本节重点
• 理解传输层的作⽤,深⼊理解TCP的各项特性和机制
• 对整个TCP/IP协议有系统的理解
• 对TCP/IP协议体系下的其他重要协议和技术有⼀定的了解
1.应用层
我们之前编写完了基本的 java socket ,要知道,我们之前所写的所有代码都在应⽤层,都是为了
完成某项业务,如翻译等。关于应⽤层,我们在讲解完毕基本的 TCP/IP 协议之后,我们会单独来进⾏讲解(详情可见上篇文章)
2.传输层
负责数据能够从发送端传输接收端
.2.1再谈端⼝号
端⼝号(Port)标识了⼀个主机上进⾏通信的不同的应⽤程序;
在TCP/IP协议中,⽤"源IP","源端⼝号","⽬的IP","⽬的端⼝号","协议号"这样⼀个五元组来标识⼀个
通信(可以通过netstat-n查看);
端⼝号范围划分
• 0-1023:知名端⼝号,HTTP,FTP,SSH等这些⼴为使⽤的应⽤层协议,他们的端⼝号都是固定的.

• 1024-65535:操作系统动态分配的端⼝号.客⼾端程序的端⼝号,就是由操作系统从这个范围分配
的.

认识知名端⼝号(Well-Know Port Number)
有些服务器是⾮常常⽤的,为了使⽤⽅便,⼈们约定⼀些常⽤的服务器,都是⽤以下这些固定的端⼝号:
• ssh服务器,使⽤22端⼝
• ftp服务器,使⽤21端⼝
• telnet服务器,使⽤23端⼝
• http服务器,使⽤80端⼝
• https服务器,使⽤443
我们⾃⼰写⼀个程序使⽤端⼝号时,要避开这些知名端⼝号.
两个问题
1. ⼀个进程是否可以bind多个端⼝号. // 可以
2. ⼀个端⼝号是否可以被多个进程bind. //不可以
2.2UDP协议
UDP协议端格式

• 16位UDP⻓度,表⽰整个数据报(UDP⾸部+UDP数据)的最⼤⻓度;
• 如果校验和出错,就会直接丢弃;( 因为数据传输过程中,是二进制传输,有可能1变成0,也有可能0变成1(比特翻转),所以就需要校验,但是校验并不能百分百,因为udp的校验机制,并不能完全避免,比如如果一个1变成了0,一个0变成了1.通过udp的校验机制,这个结果就会判定为数据没有改变,这个是漏洞)

除了CRC校验以外,还有一些精准更高的(例如md5/sha1);
这个东西的背后涉及一系列的公式计算,不再是像CRC一个公式的计算,无论是多长的原始数据,算出来的结果 都是一样的长度.常见的md5有16位(2字节),32位(4字节),64位(8字节).
尽管只是变了1比特,但是通过计算,变化也是非常大.并且,如果给一个源字符串很容易计算结果,但是如果给一个结果,就很难算出源字符串.保密性很高,有时也会被当成加密使用
我们都说UDP数据能放64kb数据,其实是64kb-8字节.但是由于8字节太小,所以我们忽略了
UDP的特点
UDP传输的过程类似于寄信.
• ⽆连接:知道对端的IP和端⼝号就直接进⾏传输,不需要建⽴连接;
• 不可靠:没有确认机制,没有重传机制;如果因为⽹络故障该段⽆法发到对⽅,UDP协议层也不会给应⽤层返回任何错误信息;
• ⾯向数据报:不能够灵活的控制读写数据的次数和数量;
理解UDP的"不可靠"
⾯向数据报
应⽤层交给UDP多⻓的报⽂,UDP原样发送,既不会拆分,也不会合并;
⽤UDP传输100个字节的数据:
• 如果发送端调⽤⼀次sendto,发送100个字节,那么接收端也必须调⽤对应的⼀次recvfrom,接收100个字节;⽽不能循环调⽤10次recvfrom,每次接收10个字节;
UDP使⽤注意事项
我们注意到,UDP协议⾸部中有⼀个16位的最⼤⻓度.也就是说⼀个UDP能传输的数据最⼤⻓度是
64K(包含UDP⾸部).
然⽽64K在当今的互联⽹环境下,是⼀个⾮常⼩的数字.
如果我们需要传输的数据超过64K,就需要在应⽤层⼿动的分包,多次发送,并在接收端⼿动拼装;
2.3TCP协议
TCP全称为"传输控制协议(Transmission Control Protocol").⼈如其名,要对数据的传输进⾏⼀个详细的控制;
TCP协议段格式

保留位4bit,15个数字,这里的数字的单位是字节,不是bit.所以头部长度是4*15字节=60字节.
这里 不像UDP报头是8字节固定的.TCP只有前面20个字节是固定的,保留位置(由于UDP受到了2比特位的限制,不能扩大,所以TCp就涨了心眼,所以,就设置了保留位,用的时候直接用,不用的时候直接不用就好,这样就可以避免到时候扩展不兼容的问题)
• 源/⽬的端⼝号:表⽰数据是从哪个进程来,到哪个进程去;
• 32位序号/32位确认号:下面会详细介绍
• 4位TCP报头⻓度:表⽰该TCP头部有4位bit(有多少个4字节);所以TCP头部最⼤⻓度是15*4=60
• 6位标志位:;
URG:紧急指针是否有效
ACK:确认号是否有效
PSH:提⽰接收端应⽤程序⽴刻从TCP缓冲区把数据读⾛
RST:对⽅要求重新建⽴连接;我们把携带RST标识的称为复位报⽂段
SYN:请求建⽴连接;我们把携带SYN标识的称为同步报⽂段
FIN:通知对⽅,本端要关闭了,我们称携带FIN标识的为结束报⽂段
• 16位窗⼝⼤⼩:下面会有详细介绍
• 16位校验和:发送端填充,CRC校验.接收端校验不通过,则认为数据有问题.此处的检验和不光包
TCP⾸部,也包含TCP数据部分.
• 16位紧急指针:标识哪部分数据是紧急数据;
• 40字节头部选项:选项部分可以有一个,或者多个,也可以一个也没有
确认应答
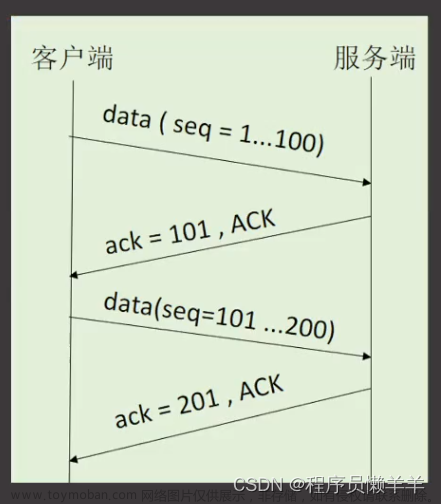
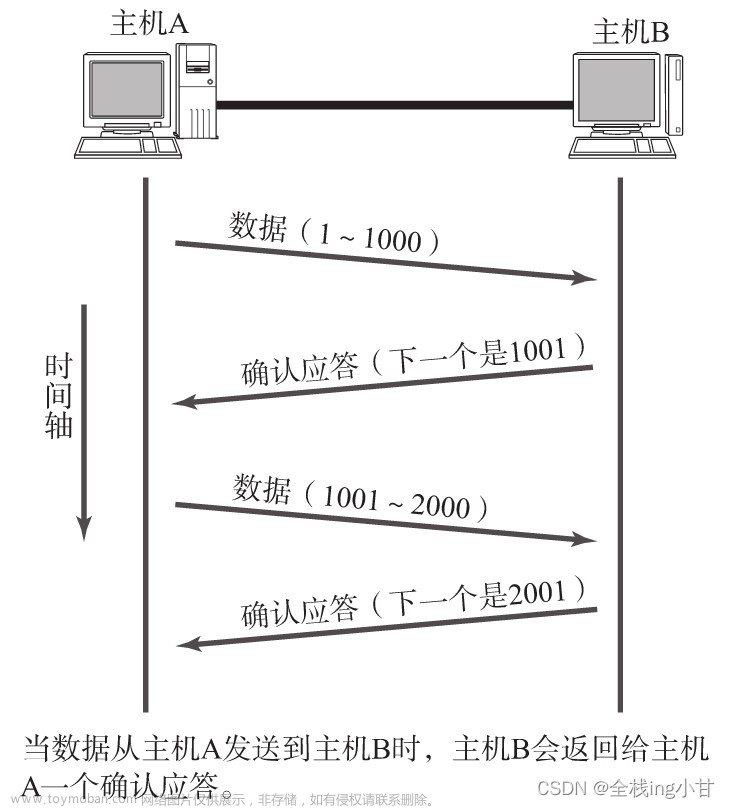
TCP最重要的就是可靠传输,怎么才能算可靠传输呢?
你发信息过来,我回你信息说收到了,意味着就是真的收到了

例如:

我发送信息过去的时候,我也不知道对方收到了没有,但是如果对方给我回消息说收到,那我就知道对方收到了(已读不回不算哈哈哈哈哈啊哈哈啊哈)

但是如果有多条消息呢??
女神的本意是这样的
可是我们知道网络是经过多地方传输的,会出现后发先到的情况(就好像我们导航到一个地方有很多方法和路线,每条路线的情况都不相同,所以时间是不可预测的)就会出现下面这种情况

可是女神本意不是这样的,所以我们应该怎么避免这种问题呢??
为了解决这个问题,我们就引入了序号和确认序号.在应答的报文里面就会说我这次应答的 是哪个数据.




大家可能有疑问,发送一次,传回一次,才会继续发送.那女神刚刚那样的情况是给女神发送了多次,为什么会出现这种情况呢??是因为网络条件复杂,断电等等都有可能,我们为了确保每次都能正确,所以引入确认序号
这里总结一下:TCP的可靠传输是因为有这样的应答机制,不是因为"三次握手",网上有些说是因为"三次握手"所以才可靠是错误的."等下会说三次握手"
应答报文中,通过应答告诉 发送方表示我收到了.称为"ack",全称acknowledge的缩写.

超时重传
超时重传是应答报文的补充

如果传输一切顺利,发送方的数据正常传给接收方,接收方就可以发送ack报文给发送方表示 收到.可是网络传输会有丢"丢包"的行为
这种时候就需要重新传输了.
TCP的可靠性就是表现在这种时候,及时丢包了,就可以重新发送,让接收方仍然能够接收到数据.
这个就不是UDP能都走到的.UDP即没有接收应答也没有重新发送.数据怎么样了都不知道.
发送方发了数据后就会等一下(有上限的,不是傻等),如果没有收到ack就会认为"丢包",然后就会重新发送.
(上面的说法有一点点错误,不止是发送的数据会丢,发送回来的ack也会丢,但是总的不变,只要发送方没有收到ack,就当做是发送的数据丢了)

如何解决这个问题呢??
TCP在内核中有一片缓存区,发送方的数据都需要放到缓冲区,然后应用的时候通过read和Scanner.next都是通过缓冲区读取数据.
1.数据还在缓冲区里,没有被读走
拿新收到的数据的序列拿出来和已有的序列比一比,如果一样的就会被丢弃
2.数据在缓冲区里,已经被读走了
此时序列不能直接在缓冲区里读到,可是缓冲区里的序号是按照顺序排列的1-1000,2-2000,3-3000.....(可以把缓冲区想象成阻塞的缓存队列),此时 scock 的api就会记录最后一个被read走的序列号,如果是3000,就代表之前的都被读走了,所以新到的这个1000肯定是重复的,就被丢弃了
上面谈到的ack的重传,保证顺序,还有去重.都是ack内置的,我们使用TCP的api的时候,我们只需要调用一下outputStream.write()这个方法就好了,省了我们很多时间(当然正确的使用他们的前提得是我们需要真正的了解他们)
如果我们使用UDP就需要我们自己好好斟酌了
超时重传是会重传.但是怎么重传呢??
1.重传是有上限的,如果超出长限,就会重置连接,如果重置失败,就会直接放弃.
2.重传的时间间隔也是有说法的,随着重传的次数的增大,重传的间隔时间越久(频率就会变低)
连接管理(三次握手,四次挥手)
建立连接,断开连接

内核是怎么建立上诉的连接的 呢??
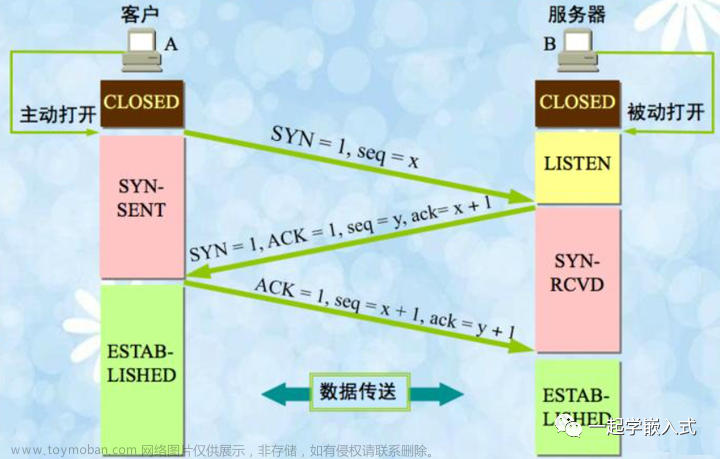
三次握手




客户端是主动的一方,第一次交互,一定是客户端主动发起的.
所谓的syn是一个特殊的TCP数据报
1.没有载荷,不会携带应用层数据
2.六个标志位中 的第五位,为1

虽然syn不带有应用层载荷,但是也是会有IP报头/以太网数据帧头..更会有TCP报头.
TCP报头就包含了客户端自己的端口.IP报头就包含了客户端自己的IP.(这个过程也是客户端在告诉服务器,我是谁)
但是接下来就有两种可能性:
1.服务器同意了,服务器表示我也愿意和你建立连接
2.服务器没同意(一般来说这种情况很少见,就是出现服务器负载极高的情况下,服务器无法响应了,客户端太多了)就没有下文了.
只要服务器有空闲都会得到一个肯定的响应!!
服务器收到syn之后,会返回ack(确认应答),语义:收到
接下俩服务器还会返回syn,这个syn的意思就是我接受你的连接,我也愿意和你建立连接.
虽然都是叫做同步,实际上是不同的含义.同一个术语在不同的语境下面有不同的意思
握手过程中,确认应答/超时重传也会存在.

为啥要握手??意义是什么?
1.三次握手,可以先针对通讯路径进行探路,初步确认通信链路是否畅通(可靠性的条件)
2.三次握手,也是在验证双方通信,发送能力和接受能力是否正常(一定要是两端都没问题)

至于四次握手可以吗?两次握手可以吗?
四次握手(可以但没必要)
两次握手(不可以)
如果少了最后一次握手,服务器并不知道自己的发送是否完好,因为客户端收到了服务器的请求,但是并没有告诉服务器,服务器会认为自己的发送是坏的.
TCP中也是有很多参数需要进行协商,往往是以"选项"部分来体现

序号和确认序号的作用
不仅仅是确认顺序,还可以确认是不是同一次建立的连接中发送的信息

第一次连接的时候,传输的数据有一个在路上堵车了,等到终于到了的时候,已经改朝换代了,老的连接已经荒废,现在是新的连接,此时,这份数据就该丢掉,但是数据报是按照ip+端口进行识别的,第一个连接,是用客户端A来连接,第二个连接还是是用客户端A来连接的,服务器两次都是B(恰好是同一个端口的话,客户端概率比较小,但是服务器这方面概率还是挺大的)
如何识别是不是前朝的数据呢?这里就需要序列来区分,即使有时丢包,但是序号差别不大,但是如果是别的朝代的包,序列差别很大,一眼就看的出来.(序号不是随机的,背后有一套序号分配机制)
四次挥手


scock.close()触发fin数据报
通信双方各自给对方发送fin,再各自给对方返回syn表示和平分开
那既然四次挥手和三次握手这么像,三次握手也是合并才成为三次的,那四次挥手可不可以也成为三次挥手呢??
答案是:有时候能合并,有时候不能合并.不像三次握手是100%.四次挥手只是有可能.所以不能称为三次挥手.

如果实际通信中,第一个ack和第二个fin间隔时间比较长,那就不可以合并了.就需要分成两次来运输
如果当前时间间隔比较小,是有可能合并.TCP还有延时应答和捎带应答.(下面会一一到来)

状态转换

TCP的状态和"线程"的状态的概念有点类似
TCP服务器和客户端都有数据结构来保存这个连接的信息,在这个数据结构中就有一个属性叫做"状态",操作系统根据目前的状态,就知道要做什么,就不会混乱.

我们只需要记住几个重要的状态,其余的需要的时候再查即可

LISTEN状态表示服务器这边ServerScock已经建立完毕,并且端口号已经写好了(比如:我手机已经开机好了,随时可以给我打电话了)

ESTABLISHED已确立的,客户端和服务器已经建立联系(三次握手完了)(比如:有人打电话给我,我接通了,我们可以正式通话了)

CLOSE_WAIT状态表示接下来的代码需要调用close(),来发送fin给对方.(收到对方的fin进入这个状态)
TIME_WAIT状态表示,本端先发用fin,对方也给我发了fin后,此时本端进入TIME_WAIT状态,给最后一个ack重传留有时间

TIME_WAIT的意义是:防止ack丢包

TIME_WAIT也不是无休止等待,而是有时间限制的.
滑动窗口(TCP非常有特色的)
由于TCP的可靠运输,超时重传,确认应答,耗费了太多的时间.所以TCP就引入了滑动窗口.

在应答机制下,每次发送方接收到了ack以后才会发送下一个数据,导致大量的时间都浪费在了ack上面了,希望在保证可靠传输的情况下,可以节约一点等待时间的花费.
滑动窗口就是为了解决上诉的这些问题,滑动窗口解决的是时间的损耗,节约等待的时间,而不是发送的速度.(虽然这个机制还是没有UDP这种不可靠传输的快,但是也是比啥都不做要好)


上诉发送和返回ack都很快,所以就像一个滑动的窗口,一直往后面滑动.
滑动窗口要确保可靠性,可是如果ack丢了,或者是数据在路上丢了,没有传过去怎么办呢?
1.ack丢了

2.数据丢了

解决这个问题的关键在于:这里返回的是ack是1001.而不是3001.说明1001-2000这个数据是丢了的.不然就是返回3001了.所以主机B就会发送三次重复的确认应答给主机A.主机A收到了同样的应答之后就知道是丢了哪里的数据,就会进行重发.主机B收到了1001-2000的数据后.就会直接返回ack7001,因为这些数据早早的就已经到位了.只是由于2000的数据丢了,所以ack一直发不出去.当2000这个数据到了的时候.就代表着都有了.就会直接返回7001.
在上诉重传的时候.总体的效率是非常高的.这里的重传是针对性的重传.丢了哪一个就传哪一个
如果同时丢了1001和2001.主机B就是返回1001.然后就按照刚刚的逻辑继续走.等到1001的数据重新发送以后.主机B收到了.就会发送2001这个ack三次.

确认应答-超时重传 ======== 滑动窗口-快速重传 并不是冲突的.而是同时存在的
1.如果当前传输是按照滑动窗口来传输(短时间内传输大量的数据),就按照快速重传来保证可靠性,判断丢包的条件就是返回多次一样的ack
2.如果当前传输不是按照滑动窗口(没有传输很多数据),就按照超时重传来保证可靠性,此时丢包的判定就是超过规定时间,还没有收到ack.
滑动窗口也有确认应答,只是是稍作调整,批量的确认应答,批量的前提是短时间有很多数据,如果没有很多数据,窗口滑动不起来,也就会退化成确认应答.
流量控制(流控)
通过滑动窗口提高效率,窗口大小越大,更多的数据复用同一块空间等待,效率就越高(批量传数据,不需要等待ack,此时数据的量就是窗口的大小).
窗口的大小能无限大吗?当然不能,提升效率的前提是不影响TCP的可靠性
发送的速度不能无限大,这时候就需要考虑一些情况,从而保证可靠性.
如果你发送太快,接收方方处理不过来,此时就会丢包.(缓冲区满了.应用层read读取速度跟不上)
很明显,如果此时缓冲区满了,丢包了,就算重传也没用,反而会浪费硬件资源.
与其等到接收方满了你不发,不如你提前感知到快满了,就减慢速度.让发送方的发送速度和接受方的接收速度能步调一致.就是让接受方 的速度反过来影响发送方的速度.(这个就叫流量控制)

TCP的窗口中还包含了一个参数,叫做扩展因子,实际上.要设置的窗口大小为16位窗口大小 * 2 ^ 窗口因子

拥塞控制
拥塞控制是站在发送方角度限制发送方发送的速度
流量控制是站在接收方的角度来制约发送方速度的.


就有了以下的综合的合理的方法;


延时应答
也是基于滑动窗口,尽可能再提高一点效率,结合滑动窗口,以及流量控制,把反馈的窗口搞大一些

举个例子:


捎带应答
基于延时应答引出的,能够提升传输效率的 机制
修改窗口大小确实是提升速度的机制,捎带应答就是另外一种机制.
尽可能把能合并打包一起带走的打包在一起,从而提高效率

ack延时的这段时间里,刚好响应的数据包也准备好了,此时就可以把ack和应答的数据放在一个tcp数据报里.一起发送,


面向字节流
此处重点讨论字节流中一个非常重要的问题 "粘包问题"
此处的包是TCP载荷中的数据包.
在tcp传输到了接收方以后,接收方通过read的的,叫做应用层数据包,由于整个read非常灵活,不知道从哪到哪是一个完整的数据包





粘包问题是tcp引起的.但是需要程序员自己去解决(写应用底层逻辑的时候)
异常情况





3.网络层
3.1 IP协议
3.1.1 地址管理

基本概念
• 主机:配有IP地址,但是不进⾏路由控制的设备;
• 路由器:即配有IP地址,⼜能进⾏路由控制;
• 节点:主机和路由器的统称;
协议头格式

• 4位版本号(version):指定IP协议的版本,对于IPv4来说,就是4.
• 4位头部⻓度(header length):IP头部的⻓度是多少个32bit,也就是length*4的字节数.4bit表⽰最⼤的数字是15,因此IP头部最⼤⻓度是60字节.
• 8位服务类型(Type Of Service):3位优先权字段(已经弃⽤),4位TOS字段,和1位保留字段(必须置为0).4位TOS分别表⽰:最⼩延时,最⼤吞吐量,最⾼可靠性,最⼩成本.这四者相互冲突,只能选择⼀个.
对于ssh/telnet这样的应⽤程序,最⼩延时⽐较重要;对于ftp这样的程序,最⼤吞吐量⽐较重要.

• 16位总⻓度(total length):IP数据报整体占多少个字节.

• 16位标识(id):唯⼀的标识主机发送的报⽂.如果IP报⽂在数据链路层被分⽚了,那么每⼀个⽚⾥⾯的这个id都是相同的.

• 3位标志字段:第⼀位保留(保留的意思是现在不⽤,但是还没想好说不定以后要⽤到).第⼆位置为1表⽰禁⽌分⽚,这时候如果报⽂⻓度超过MTU,IP模块就会丢弃报⽂.第三位表⽰"更多分⽚",如果分⽚了的话,最后⼀个分⽚置为1,其他是0.类似于⼀个结束标记.
• 13位分⽚偏移(framegament offset):是分⽚相对于原始IP报⽂开始处的偏移.其实就是在表⽰当前分⽚在原报⽂中处在哪个位置.实际偏移的字节数是这个值*8得到的.因此,除了最后⼀个报⽂之外,其他报⽂的⻓度必须是8的整数倍(否则报⽂就不连续了).

• 8位⽣存时间(Time To Live, TTL):数据报到达⽬的地的最⼤报⽂跳数.⼀般是64.每次经过⼀个路由,TTL-=1,⼀直减到0还没到达,那么就丢弃了.这个字段主要是⽤来防⽌出现路由循环

• 8位协议:表⽰上层协议的类型

• 16位头部校验和:使⽤CRC进⾏校验,来鉴别头部是否损坏.

• 32位源地址和32位⽬标地址:表⽰发送端和接收端.

• 选项字段(不定⻓,最多40字节):略



要求公网上的设备,对应的公网IP,都必须是唯一的.
但是私网上的设备,使用私网Ip,只要确保局域网内部IP不重复即可,不同的局域网IP允许重复
由于上述设定,就有一个重要的限制:
1.公网设备访问公网设备, 没有任何问题,直接访问即可
2.局域网设备访问局域网设备(同一个局域网中),也没有任何问题,
3.局域网设备访问局域网设备(不同局域网中),不允许访问.
4.局域网设备访问公网设备就需要对局域网设备的 IP 进行 地址转换
5.公网设备访问局域网设备,不允许主动访问




如果刚好这两个设备的端口又都一样呢??就是这么凑齐
此时路由器就会对端口进行映射

由于在路由器局部IP要转换成公网IP,所以这个时候,如果刚好同一个局部网内的设备访问同一个网址,并且,设备都是相同的端口号,就会一样,所以就需要不同的端口号来区分





广播信息都是UDP,因为TCP不支持
3.1.2 路由选择

4.数据链路层
以太网(横跨数据链路层和物理层)






上面内容介绍完毕,再来介绍一下DNS


制作不易,太多细节和核心需要解剖了.
有收获的朋友不妨一键三连!!!!文章来源:https://www.toymoban.com/news/detail-852532.html
---------------------------------------------------------------------------------------------------------------------------------文章来源地址https://www.toymoban.com/news/detail-852532.html
到了这里,关于网路原理-传输层UDP,TCP/IP(确认应答,超时重传,连接管理,三次握手,四次挥手,状态转换,流量控制,滑动窗口,拥塞控制,延时应答,捎带应答,异常情况,面向字节流)-网络层(IP协议,地址管理)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!