图数据库简介
图数据库是基于数学里图论的思想和算法而实现的高效处理复杂关系网络的新型数据库系统。它善于高效处理大量的、复杂的、互连的、多变的数据。其计算效率远远高于传统的关系型数据库。
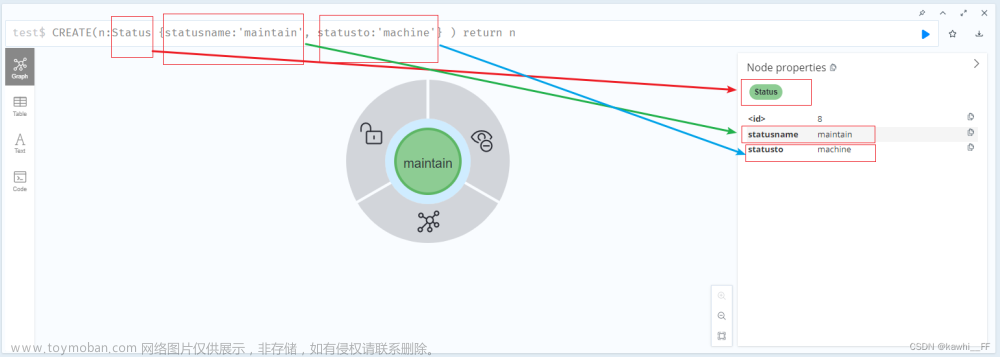
在图形数据库当中,每个节点代表一个对象,节点之间的连线代表对象之间的关系。节点可带标签。节点和关系都可以带若干属性。每个节点可以存储实体的属性,每条边可以描述实体之间的关联。
图形数据库以图形结构存储数据,通过节点和边表示实体及其关系,适用于需要高效处理复杂关系数据的场景,如社交网络、实时推荐、征信系统、人工智能等领域。
Neo4j简介
Neo4j是由JAVA开发的图数据库,专门用于存储、检索和处理图形数据,应用图形理论来存储实体之间的关系。
Neo4j提供了灵活而强大的工具和功能,使用户能够轻松地管理复杂的关系和连接。它也可以被看作是一个高性能的图引擎,并且该引擎具有成熟数据库的所有特性。
Neo4j最主要的特点是数据将结构化数据存储在网络上,而不是存储在数据表中。
Neo4j特点
1.易用性:Neo4j的图形数据模型非常直观,可以轻松地表示实体、关系和属性。这种直观性使得用户可以更容易地理解和设计数据模型,而无需过多的抽象概念。
2.高性能:Neo4j拥有高性能的原生图形存储引擎,能够高效地执行图形查询操作。它采用了基于属性图的存储模型,支持快速的图形遍历和复杂查询,并支持大规模的数据集。
3.高可用性:Neo4j不仅支持完整的事务管理,还提供了实时在线的备份功能,以及应对灾难事故进行日志恢复的方法,从而可以防止数据的丢失。Neo4j还提供了监控工具和管理界面,可以实时监控集群的状态和性能指标。当系统出现故障时,管理员可以通过监控界面进行故障转移操作,确保系统的稳定性和可用性。
4.可扩展性:Neo4j支持水平和垂直两个方向的扩展,可以根据需求扩展存储容量和处理能力。这使得Neo4j能够应对不断增长的数据规模和查询需求。
5.设计灵活:由于Neo4j没有模式结构定义的约束,并且图结构具有自然伸缩特性,这都给Neo4j提供了无限广阔的灵活设计空间。无论是扩展设计,还是增加数据,都不会影响原来数据的正常使用。
Neo4j数据模型
Neo4j数据模型是由顶点、边、标签、关系类型以及属性组成的有向图。
1.顶点:顶点也可以称为节点,通常用圆形表示,所有的节点都是独立存在的。节点是图中的基本单元,用于表示实体或对象。每个节点可以包含一个或多个属性,用来描述节点的特征或信息。节点可以根据需要分为不同的标签,标签可以用来对节点进行分类或归类。
2.边:边也可以成为关系,是使用有向箭头标识的,箭头的方向表示了边的起始节点和结束节点之间的方向性。关系用于描述节点之间的连接或关联,表示实体之间的交互或联系。关系总是有一个方向,起始节点和结束节点之间有明确定义的关系类型。关系也可以包含属性,用来描述关系本身的特征或信息。
3.标签:标签类似于节点的类型,若多个节点拥有相同的标签,则这些节点属于同一个集合。通过给节点添加标签,可以在查询和索引时更方便地对节点进行过滤和定位。标签可以帮助用户组织和管理图数据库中的节点,使得节点之间的关系更加清晰和易于理解。节点可以拥有多个标签。
4.属性:节点和关系都可以拥有属性,属性用于存储节点或关系的具体信息或特征。属性以键值对的形式存在,每个属性由属性名和属性值组成。属性值可以是字符串、数值、日期等各种数据类型。节点或关系可以拥有多个属性。
Neo4j索引
Neo4j的索引机制是为了加快节点和关系的查找速度而设计的。索引可以帮助数据库引擎快速定位符合特定条件的节点或关系,从而提高查询性能。
1.节点索引:Neo4j的节点索引是一种用于快速查找节点的数据结构。它允许为节点的一个或多个属性创建索引,以便在查询时可以快速定位到符合条件的节点。通过节点索引,可以避免对整个节点集合进行全表扫描,从而显著提高查询效率。
2.关系索引:与节点索引类似,关系索引允许为关系的一个或多个属性创建索引,以便根据关系属性条件快速查找关系。关系索引可以加速基于关系属性的查询操作。
3.全文索引:Neo4j的全文索引允许对节点的文本内容进行搜索。它支持基于词汇的搜索和模糊查询,能够在文本数据中快速找到包含特定关键词的节点。全文索引通常用于处理大量的文本数据,如文章、评论或社交媒体内容。可以使用全文索引来实现高效的文本搜索功能。
4.空间索引:Neo4j的空间索引用于处理具有地理坐标信息的节点,例如地图数据或位置信息。它允许在地理空间上进行查询和分析,如查找附近的节点、计算距离等。通过空间索引,可以有效地处理地理位置相关的查询需求,如地图应用或位置服务。
5.自定义索引:除了节点、全文和空间索引之外,Neo4j还支持自定义索引,允许用户根据具体需求定义和管理自己的索引策略。自定义索引提供了灵活性和可定制性,使用户能够根据应用场景选择最适合的索引类型和配置参数。
Neo4j集群
因果集群是Neo4j的官方集群方案,基于Raft一致性协议实现高可用性和数据一致性。
因果集群允许在多个服务器之间复制Neo4j数据库,从而提供冗余和自动故障转移。因果集群由多个核心服务器组成,每个核心服务器都包含数据副本,并负责处理数据的读写请求。因果集群实现了读写分离,提高了系统的读取性能和吞吐量。
因果集群的服务器被划分为三个角色:Leader,Follow和Read Replica。
Leader服务器负责接收客户端的写操作请求,将这些操作复制到其他核心服务器上,并协调Raft一致性协议,确保核心服务器之间的数据复制和同步过程中的一致性。每个因果集群只有一个Leader,负责整个集群的写入操作。在Leader发生故障或失效时,Raft协议会自动进行Leader选举,选择新的Leader来代替。
Follow服务器从Leader核心服务器获取数据更新,参与数据提交和确认,并在Leader的指导下执行写操作,确保数据的一致性和完整性。
Read Replica服务器负责处理读操作请求,提供读取性能优化和负载均衡,它可以并行执行多个读操作,减轻Leader核心服务器的读取压力,提高系统的读取性能。Read Replica不参与写操作的提交和复制,仅用于处理读取请求,提高系统的读取性能和吞吐量,可以根据需求部署多个Read Replica副本,实现横向扩展和负载均衡。
Neo4j分片
Neo4j分片是指将一个大型的Neo4j数据库水平划分成多个小片段,每个小片段存储在集群中的不同节点上。这样的分片架构可以帮助提高Neo4j数据库的性能、扩展性和容错能力,使其能够处理更大规模的数据和更高的并发访问。
Neo4j分片通过一定的数据划分策略(如哈希分片、范围分片等)将数据库中的节点和关系数据分配到不同的分片中存储。分片通过路由和负载均衡机制确保数据请求被正确路由到相应的分片上,并且能够平衡各个节点之间的负载,提高系统的整体性能。为了保证数据的高可用性和容错能力,每个分片通常都会有多个副本,并且这些副本会分布在不同的节点上,以防止单点故障。分片通常会实现容灾备份和恢复机制,确保数据在发生灾难性事件时能够及时恢复并保持正常运行。
Neo4j分片允许系统根据需要动态扩展和收缩,这对于应对数据量的快速增长或减少非常重要。系统管理员可以根据系统负载情况自动或手动地添加或删除分片。在分片环境下,跨分片的事务管理变得更加复杂。Neo4j分片会处理分布式事务的提交和回滚,确保数据的一致性和隔离性。
Neo4j缓存
查询结果缓存:Neo4j的查询结果缓存是为了避免重复执行相同的查询而设计的。当执行一个查询时,Neo4j会将查询结果缓存起来,如果后续再次执行相同的查询,系统可以直接返回缓存中的结果,而不需要重新执行查询语句。这种缓存机制可以显著提高查询性能,特别是对于频繁执行相同查询的场景。
结点缓存和关系缓存:Neo4j使用节点缓存和关系缓存来存储数据库中的节点和关系对象,以减少对磁盘的IO访问。当执行查询需要访问某些节点或关系时,Neo4j首先会检查缓存中是否存在这些对象,如果存在,则可以直接从缓存中获取,从而避免频繁访问磁盘,提高查询速度。
Neo4j的优缺点
优点:
1.Neo4j能够自然而直观地表达实体之间的复杂关系,使得处理复杂关系型数据变得更加容易。通过节点、关系和属性的组合,Neo4j能够轻松地适应不同类型和结构的数据模型,适合处理多变的数据模式。
2.Neo4j优秀的图算法和索引机制,Neo4j在处理复杂的关系查询时表现出色,能够快速执行复杂的图查询操作,支持快速的图形遍历。
3.Neo4j能够处理动态和变化的数据模型。它允许动态添加节点和关系,适应数据模型的变化。
缺点:
1.由于图数据库的存储方式和索引机制,Neo4j可能会占用较多的存储空间,特别是在处理大规模数据时。
2.Neo4j不适合需要高并发写入操作的场景,因为它的写入性能不如专门设计的分布式数据存储系统。文章来源:https://www.toymoban.com/news/detail-852796.html
3.Neo4j在安全性控制方面相对较弱,对于需要严格访问控制和权限管理的场景可能需要额外的安全性配置。文章来源地址https://www.toymoban.com/news/detail-852796.html
到了这里,关于Neo4j基础知识的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!