👂 夏风 - Gifty - 单曲 - 网易云音乐
目录
🌼前言
🎂面试题(下)
4)HTTP报文解析
为什么要用状态机
状态转移图画一下
https 协议为什么安全
https 的 ssl 连接过程
GET 和 POST 的区别
5)数据库注册登录
登录说一下
用户名/密码,保存状态了吗?如果要保存,如何做(cookie && session)
10 亿条用户名和密码 load 到本地然后 hash 匹配,依然很耗时,如何优化?
项目用的是 mysql,那么了解过 redis 吗,用过吗
6)定时器
为什么要用定时器
定时器工作原理
双向 list,删除和插入的时间复杂度,如何优化
最小堆优化?说说时间复杂度和原理
跳表优化?说一下时间复杂度和原理
7)日志系统
说下日志系统运行机制
为什么要异步,和同步区别是
现在你要监控服务器状态,输出监控日志,那么日志如何分发到不同机器?(消息队列)
8)压力测试
并发量如何测试
webbench 是什么,原理是
测试时遇到的问题
Web 服务器 QPS 到达瓶颈,一直上不去,怎么办
9)综合能力
项目亮点是(区别于同类项目)
前端发送请求后,服务器处理过程涉及的协议
🌼前言
另外 2 篇
WebServer -- 架构图 && 面试题(上)-CSDN博客
WebServer -- 八股(终章)-CSDN博客
Github 地址
11days/TinyWebServer: TinyWebServer一百小时 (github.com)
🎂面试题(下)
4)HTTP报文解析
为什么要用状态机
19
- 它是一种抽象的理论模型,将有限个变量描述的状态变化过程,以可构造可验证的方式呈现出来
- 比如封闭的有向图
- 通过 if-else, switch-case 和 函数指针 实现
- 目的是封装逻辑
- 优先状态机是逻辑单元内部的一种高效编程方法,根据不同状态 或 消息类型,进行相应的处理逻辑,浅显易懂
状态转移图画一下
20

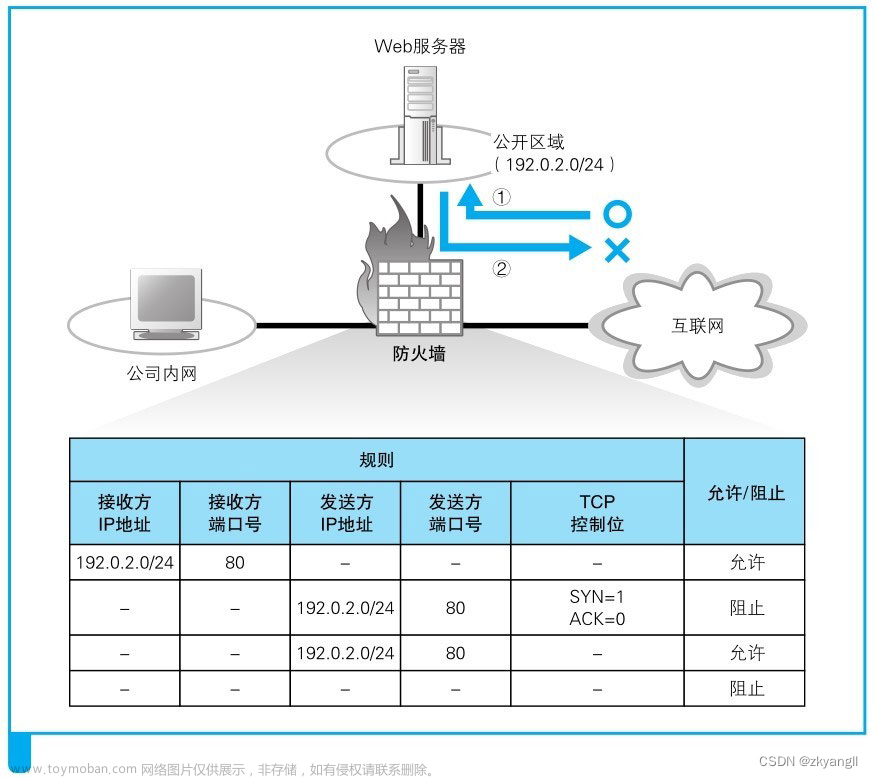
https 协议为什么安全
21
参考博客
为什么HTTPS是安全的,一张图告诉你-腾讯云开发者社区-腾讯云 (tencent.com)
为什么HTTPS比HTTP更安全? - 知乎 (zhihu.com)
网络面经:使用HTTPS就绝对安全了吗?-51CTO.COM
HTTP vs HTTPS: Why Having An SSL Is Important (seahawkmedia.com)
解答
- https 采用 SSL / TLS 协议进行加密通信:
通过对称加密和非对称加密,确保数据在传输过程的保密性;通过散列函数,验证信息的完整性,防止数据在传输过程被篡改- https 通过正数机制进行身份验证:
客户端验证服务器的 CA 证书,避免中间人攻击。CA 证书具有一定公信力,且大多付费,避免黑客冒充网站获取证书- https 的端口是 443,http 是 80,这点也不一样

https 的 ssl 连接过程
22
先看图
再看解析
- client 和 server 协商过程(client 发送自己支持的加密协议,server 选择),确定 SSL 版本,使用的加密算法,密钥长度
- server 发送【公开密钥证书】给 client
- client 用【认证机关】的公开密钥确认证书有效性,然后取出【公开密钥】
- client 生成【对称密钥】(即随机数),通过证书中的【公开密钥】加密,发送给 server
- server 使用【私钥】解密,获取【对称密钥】(随机数),使用【对称密钥】加密数据
- 客户端接收到加密数据后,使用【私钥】(随机数),解密数据,并将结果呈现给用户


GET 和 POST 的区别
23
GET和POST两种基本请求方法的区别 - 在途中# - 博客园 (cnblogs.com)
HTTP 方法:GET 对比 POST | 菜鸟教程 (runoob.com)
相同点
首先,GET 和 POST 是 HTTP 协议中的两种发送请求的方法
其次,HTTP 是基于 TCP / IP 的,关于数据如何在网络中通信的协议
所以 GET 和 POST 的底层都是 TCP / IP,本质是一样的东西
但是,大多数浏览器会限制 url 长度在2000个字节以内,大多数服务器最多处理 64K 大小的 url
如果你用 GET 服务,在请求主体(request body)里藏了数据,有些服务器会直接忽略,你的请求就不会被接收,所以才要遵循下面的规定👇
不同点
GET把参数包含在URL中,POST通过request body传递参数
- GET 产生一个 TCP 数据包;POST 产生两个
1)对于 GET 请求,浏览器会把 http header 和 data 一起发送出去,服务器响应 200 ok
2)对于 POST 呢,浏览器先发送 header,服务器响应 100 continue,浏览器第二次才发送 data,服务器响应 200 ok- GET 参数 url 可见;POST 参数 url 不可见
- GET 可以缓存;POST 不可缓存
- POST 更安全
5)数据库注册登录
登录说一下
24
涉及 4 个流程,分别是:
- 载入数据库表:数据库数据载入服务器
- 提取用户名和密码:解析报文,提取用户名和密码
- 注册登录流程
- 页面跳转
用户名/密码,保存状态了吗?如果要保存,如何做(cookie && session)
25
通过 cookie 和 session 进行保存
- cookie 是服务器给用户分配的一串“身份标识”,比如“1024happy”
每次客户发送数据时,都在 HTTP 报文上附加这个字符串,服务器就知道你是谁了- session 是保存在服务器的状态,每当一个客户发送 HTTP 报文过来,服务器会自己记录的用户数据中查找,类似核对名单
cookie 与 session 的区别
面试官:说下Cookie和Session的关系和区别-腾讯云开发者社区-腾讯云 (tencent.com)
- cookie 数据存放于客户端,session 数据存放于服务器,但是服务端的 session 的实现依赖于客户端的 cookie
- cookie 不是很安全,别人可以分析存放在本地的 cookie 并进行 cookie 欺骗,考虑到安全应当使用 session
- session 会在一定时间内保存在服务器。当访问增多,比较占用服务器性能。此时为了减轻服务器压力,应当使用 cookie
- 单个 cookie 在客户端限制是 3K,即一个站点在客户端存放的 cookie 不能超过 3K
10 亿条用户名和密码 load 到本地然后 hash 匹配,依然很耗时,如何优化?
26
- 数据预处理:对用户名和密码进行哈希加密,以减少实际验证过程中的计算量
- 高性能存储:用户信息存储在高性能介质上,如固态硬盘,提升读取速度
- 负载均衡和集群部署:系统部署在多台服务器,并通过负载均衡来均衡请求流量
- 缓存策略:使用 Redis 等缓存技术,将热门数据缓存起来
- 异步处理:用户登录验证等耗时操作进行异步处理,使用消息队列或任务调度系统,以便验证过程和用户的实际请求解耦
项目用的是 mysql,那么了解过 redis 吗,用过吗
27
Redis 是一种基于内存的键值对存储系统,特点:
- 数据结构多样:支持字符串,哈希,列表,集合,有序集合等
- 高性能:数据存储在内存,所以读写很快,适合作为缓存或高速数据存储使用
- 持久化:支持数据持久化到磁盘,确保数据不会因服务重启而丢失
- 发布订阅:提供发布订阅的功能,用于消息传递和事件通知
Redis 和 Mysql 的区别:
- 数据模型:Redis 是键值对存储系统,适合存储简单的键值对和复杂数据结构;而 Mysql 是关系型数据库,支持表与表间的关联
- 存储介质:Redis 数据存储在内存中,读写快,适合高性能场景;Mysql 数据存储在磁盘,读写相对较慢
- 数据查询:Redis 查询基于键值对,不支持复杂 SQL 查询;Mysql 支持复杂 SQL 查询,可以进行关系型数据的复杂查询和连接操作
最近在看《Redis设计与实现》,看完后,打算做一下 Tiny KV,基于跳表的redis数据库项目
6)定时器
为什么要用定时器
28
定期清楚不活跃连接
定时器工作原理
29
服务器给每个事件分配一个定时器。
通过 SIGALRM 信号实现定时器。
- 首先,定时器在一个升序链表上,通过 alarm() 函数,周期性触发 SIGALRM 信号
- 接着,信号回调函数利用管道通知主循环
- 主循环接收到信号后,处理升序链表上的定时器
- 若一定时间内无数据交换,连接关闭
双向 list,删除和插入的时间复杂度,如何优化
30
如果已知要删除 / 插入的节点,那么,删除 / 插入 都是 O(1)
如果只给了节点的值或序号,那么,增删的时间复杂度都是 O(n)
优化:
- 最小堆(优化定时器)
- 跳表(优化定时器)
最小堆优化?说说时间复杂度和原理
31
- 原理:
1)父节点的键值总是小于等于任一子节点的键值(根节点是最小元素)
2)数组表示的完全二叉树
3)根节点 0,对于任意节点 i,父节点是 (i - 1) / 2,左儿子 2*i + 1,右儿子 2*i + 2- 优化:
1)最小堆以每个定时器过期时间进行排序,最小的定时器位于堆顶(根节点)
2)当 SIGALRM 信号触发 tick() 函数时,执行过期定时器清楚
3)如果堆顶的定时器过期,删除堆顶定时器,并重新建堆
4)再判定堆顶是否过期,一直循环直到未过期- 复杂度:
插入 O(logn),删除 O(logn)
-- 因为这是一棵完全二叉树,而且满足父节点小于等于子节点的要求,所以 n 个元素,插入删除的复杂度,是 logn
跳表优化?说一下时间复杂度和原理
32
innodb为什么选择B+ Tree而不是跳表,Redis为什么选择跳表而不是B+ Tree-腾讯云开发者社区-腾讯云 (tencent.com)
- 原理:
1)链表上添加多层索引,实现快速查找,增加索引层达到空间换时间的目的
2)原始链表 n 个节点,索引层数为 logn - 1,每一层访问次数都是常量,所以查找的时间复杂度 O(logn)- 优化:
1)跳表查找 / 插入 / 删除(任意节点),时间复杂度都是 O(logn)
2)过期任务查找,只需要和第一个节点比较,因为第一个节点就是最小节点- 复杂度:
查找等 O(logn),空间复杂度 O(n)

7)日志系统
说下日志系统运行机制
33
单例模式初始化日志系统,根据配置文件确定同步还是异步的写入方式
为什么要异步,和同步区别是
34
- 同步
1)每次写入日志会立即进行系统调用,将日志信息写入磁盘
2)日志信息较大或写入频率较高时,同步方式会产生较多的系统调用,容易造成系统瓶颈,还会阻塞日志系统的运行- 异步
1)异步方式采用生产者-消费者模型,将日志写入操作与其他任务解耦
2)异步方式中,将需要写入的日志信息,先存储在缓冲区,接着交给单独的线程去处理磁盘 I/O 操作,减少对调用线程的阻塞时间
3)调用日志对象的线程,只需要完成 2 次内存拷贝(第一次拷贝到缓冲区,第二次写入磁盘),而不会阻塞在 I/O 操作=
通过异步方式写入日志,可以避免频繁的系统调用和阻塞,并通过双缓冲区减少内存拷贝次数,并解决数据丢失的问题
【双缓冲区是为了缓解内存读写速度和磁盘读写速度的差异导致部分数据丢失】
关于生产 / 消费者模型
- 生产者消费者模式是指多个进程共享一个固定大小的缓冲区,其中一个进程负责生产数据,另一个进程负责消费数据。
- 使用生产者消费者模式可以平衡生产者和消费者之间的处理能力,避免出现生产者等待消费者或消费者处理等待的情况。
- 缓冲区的作用是存储生产者生产的数据,起到数据缓存和解耦的作用。
- 特点包括保证生产者不会在缓冲区满时继续放入数据,消费者不会在缓冲区空时消耗数据,并通过进入休眠状态和唤醒来实现生产者和消费者之间的协调。
现在你要监控服务器状态,输出监控日志,那么日志如何分发到不同机器?(消息队列)
35
(1)为了便于故障排查,或服务器状态分析,以及确定是否需要维护,可以使用消息队列进行监控日志的分发。
(2)常见的消息队列包括 MQTT,RabbitMQ
(3)使用消息队列分发日志的基本流程:
- 设置消息队列:在服务器集群部署消息队列系统,比如 MQTT 或 RabbitMQ
- 日志写入:服务器状态监控产生日志时,将日志写入消息队列的生产者端,日志里包含服务器状态的信息
- 消息分发:消息队列将接收到的日志消息,分发给订阅了的消费者
- 消费者处理:消费者将日志写入如特定机器的日志文件中,便于后续状态分析;
还可以对日志进行筛选,过滤和聚合,更好理解服务器状态
8)压力测试
并发量如何测试
36
通过 ./webbench -c 10001 -t 5 http://127.0.0.1:9006/ 进行压测
达到了上万并发量(clients)和上万QPS(query per second)
webbench 是什么,原理是
37
一个压测软件,可以在命令行通过 sudo apt-get install 安装依赖,以及后续的源码的下载和安装
原理
webbench 首先 fork 出多个子进程,每个子进程都循环做 web 访问测试。
子进程把访问的结果通过 pipe 告诉父进程,父进程做最终结果的统计
详细说明
1)父进程调用 fork() 系统调用时,操作系统会创建一个新的子进程,这个子进程是父进程的一个副本,包括代码,数据以及各种资源和状态。
2)父进程和子进程都会继续执行接下来的指令,但是 fork() 函数返回值不同。
3)具体的说,父进程中,fork() 返回值是新创建的子进程 ID(PID);而子进程,fork() 返回值是 0
4)返回值的不同,使得父子进程可以分别执行自己的逻辑
5)父进程多次调用 fork() 创建多个子进程,子进程间互相独立,有着自己的进程 ID,同时运行在自己的地址空间里
测试时遇到的问题
nope...
Web 服务器 QPS 到达瓶颈,一直上不去,怎么办
38
后端跳槽必问八股~
一,Mysql 性能
- CPU占用过高:不合理的 SQL 查询导致的 CPU 负载过高,需要优化索引与 SQL 语句
- 设计不合理:业务逻辑实现不合理,会增加数据库压力,考虑加缓存以减轻数据库负载
二,系统架构
- 水平扩展:增加服务器,使用负载均衡来处理更多请求
- 数据库优化:优化查询,使用缓存技术,比如 Redis 减轻数据库负载
- 异步处理:将耗时任务转为异步任务,减少请求响应时间
- 缓存:对于频繁访问的数据,采用 redis 集群等分布式缓存系统
三,资源占满问题
- CPU,带宽,IO 被占满:可能由于密集运算,贷款或后端服务等原因,导致资源瓶颈,需优化代码结构,排查异常逻辑,增加服务器资源
- 基础组件问题:网络框架性能,log 库性能,网络参数配置,也可能是瓶颈的原因
9)综合能力
项目亮点是(区别于同类项目)
39
烂大街的玩具一样的八股触发器,哪里来的亮点??你是眼瞎吗???
不过下一步可能加个协程库,提升响应速度和并发量;
或者用C++14重写一遍
以后就不会再碰服务器项目了,(C++服务器 / 后端)没有就业岗位,只是拿来打基础的😰
而且C++找工作不容易,大概率要转的,但是前期打下的基础,以后可以做点相关的方面,校招也不会要求你多深入,(八股 / 算法 / 项目)合格的前提下,有一两段言之有物的实习,入了行提升才快
前端发送请求后,服务器处理过程涉及的协议
40
HTTP协议的请求和响应;底层传输协议 TCP/IP 确保数据传输的可靠性文章来源:https://www.toymoban.com/news/detail-852765.html
👂 ▶ Cruisin (163.com)文章来源地址https://www.toymoban.com/news/detail-852765.html
到了这里,关于WebServer -- 面试题(下)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!