好久没有写文章,今天刚好没啥事,就动手记录一下,好记性不如烂笔头!言归正传,我最近接到的一个工作任务大概内容是,有一张数据量在十万+级别的表,需要新增一个字段,并且要写入初始化值。
业务其实非常的简单,全部查询出来一个列表,然后用mybatis的updateBatch批量更新,其实在我的实践过程中也没什么问题,但是执行的效率是很低的,而且一旦数据量过大,如果机器配置不太行的话,很可能会直接OOM,如果在正式环境出现这个问题,那完犊子,准备删库跑路!
所以呢,我就想了一个比较保险但是比较低级的办法,每次查询出5000条数据,去做批量更新,确保内存不会溢出导致服务崩盘,这当然也是可以解决问题,但是就是修复数据需要执行很多次,显得比较愚蠢一点。
那么如何用比较方便,并且高效的方式来修复大数量的数据呢? 第一反应肯定是多线程啦,方案是:
1.查询出全部的数据(10万条)
2.对数据进行分批,每批5000条,
3.多线程同时处理多批数据
4.等待执行完成,返回成功
直接上核心代码吧,写一个通用的分批工具类,把一个List集合,拆分成多个小的List集合
/**
* 拆分集合
*
* @param <T> 泛型对象
* @param resList 需要拆分的集合
* @param subListLength 每个子集合的元素个数
* @return 返回拆分后的各个集合组成的列表
**/
public static <T> List<List<T>> splitList(List<T> resList, int subListLength) {
if (CollectionUtils.isEmpty(resList) || subListLength <= 0) {
return new ArrayList<>();
}
List<List<T>> ret = new ArrayList<>();
int size = resList.size();
if (size <= subListLength) {
// 数据量不足 subListLength 指定的大小
ret.add(resList);
} else {
int pre = size / subListLength;
int last = size % subListLength;
// 前面pre个集合,每个大小都是 subListLength 个元素
for (int i = 0; i < pre; i++) {
List<T> itemList = new ArrayList<>(subListLength);
for (int j = 0; j < subListLength; j++) {
itemList.add(resList.get(i * subListLength + j));
}
ret.add(itemList);
}
// last的进行处理
if (last > 0) {
List<T> itemList = new ArrayList<>(last);
for (int i = 0; i < last; i++) {
itemList.add(resList.get(pre * subListLength + i));
}
ret.add(itemList);
}
}
return ret;
}然后就是用多线程业务处理了,代码如下
public static void doThreadBusiness(List<String> totalList) {
Long startTime = System.currentTimeMillis();
System.out.println("本次更新任务开始");
System.out.println("本机CPU核心数:"+Runtime.getRuntime().availableProcessors());
List<String> updateList = new ArrayList();
// 初始化线程池, 参数一定要一定要一定要调好!!!!
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(10, 50,
4, TimeUnit.SECONDS, new ArrayBlockingQueue(10), new ThreadPoolExecutor.DiscardPolicy());
// 大集合拆分成N个小集合,然后用多线程去处理数据,确保不会因为数据量过大导致执行过慢
List<List<String>> splitNList = SplitListUtils.splitList(totalList, 5000);
// 记录单个任务的执行次数
CountDownLatch countDownLatch = new CountDownLatch(splitNList.size());
// 对拆分的集合进行批量处理, 先拆分的集合, 再多线程执行
for (List<String> singleList : splitNList) {
// 线程池执行
threadPool.execute(new Thread(new Runnable(){
@Override
public void run() {
//模拟执行时间
System.out.println("当前线程:"+Thread.currentThread().getName());
List<String> batchUpdateVipList = new ArrayList<>();
for (String str : singleList) {
//组装要执行的批量更新数据
batchUpdateVipList.add(str);
}
// 这里模拟执行数据库批量更新操作
System.out.println("本次批量更新数据量:"+ batchUpdateVipList.size());
// 任务个数 - 1, 直至为0时唤醒await()
countDownLatch.countDown();
}
}));
}
try {
// 让当前线程处于阻塞状态,直到锁存器计数为零
countDownLatch.await();
} catch (Exception e) {
System.out.println("系统出现异常");
}
Long endTime = System.currentTimeMillis();
Long useTime = endTime - startTime;
System.out.println("本次更新任务结束,共计用时"+useTime+"毫秒");
}代码很 简单一看就懂了,这里要说一下CountDownLatch的使用,其实开发中并不常用,但是面试却很常用,这里蛮写一下,我使用CountDownLatch来阻塞主线程,等待多线程执行完毕后,再继续主线程,返回更新的结果,这个场景其实很经常使用到。 如果不用CountDownLatch,主线程会马上返回,如果是数据量大的情况下,往往会执行蛮久的,但是结果秒返回,就会给人一种错觉。
CountDownLatch countDownLatch = new CountDownLatch(splitNList.size());在线程执行完毕后,需要调用一下countDown,
// 任务个数 - 1, 直至为0时唤醒await()
countDownLatch.countDown();在主线程用await()进行阻塞等待,这样主线程就会一直等到所有的子线程都执行完成了,继续执行主线程的后续代码
countDownLatch.await();其实这里面还有一个非常重要的面试点,就是多线程的七大参数如何设置,
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(10,
50,
4,
TimeUnit.SECONDS,
new ArrayBlockingQueue(10),
new ThreadPoolExecutor.DiscardPolicy()
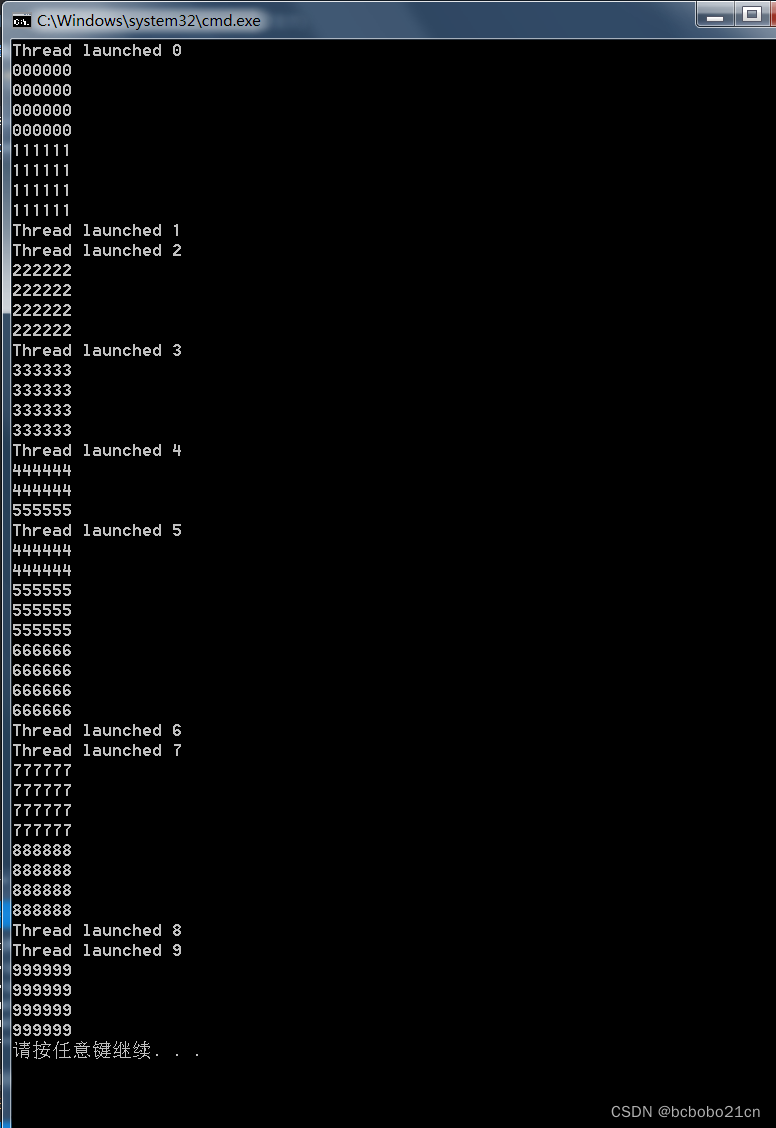
);有兴趣了解具体是设置方法可以另行查询资料,这也是面试必问的考点。最后贴一下返回的打印结果吧,如下图所示:文章来源:https://www.toymoban.com/news/detail-852415.html
 文章来源地址https://www.toymoban.com/news/detail-852415.html
文章来源地址https://www.toymoban.com/news/detail-852415.html
到了这里,关于java 多线程批量更新10万级的数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!