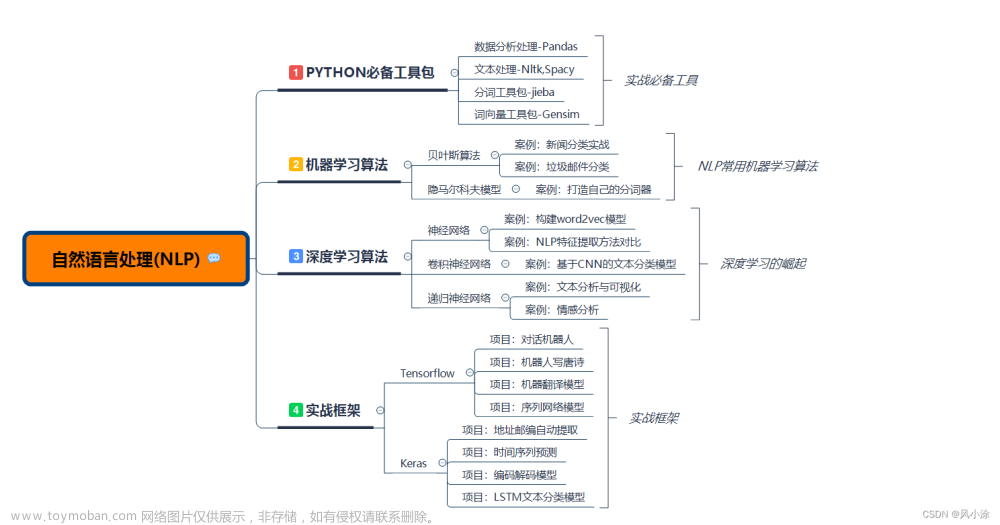
CLASSIC NLP
TF-IDF & ML (8)
-
Write TF-IDF from scratch.
-
What is normalization in TF-IDF ?
-
Why do you need to know about TF-IDF in our time, and how can you use it in complex models?
-
Explain how Naive Bayes works. What can you use it for?
-
How can SVM be prone to overfitting?
-
Explain possible methods for text preprocessing ( lemmatization and stemming ). What algorithms do you know for this, and in what cases would you use them?
-
What metrics for text similarity do you know?
-
Explain the difference between cosine similarity and cosine distance. Which of these values can be negative? How would you use them?
METRICS (7)
-
Explain precision and recall in simple words and what you would look at in the absence of F1 score?
-
In what case would you observe changes in specificity ?
-
When would you look at macro, and when at micro metrics? Why does the weighted metric exist?
-
What is perplexity? What can we consider it with?
-
What is the BLEU metric?
-
Explain the difference between different types of ROUGE metrics?
-
What is the difference between BLUE and ROUGE?
WORD2VEC(9)
-
Explain how Word2Vec learns? What is the loss function? What is maximized?
-
What methods of obtaining embeddings do you know? When will each be better?
-
What is the difference between static and contextual embeddings?
-
What are the two main architectures you know, and which one learns faster?
-
What is the difference between Glove, ELMO, FastText, and Word2Vec ?
-
What is negative sampling and why is it needed? What other tricks for Word2Vec do you know, and how can you apply them?
-
What are dense and sparse embeddings? Provide examples.
-
Why might the dimensionality of embeddings be important?
-
What problems can arise when training Word2Vec on short textual data, and how can you deal with them?
RNN & CNN(7)
-
How many training parameters are there in a simple 1-layer RNN ?
-
How does RNN training occur?
-
What problems exist in RNN?
-
What types of RNN networks do you know? Explain the difference between GRU and LSTM?
-
What parameters can we tune in such networks? (Stacking, number of layers)
-
What are vanishing gradients for RNN? How do you solve this problem?
-
Why use a Convolutional Neural Network in NLP, and how can you use it? How can you compare CNN within the attention paradigm?
NLP and TRANSFORMERS
ATTENTION AND TRANSFORMER ARCHITECTURE (15)
-
How do you compute attention ? (additional: for what task was it proposed, and why?)
-
Complexity of attention? Compare it with the complexity in RNN.
-
Compare RNN and attention . In what cases would you use attention, and when RNN?
-
Write attention from scratch.
-
Explain masking in attention.
-
What is the dimensionality of the self-attention matrix?
-
What is the difference between BERT and GPT in terms of attention calculation ?
-
What is the dimensionality of the embedding layer in the transformer?
-
Why are embeddings called contextual? How does it work?
-
What is used in transformers, layer norm or batch norm , and why?
-
Why do transformers have PreNorm and PostNorm ?
-
Explain the difference between soft and hard (local/global) attention?
-
Explain multihead attention.
-
What other types of attention mechanisms do you know? What are the purposes of these modifications?
-
How does self-attention become more complex with an increase in the number of heads?
TRANSFORMER MODEL TYPES (7)
-
Why does BERT largely lag behind RoBERTa , and what can you take from RoBERTa?
-
What are T5 and BART models? How do they differ?
-
What are task-agnostic models? Provide examples.
-
Explain transformer models by comparing BERT, GPT, and T5.
-
What major problem exists in BERT, GPT, etc., regarding model knowledge? How can this be addressed?
-
How does a decoder-like GPT work during training and inference? What is the difference?
-
Explain the difference between heads and layers in transformer models.
POSITIONAL ENCODING (6)
-
Why is information about positions lost in embeddings of transformer models with attention?
-
Explain approaches to positional embeddings and their pros and cons.
-
Why can’t we simply add an embedding with the token index?
-
Why don’t we train positional embeddings?
-
What is relative and absolute positional encoding?
-
Explain in detail the working principle of rotary positional embeddings.
PRETRAINING (4)
-
How does causal language modeling work?
-
When do we use a pretrained model?
-
How to train a transformer from scratch? Explain your pipeline, and in what cases would you do this?
-
What models, besides BERT and GPT, do you know for various pretraining tasks?
TOKENIZERS (9)
-
What types of tokenizers do you know? Compare them.
-
Can you extend a tokenizer? If yes, in what case would you do this? When would you retrain a tokenizer? What needs to be done when adding new tokens?
-
How do regular tokens differ from special tokens?
-
Why is lemmatization not used in transformers? And why do we need tokens?
-
How is a tokenizer trained? Explain with examples of WordPiece and BPE .
-
What position does the CLS vector occupy? Why?
-
What tokenizer is used in BERT, and which one in GPT?
-
Explain how modern tokenizers handle out-of-vocabulary words?
-
What does the tokenizer vocab size affect? How will you choose it in the case of new training?
TRAINING (8)
-
What is class imbalance? How can it be identified? Name all approaches to solving this problem.
-
Can dropout be used during inference, and why?
-
What is the difference between the Adam optimizer and AdamW?
-
How do consumed resources change with gradient accumulation?
-
How to optimize resource consumption during training?
-
What ways of distributed training do you know?
-
What is textual augmentation? Name all methods you know.
-
Why is padding less frequently used? What is done instead?
-
Explain how warm-up works.
-
Explain the concept of gradient clipping?
-
How does teacher forcing work, provide examples?
-
Why and how should skip connections be used?
-
What are adapters? Where and how can we use them?
-
Explain the concepts of metric learning. What approaches do you know?
INFERENCE (4)
-
What does the temperature in softmax control? What value would you set?
-
Explain types of sampling in generation? top-k, top-p, nucleus sampling?
-
What is the complexity of beam search, and how does it work?
-
What is sentence embedding? What are the ways you can obtain it?
LLM (13)
-
How does LoRA work? How would you choose parameters? Imagine that we want to fine-tune a large language model, apply LORA with a small R, but the model still doesn’t fit in memory. What else can be done?
-
What is the difference between prefix tuning , p-tuning , and prompt tuning ?
-
Explain the scaling law .
-
Explain all stages of LLM training. From which stages can we abstain, and in what cases?
-
How does RAG work? How does it differ from few-shot KNN?
-
What quantization methods do you know? Can we fine-tune quantized models?
-
How can you prevent catastrophic forgetting in LLM?
-
Explain the working principle of KV cache , Grouped-Query Attention , and MultiQuery Attention .
-
Explain the technology behind MixTral, what are its pros and cons?文章来源:https://www.toymoban.com/news/detail-852937.html
-
How are you? How are things going?文章来源地址https://www.toymoban.com/news/detail-852937.html
到了这里,关于大厂100 NLP interview questions外企的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!