前言
在信息时代,网络爬虫技术作为获取和处理网络数据的重要手段,已经成为数据科学、机器学习和许多商业应用的基石。从简单的HTML页面抓取到复杂的动态内容采集,爬虫技术经历了迅速的发展。本文将探索当前最新的爬虫技术,以及为有志于此领域的学习者提供一个清晰的学习路径。
爬虫技术的演进
早期的网络爬虫主要关注于静态网页的内容抓取,利用HTTP请求获取网页,然后通过正则表达式或HTML解析器提取所需数据。随着网络技术的进步,许多网站开始采用AJAX和JavaScript动态加载数据,这对爬虫技术提出了新的挑战。
为应对这一挑战,出现了基于浏览器自动化的爬虫技术,如Selenium和Puppeteer等工具。这些工具能模拟用户在浏览器中的行为,获取由JavaScript动态生成的内容,有效地解决了传统爬虫在处理动态网站时的局限性。
近年来,随着人工智能的发展,更加智能化的爬虫技术开始涌现。例如,使用机器学习算法自动识别和提取网页中的关键信息,或者利用自然语言处理技术理解和抽取网页文本的具体内容。此外,分布式爬虫系统的设计也使得大规模的网络数据抓取成为可能,极大地提高了爬虫的效率和效果。
最新的爬虫技术
Headless Chrome 和 Puppeteer: Headless Chrome 是 Chrome 浏览器的无界面版本,配合 Puppeteer 这样的库,可以实现对动态网页的高效抓取。
Scrapy与Scrapy-Redis: Scrapy是一个快速、高层次的屏幕抓取和网页抓取框架,而Scrapy-Redis则为Scrapy提供了Redis分布式组件,支持大规模爬取任务。
机器学习与自然语言处理: 利用机器学习模型对抓取的内容进行分类、摘要生成等预处理,使得数据更加适合后续的分析和应用。
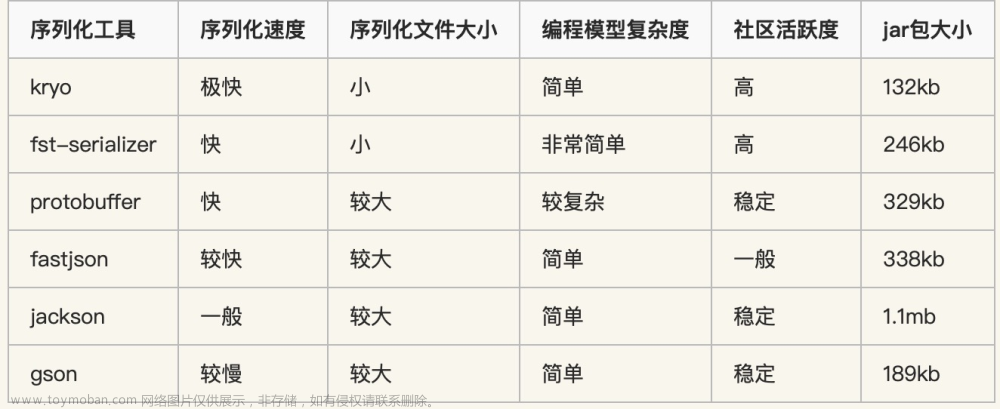
API抓取与GraphQL: 随着更多的web应用提供API接口,通过API抓取数据成为了一种高效的方式。GraphQL作为一种API查询语言,允许用户精确指定所需数据,提高了数据抓取的效率和准确性。
爬虫技术学习路线
基础知识: 学习HTML、CSS和JavaScript的基础知识,了解网页的结构和动态内容生成机制。
初级爬虫技术: 学习使用Python的requests库进行简单的HTTP请求,以及BeautifulSoup或lxml库进行网页内容的解析。
高级爬虫技术: 学习使用Selenium或Puppeteer进行动态网页抓取,掌握Scrapy框架进行高效的数据爬取和处理。
分布式爬虫与数据处理: 了解分布式爬虫的设计和实现,学习使用数据库和数据处理工具(如Pandas)对抓取的数据进行存储和初步分析。
进阶技术学习: 根据个人兴趣深入学习机器学习、自然语言处理等技术,提高爬虫的智能化水平。
实战项目: 参与或自行开发实战项目,如数据抓取、内容监测、市场分析等,以实际操作巩固所学知识并积累经验。文章来源:https://www.toymoban.com/news/detail-852486.html
通过上述学习路线,有志于深入网络爬虫领域的学习者可以逐步建立起自己的知识体系,并在实践中不断提高自己的技术能力。网络爬虫技术的发展仍在继续,保持学习的热情和适应新技术的能力是进入这一领域的关键。文章来源地址https://www.toymoban.com/news/detail-852486.html
到了这里,关于探索网络爬虫:技术演进与学习之路的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!