第1关:HDFS的基本操作
任务描述
本关任务:使用Hadoop命令来操作分布式文件系统。
相关知识
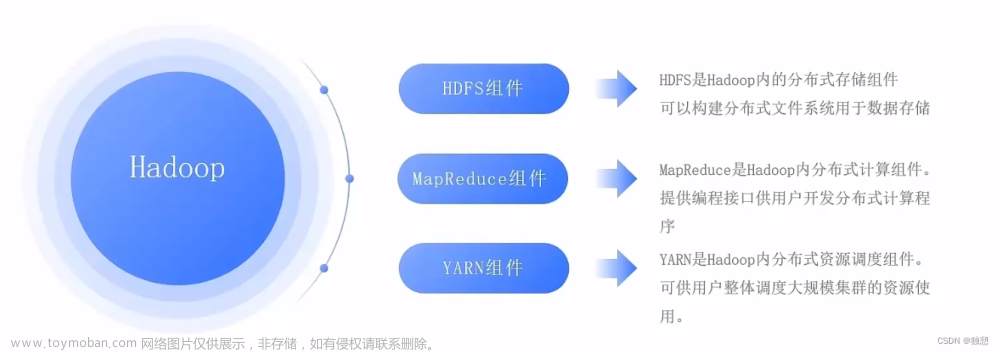
为了完成本关任务你需要了解的知识有:1.HDFS的设计,2.HDFS常用命令。
HDFS的设计
分布式文件系统
客户:帮我保存一下这几天的数据。
程序猿:好嘞,有多大呢?
客户:1T。
程序猿:好没问题,买个硬盘就搞定了。
一个月后…
客户:帮我保存下这几个月的数据。
程序猿:好嘞,这次有多大呢?
客户:1024T。
程序猿:哇,这么大吗?没有这么大的硬盘买呀,而且好像也没听过一台计算机可以存放1024T的数据。
程序猿:哦,对了我可以部署1024台机器,然后将他们连接起来,让他们的数据可以共享,这不就可以了吗?hh,机智如我。
当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区并存储到若干台单独的计算机上,管理网络中跨多台计算机存储的文件系统称为分布式文件系统(Distributed FileSystem)。
Hadoop自带一个称为HDFS的分布式文件系统,即HDFS(Hadoop Distributed FileSystem)。有时也称之为DFS,他们是一回事儿。
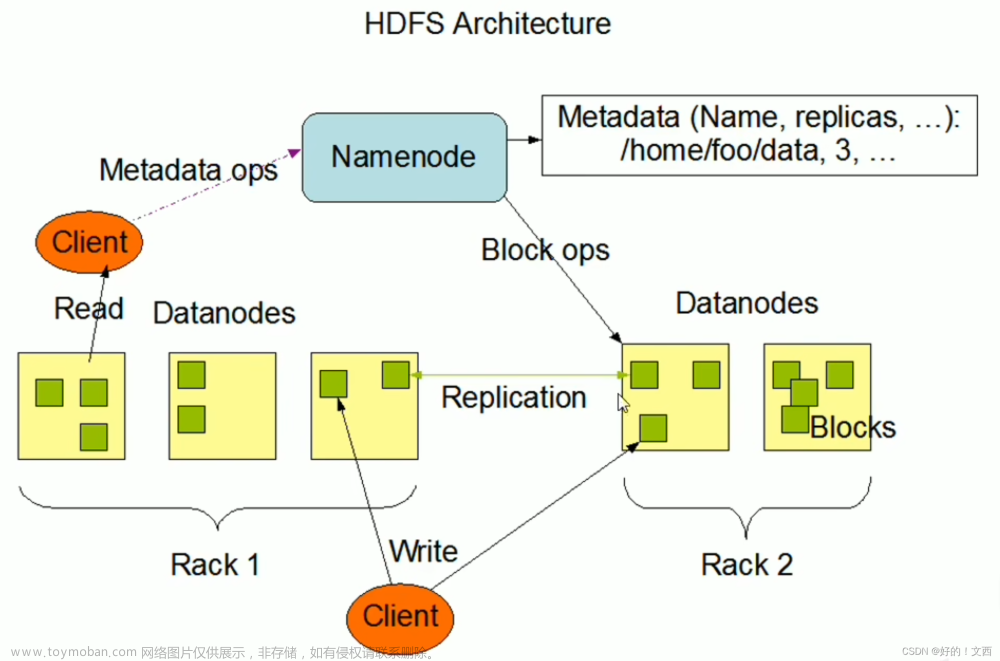
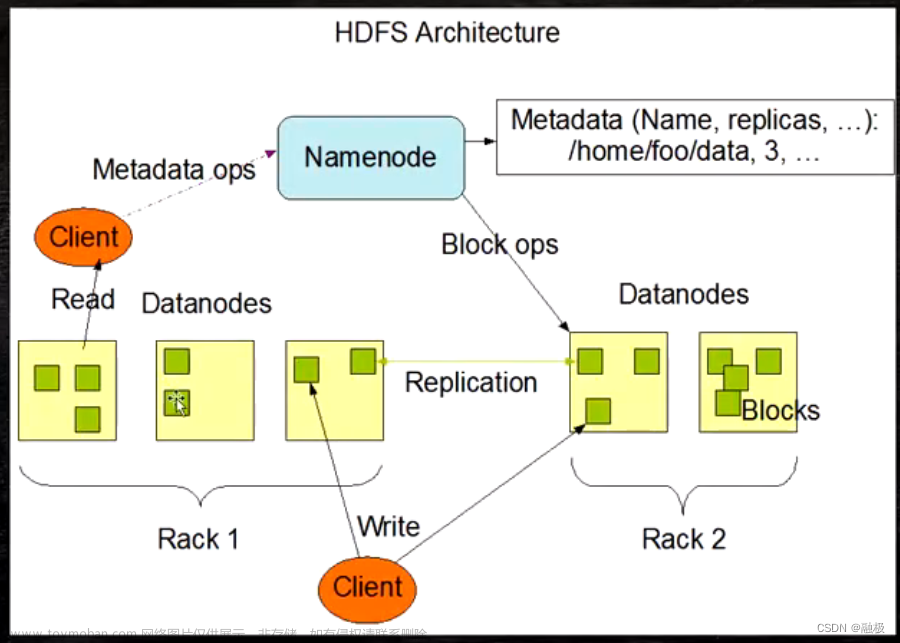
NameNode与DataNode
HDFS的构建思路是这样的:一次写入,多次读取,不可修改,这也是最高效的访问模式。
客户:你把1024台机器都组成了分布式文件系统,我要查数据,下载数据该怎么做呢?
程序猿:我准备了一套专门管理这些数据的工具,叫做namenode,您要查数据直接访问它就可以啦。
HDFS有两类节点用来管理集群的数据,即一个namenode(管理节点)和多个datanode(工作节点)。namenode管理文件系统的命名空间,它维护着系统数及整棵树内所有的文件和目录,这些信息以两个形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件,namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块的位置信息,因为这些信息会在系统启动时根据节点信息重建。
客户端(client)代表用户通过与namenode和datanode交互来访问整个系统。客户端提供一个类似POSIX(可移植操作系统界面)的文件系统结构,因此用户编程时无需知道namenode和datanode也可以实现功能。
datanode是文件系统的工作节点,他们根据需要存储并检索数据块(blocks),并且定期向namenode发送他们所存储的数据块的列表。

客户:听不懂,说人话!
程序猿:额,我们现在将咱们的大数据机房设想成一个大仓库,仓库很大,有一本账单记录着仓库所有货架的商品,每一个货架上都放了很多货物,不过这些货物有一个特点,即大小都一致,并且货架也有一个本货架的清单,记录着本货架的商品,每当货架中的货物有变动,这个清单也会一起变,并且还会记录在主清单中。 在这里,namenode就类似仓库的主账单(保存了所有货物的记录),datanode就像是货架的清单(保存了本货架的物品记录),每个货架上的每一个货物就是数据块,数据块的大小是固定的(默认是128M)。

HDFS的常用命令
接下来我们来了解一下一些常用的文件系统操作,例如:读取文件,新建目录,移动文件,删除数据,列出目录,等等。你可以在命令行中输入hadoop fs -help 命令读取每个命令的详细帮助文件。
现在请跟着我一起,在Linux环境下对Hadoop进行文件系统操作,来体验一下Hadoop的使用。
新建目录:
在本地和hadoop中分别创建文件夹:
本地创建目录:

hadoop创建目录:

上传文件至dfs:
切换到本地input目录下,创建文件并添加数据:hello hadoop。

将该文件上传至hadoop:使用hadoop fs -put <要上传的文件> <hdfs目录> 命令。

查看上传到HDFS的文件:

移动与删除
列出HDFS中的目录和文件:


将helloworld.txt移动到根目录;

删除helloworld.txt;

hadoop fs -rm 命令只能删除文件或者空文件夹,如果要用这个命令去删除非空文件夹就会非常麻烦。
和Linux中递归删除一致,我们在-rm之后加入一个-r即可,用-rmr也可。
下表列出了Hadoop常用的shell命令,在之后使用的时候可以作为参考。
| 选项名称 | 使用格式 | 含义 |
|---|---|---|
| -ls | -ls <路径> | 查看指定路径的当前目录结构 |
| -lsr | -lsr <路径> | 递归查看指定路径的目录结构 |
| -du | -du <路径> | 统计目录下个文件大小 |
| -dus | -dus <路径> | 汇总统计目录下文件(夹)大小 |
| -count | -count [-q] <路径> | 统计文件(夹)数量 |
| -mv | -mv <源路径> <目的路径> | 移动 |
| -cp | -cp <源路径> <目的路径> | 复制 |
| -rm | -rm [-skipTrash] <路径> | 删除文件/空白文件夹 |
| -rmr | -rmr [-skipTrash] <路径> | 递归删除 |
| -put | -put <多个 linux 上的文件> <hdfs 路径> | 上传文件 |
| -copyFromLocal | -copyFromLocal <多个 linux 上的文件><hdfs 路径> | 从本地复制 |
| -moveFromLocal | -moveFromLocal <多个 linux 上的文件><hdfs 路径> | 从本地移动 |
| -getmerge | -getmerge <源路径> <linux 路径> | 合并到本地 |
| -cat | -cat <hdfs 路径> | 查看文件内容 |
| -text | -text <hdfs 路径> | 查看文件内容 |
| -copyToLocal | -copyToLocal [-ignoreCrc] [-crc] [hdfs 源路径] [linux 目的路径] | 从HDFS复制到本地 |
| -moveToLocal | -moveToLocal [-crc] <hdfs 源路径> <linux目的路径> | 从HDFS移动到本地 |
| -mkdir | -mkdir <hdfs 路径> | 创建空白文件夹 |
| -setrep | -setrep [-R] [-w] <副本数> <路径> | 修改副本数量 |
| -touchz | -touchz <文件路径> | 创建空白文件 |
编程要求
在右侧命令行中启动Hadoop,进行如下操作。
- 在
HDFS中创建/usr/output/文件夹; - 在本地创建
hello.txt文件并添加内容:“HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。”; - 将
hello.txt上传至HDFS的/usr/output/目录下; - 删除
HDFS的/user/hadoop目录; - 将
Hadoop上的文件hello.txt从HDFS复制到本地/usr/local目录。
测试说明
平台会查看你本地的文件和HDFS的文件是否存在,如果存在,则会将其内容输出到控制台。
预期输出:
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。
答案代码
start-dfs.sh
hadoop fs -mkdir -p /usr/output
vim hello.txt
文件内容:
HDFS的块比磁盘的块大,其目的是为了最小化寻址开销。
hadoop fs -put hello.txt /usr/output
hadoop fs -rm -r /user/hadoop
hadoop fs -get /usr/output/hello.txt /usr/local
第2关:HDFS-JAVA接口之读取文件
任务描述
本关任务:使用HDFS的Java接口进行文件的读写。
相关知识
在本关和之后的关卡中,我们要深入探索Hadoop的FileSystem类,它是与Hadoop的某一文件系统进行交互的API。

为了完成本关任务,你需要学习并掌握:1.FileSystem对象的使用,2.FSDataInputSteam对象的使用。
如果你想要在windows下调试编写Hadoop程序,可以查看这篇帖子:在Windows下开发Hadoop程序
FileSystem对象
要从Hadoop文件系统中读取文件,最简单的办法是使用java.net.URL对象打开数据流,从中获取数据。不过这种方法一般要使用FsUrlStreamHandlerFactory实例调用setURLStreamHandlerFactory()方法。不过每个Java虚拟机只能调用一次这个方法,所以如果其他第三方程序声明了这个对象,那我们将无法使用了。 因为有时候我们不能在程序中设置URLStreamHandlerFactory实例,这个时候咱们就可以使用FileSystem API来打开一个输入流,进而对HDFS进行操作。
接下来我们通过一个实例来学习它的用法。
首先我们在本地创建一个文件,然后上传到HDFS以供测试。



接下来,我们使用FileSystem,查看咱们刚刚上传的文件。 代码如下:
public sattic void main(String[] args){
URI uri = URI.create("hdfs://localhost:9000/user/tmp/test.txt");
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(uri, config);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 2048, false);
} catch (Exception e) {
IOUtils.closeStream(in);
}
}
你可以直接在右侧命令行与代码文件中测试,点击评测可以查看代码运行效果。运行成功效果如下:

上文中,FileSystem是一个通用的文件系统API,FileSystem实例有下列几个静态工厂方法用来构造对象。
public static FileSystem get(Configuration conf)throws IOException
public static FileSystem get(URI uri,Configuration conf)throws IOException
public static FileSystem get(URI uri,Configuration conf,String user)throws IOException
Configuration对象封装了客户端或服务器的配置,通过设置配置文件读取类路径来实现(如:/etc/hadoop/core-site.xml)。
- 第一个方法返回的默认文件系统是在
core-site.xml中指定的,如果没有指定,就使用默认的文件系统。 - 第二个方法使用给定的
URI方案和权限来确定要使用的文件系统,如果给定URI中没有指定方案,则返回默认文件系统, - 第三个方法作为给定用户来返回文件系统,这个在安全方面来说非常重要。
FSDataInputStream对象
实际上,FileSystem对象中的open()方法返回的就是FSDataInputStream对象,而不是标准的java.io类对象。这个类是继承了java.io.DataInputStream的一个特殊类,并支持随机访问,由此可以从流的任意位置读取数据。
在有了FileSystem实例之后,我们调用open()函数来获取文件的输入流。
public FSDataInputStream open(Path p)throws IOException
public abst\fract FSDataInputStream open(Path f,int bufferSize)throws IOException
第一个方法使用默认的缓冲区大小为4KB。
了解了这些,我们在来回顾上文代码,就能更好的理解这些方法的作用了:

编程要求
在右侧代码编辑区中编写代码实现如下功能:
- 使用
FSDataInputStream获取HDFS的/user/hadoop/目录下的task.txt的文件内容,并输出,其中uri为hdfs://localhost:9000/user/hadoop/task.txt。
测试说明
点击评测,平台会通过脚本创建/user/hadoop/task.txt文件并添加相应内容,无需你自己创建,开启hadoop,编写代码点击评测即可。因为Hadoop环境非常消耗资源,所以你如果一段时间不在线,后台会销毁你的镜像,之前的数据会丢失(你的代码不会丢失),这个时候需要你重新启动Hadoop。
预期输出: WARN [main] - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 怕什么真理无穷,进一寸有一寸的欢喜。
第一行打印出来的是log4j的日志警告,可以忽略。
答案代码
package step2;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
public class FileSystemCat {
public static void main(String[] args) throws IOException {
//请在Begin-End之间添加你的代码,完成任务要求。
/********* Begin *********/
URI uri = URI.create("hdfs://localhost:9000/user/hadoop/task.txt");
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(uri, config);
InputStream in = null;
try {
in = fs.open(new Path(uri));
IOUtils.copyBytes(in, System.out, 2048, false);
} catch (Exception e) {
IOUtils.closeStream(in);
}
/********* End *********/
}
}
命令行
start-dfs.sh
第3关:HDFS-JAVA接口之上传文件
任务描述
本关任务:使用HDFSAPI上传文件至集群。
相关知识
为了完成本关任务,你需要掌握:FSDataInputStream对象如何使用。
FSDataOutputStream对象
我们知道在Java中要将数据输出到终端,需要文件输出流,HDFS的JavaAPI中也有类似的对象。 FileSystem类有一系列新建文件的方法,最简单的方法是给准备新建的文件制定一个path对象,然后返回一个用于写入数据的输出流:
public FSDataOutputStream create(Path p)throws IOException
该方法有很多重载方法,允许我们指定是否需要强制覆盖现有文件,文件备份数量,写入文件时所用缓冲区大小,文件块大小以及文件权限。
注意:
create()方法能够为需要写入且当前不存在的目录创建父目录,即就算传入的路径是不存在的,该方法也会为你创建一个目录,而不会报错。如果有时候我们并不希望它这么做,可以先用exists()方法先判断目录是否存在。
我们在写入数据的时候经常想要知道当前的进度,API也提供了一个Progressable用于传递回调接口,这样我们就可以很方便的将写入datanode的进度通知给应用了。
package org.apache.hadoop.util;
public interface Progressable{
public void progress();
}
接下来我们通过一个例子来体验FSDataOutputStream的用法:
还是一样我们先在本地创建一个文件,以供测试。


接下来编写代码:(可以直接在平台测试)

运行得到如下结果:


可以看到文件已经成功上传了。
编程要求
在右侧代码编辑区和命令行中,编写代码与脚本实现如下功能:
- 在
/develop/input/目录下创建hello.txt文件,并输入如下数据:迢迢牵牛星,皎皎河汉女。纤纤擢素手,札札弄机杼。终日不成章,泣涕零如雨。河汉清且浅,相去复几许?盈盈一水间,脉脉不得语。《迢迢牵牛星》 - 使用
FSDataOutputStream对象将文件上传至HDFS的/user/tmp/目录下,并打印进度。
测试说明
平台会运行你的java程序,并查看集群的文件将文件信息输出到控制台,第一行属于警告信息可以忽略。
预期输出:

答案代码
package step3;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.IOException;
import java.io.InputStream;
import java.net.URI;
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Progressable;
public class FileSystemUpload {
public static void main(String[] args) throws IOException {
//请在 Begin-End 之间添加代码,完成任务要求。
/********* Begin *********/
File localPath = new File("/develop/input/hello.txt");
String hdfsPath = "hdfs://localhost:9000/user/tmp/hello.txt";
// 获取输入流对象
InputStream in = new BufferedInputStream(new FileInputStream(localPath));
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(URI.create(hdfsPath),config);
// 待上传文件大小
long fileSize = localPath.length() > 65536 ? localPath.length() / 65536 : 1;
FSDataOutputStream out = fs.create(new Path(hdfsPath), new Progressable() {
// 方法在每次上传了64KB字节大小的文件之后会自动调用一次
long fileCount = 0;
public void progress() {
System.out.println("总进度"+ (fileCount / fileSize) * 100 + "%");
fileCount++;
}
});
//最后一个参数的意思是使用完之后是否关闭流
IOUtils.copyBytes(in, out, 2048, true);
/********* End *********/
}
}
命令行:
start-dfs.sh
mkdir -p /develop/input/
vim /develop/input/hello.txt
文件内容:
迢迢牵牛星,皎皎河汉女。
纤纤擢素手,札札弄机杼。
终日不成章,泣涕零如雨。
河汉清且浅,相去复几许?
盈盈一水间,脉脉不得语。
《迢迢牵牛星》
第4关:HDFS-JAVA接口之删除文件
任务描述
本关任务:删除HDFS中的文件和文件夹。
相关知识
为了完成本关任务,你需要掌握:1.如何使用API来删除文件,2.如何列出指定目录下的文件和文件夹。
列出文件
我们在开发或者维护系统时,经常会需要列出目录的内容,在HDFS的API中就提供了listStatus()方法来实现该功能。
public FileStatus[] listStatus(Path f)throws IOException
public FileStatus[] listStatus(Path f,PathFilter filter)throws IOException
public FileStatus listStatus(Path[] files)throws IOException
public FileStatus() listStatus(Path[] files,PathFilter filter)throws IOException
当传入参数是一个文件时,他会简单的转变成以数组方式返回长度为1的FileStatus对象,当传入参数是一个目录时,则返回0或多个FileStatus对象,表示此目录中包含的文件和目录。
接下来通过一个例子,来体验一下listStatus()方法的使用:

在命令行启动hadoop,编写代码,点击评测可以直接查看结果。

显示了hdfs根目录下的文件夹与user目录下的文件夹。
删除文件
使用FileSystem的delete()方法可以永久性删除文件或目录。
public boolean delete(Path f,boolean recursive)throws IOException
如果f是一个文件或者空目录,那么recursive的值可以忽略,当recursize的值为true,并且p是一个非空目录时,非空目录及其内容才会被删除(否则将会抛出IOException异常)。
接下来我们通过一个例子,来查看该方法如何使用。

编写代码,点击评测,可以看到如下结果:

可以看到/user/hadoop/目录已经被删除了。
编程要求
在右侧代码区填充代码,实现如下功能:
- 删除
HDFS的/user/hadoop/目录(空目录); - 删除
HDFS的/tmp/test/目录(非空目录); - 列出
HDFS根目录下所有的文件和文件夹; - 列出
HDFS下/tmp/的所有文件和文件夹。
测试说明
HDFS的文件夹在你点击评测是会通过脚本自动创建,不需要你自己创建哦,依照题意编写代码点击评测即可。
预期输出:
 文章来源:https://www.toymoban.com/news/detail-852249.html
文章来源:https://www.toymoban.com/news/detail-852249.html
答案代码
package step4;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
public class FileSystemDelete {
public static void main(String[] args) throws IOException {
//请在 Begin-End 之间添加代码,完成本关任务。
/********* Begin *********/
// HDFS 根目录
String uri = "hdfs://localhost:9000/";
String path1 = "hdfs://localhost:9000/tmp";
String path2 = "hdfs://localhost:9000/user/hadoop";
String path3 = "hdfs://localhost:9000/tmp/test";
Configuration config = new Configuration();
FileSystem fs = FileSystem.get(URI.create(uri),config);
fs.delete(new Path(path2),true);
fs.delete(new Path(path3),true);
// 构建要显示目录的数组
Path[] paths = {new Path(uri),new Path(path1)};
FileStatus[] status = fs.listStatus(paths);
Path[] listPaths = FileUtil.stat2Paths(status);
for (Path path : listPaths){
System.out.println(path);
}
/********* End *********/
}
}
命令行:文章来源地址https://www.toymoban.com/news/detail-852249.html
start-dfs.sh
到了这里,关于【头歌实训】分布式文件系统 HDFS的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!