1.背景介绍
机器翻译是人工智能领域的一个重要研究方向,其目标是让计算机能够自动地将一种自然语言翻译成另一种自然语言。随着大数据时代的到来,机器翻译面临着巨大的数据挑战。这篇文章将从数据清洗和处理的角度探讨机器翻译的大数据挑战。
1.1 机器翻译的重要性
机器翻译具有广泛的应用,例如新闻报道、文学作品、商业交流等。随着全球化的推进,人们在交流中越来越多地使用不同的语言。这使得机器翻译成为了一种必要的工具,以便更快地传递信息和理解不同文化之间的意图。
1.2 大数据对机器翻译的影响
随着互联网的普及和数据的产生量的增加,人类生活中的各种语言数据都在急速增长。这为机器翻译提供了巨大的数据源,但同时也带来了大量的数据处理和清洗挑战。这些挑战包括但不限于:
- 数据质量问题:大量的低质量数据可能导致机器翻译的准确性下降。
- 数据量过大:大量的数据需要更高效的处理和存储方法。
- 多语言数据处理:需要处理多种语言的数据,这需要更复杂的数据清洗和处理方法。
因此,在解决机器翻译问题的同时,还需要关注大数据处理和清洗的问题。
2.核心概念与联系
2.1 机器翻译的核心概念
机器翻译主要包括 Statistical Machine Translation (统计机器翻译) 和 Neural Machine Translation (神经机器翻译) 两大类。
2.1.1 统计机器翻译
统计机器翻译是根据语言数据中的统计规律来进行翻译的。它主要包括:
- 词汇对应:找到源语言单词的目标语言对应词。
- 句子结构:根据源语言句子的结构来构建目标语言句子。
2.1.2 神经机器翻译
神经机器翻译是利用深度学习技术来进行翻译的。它主要包括:
- 编码器-解码器架构:将源语言句子编码成向量,然后解码为目标语言句子。
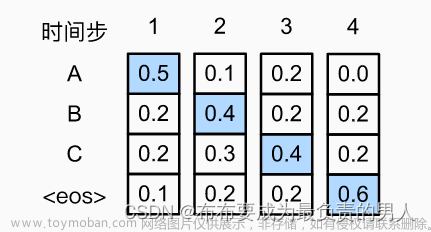
- 注意力机制:在解码过程中,根据源语言句子的不同部分来调整目标语言句子的生成。
2.2 数据清洗与处理的核心概念
数据清洗与处理是指对原始数据进行预处理、清洗、转换等操作,以便为后续的机器翻译算法提供高质量的数据。核心概念包括:
- 数据预处理:对原始数据进行清洗、去重、格式转换等操作,以便于后续使用。
- 数据清洗:对原始数据进行噪声去除、缺失值处理、标准化等操作,以提高数据质量。
- 数据转换:将原始数据转换为机器可理解的格式,如向量化、编码等。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 统计机器翻译的核心算法
3.1.1 词汇对应
词汇对应是通过统计源语言单词和目标语言单词之间的出现频率来实现的。具体操作步骤如下:
- 统计源语言单词和目标语言单词的出现频率。
- 根据出现频率找到源语言单词的目标语言对应词。
3.1.2 句子结构
句子结构是通过统计源语言句子和目标语言句子之间的语法关系来实现的。具体操作步骤如下:
- 将源语言句子拆分为单词序列。
- 将目标语言句子拆分为单词序列。
- 根据语法规则将源语言单词序列映射到目标语言单词序列。
3.1.3 贝叶斯定理
贝叶斯定理是统计机器翻译中的一个核心概念,用于计算概率。具体公式如下:文章来源:https://www.toymoban.com/news/detail-852426.html
P ( A ∣ B ) = P ( B ∣ A ) × P ( A ) P ( B ) P(A|B) = \frac{P(B|A) \times P(A)}{P(B)} P(A∣B)=P(B)P(B文章来源地址https://www.toymoban.com/news/detail-852426.html
到了这里,关于机器翻译的大数据挑战:数据清洗与处理的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!