 在推理阶段,从 VAE 的潜在空间中随机采样出一个高斯噪声,与提示词嵌入 (prompt embedding) 一起输入到 STDiT 中,得到去噪之后的特征,最后输入到 VAE 的解码器,解码得到视频
2.1.2 STDiT
再进一步阐述下STDiT,下图左侧为STDiT 每层的结构(看图时从下往上看),下图右侧是上面2.4节介绍过的带Cross Attention的VDT,这两个结构的区别在于各个注意力层的组织顺序不同,但不影响本质是一样的

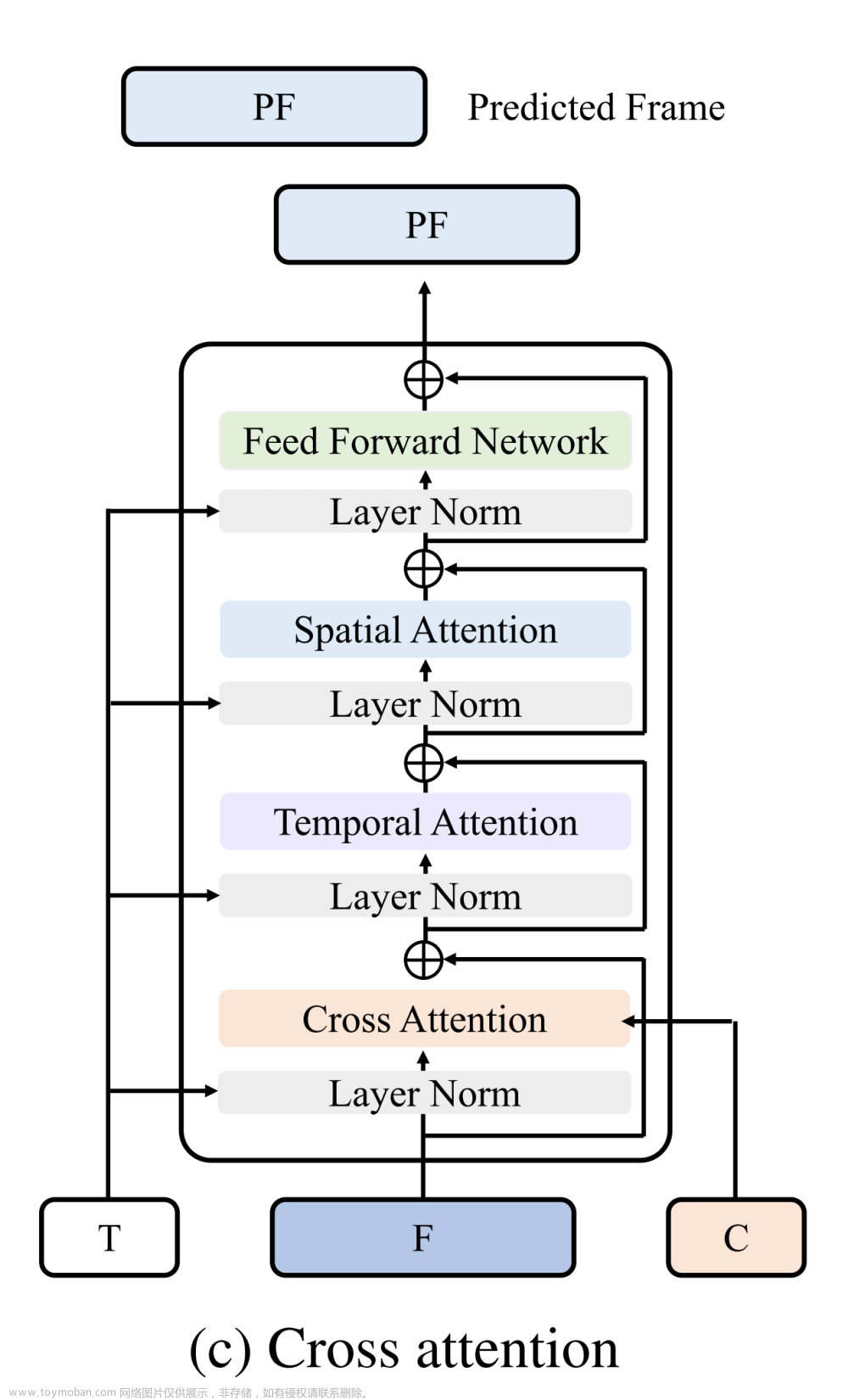
- 它采用串行的方式在二维的空间注意力模块上叠加一维的时间注意力模块,用于建模时序关系
- 在时间注意力模块之后,交叉注意力模块用于对齐文本的语意。与全注意力机制相比,这样的结构大大降低了训练和推理开销
与上节介绍过的同样使用空间 - 时间注意力机制的 Latte [Latent Diffusion Transformer for Video Generation] 模型相比,STDiT 可以更好的利用已经预训练好的图像 DiT 的权重,从而在视频数据上继续训练
2.2 训练复现方案:类似SVD的三阶段训练
Open-Sora 的复现方案参考了Stable Video Diffusion的工作,共包括三个阶段,分别是:

-
基于「SD微调过后的图像VAE」做大规模图像预训练
第一阶段通过大规模图像预训练,借助成熟的文生图模型,有效降低视频预训练成本
具体而言,通过互联网上丰富的大规模图像数据和先进的文生图技术,可以训练一个高质量的文生图模型,该模型将作为下一阶段视频预训练的初始化权重。同时,由于目前没有高质量的时空 VAE(他们觉得VideoGPT的VQ-VAE质量较低,我也这么认为,所以在VideoGPT基础上去复现,会增加更多的工作 ),他们采用了Stability AI通过Stable Diffusion模型预训练好的图像 VAE [https://huggingface.co/stabilityai/sd-vae-ft-mse-original ] -
基于「带时序注意力的文生图模型PixArt-alpha + T5」做大规模视频预训练
这个阶段需要使用大量视频数据训练,保证视频题材的多样性,从而增加模型的泛化能力(且有效掌握视频的时间序列关联)
Colossal-AI 团队使用了 PixArt-alpha 的开源权重作为第二阶段 STDiT 模型的初始化(且加载第一阶段权重,但与第一阶段不同的是加入了时序注意力模块,用于学习视频中的时序关系,同时初始化时序注意力模块输出为零,以达到更高效更快速的收敛)
以及采用了 T5 [T5: Text-To-Text Transfer Transformer] 模型作为文本编码器。同时他们采用了 256x256 的小分辨率进行预训练,进一步增加了收敛速度,降低训练成本 -
基于「高质量视频数据」进一步微调
第三阶段对高质量视频数据进行微调,显著提升视频生成的质量
作者团队提及第三阶段用到的视频数据规模比第二阶段要少一个量级,但是视频的时长、分辨率和质量都更高。通过这种方式进行微调,他们实现了视频生成从短到长、从低分辨率到高分辨率、从低保真度到高保真度的高效扩展
作者团队表示,在 Open-Sora 的复现流程中,他们使用了 64 块 H800 进行训练。第二阶段的训练量一共是 2808 GPU hours,约合 7000 美元,第三阶段的训练量是 1920 GPU hours,大约 4500 美元。经过初步估算,整个训练方案成功把 Open-Sora 复现流程控制在了 1 万美元左右
且每个阶段都会基于前一个阶段的权重继续训练。相比于从零开始单阶段训练,多阶段训练通过逐步扩展数据,更高效地达成高质量视频生成的目标
2.3 数据预处理
为了进一步降低 Sora 复现的门槛和复杂度,Colossal-AI 团队在代码仓库中还提供了便捷的视频数据预处理脚本,让大家可以轻松启动 Sora 复现预训练,包括公开视频数据集下载,长视频根据镜头连续性分割为短视频片段,使用开源大语言模型 LLaVA [https://github.com/haotian-liu/LLaVA] 生成精细的提示词
作者团队提到他们提供的批量视频标题生成代码可以用两卡 3 秒标注一个视频,并且质量接近于 GPT-4V。最终得到的视频 / 文本对可直接用于训练。借助他们在 GitHub 上提供的开源代码,我们可以轻松地在自己的数据集上快速生成训练所需的视频 / 文本对,显著降低了启动 Sora 复现项目的技术门槛和前期准备

第三部分 StreamingT2V
// 待更文章来源:https://www.toymoban.com/news/detail-851999.html
更多则在该课里见:视频生成Sora的原理与复现 [全面解析且从零复现sora缩略版],和七月团队一同复现sora缩略版文章来源地址https://www.toymoban.com/news/detail-851999.html
参考文献与推荐阅读
- 详解Latte:去年底上线的全球首个开源文生视频DiT
-
超越Sora极限,120秒超长AI视频模型诞生
两分钟1200帧的长视频生成器StreamingT2V来了,代码将开源 - 复刻Sora的通用视频生成能力,开源多智能体框架Mora来了
- 国产Sora来了,4K 60帧15秒视频刷新纪录!500亿美元短剧出海市场被撬动,Etna
到了这里,关于视频生成Sora的从零复现:从Latte、Open-Sora 1.0到StreamingT2V的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!