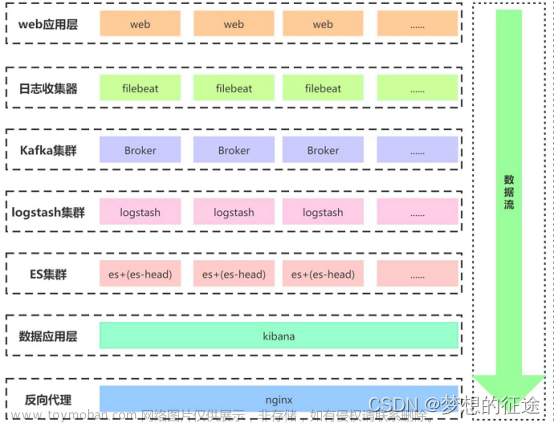
SpringBoot项目准备
引入log4j2替换SpringBoot默认log,demo项目结构如下:

pom

IndexController
测试Controller,用以打印日志进行调试

InputMDC
用以获取log中的[%X{hostName}]、[%X{ip}]、[%X{applicationName}]三个字段值

NetUtil

启动项目,访问/index和/ero接口,可以看到项目中生成了app-collector.log和error-collector.log两个日志文件

我们将Springboot服务部署在192.168.11.31这台机器上。
3
Kafka安装和启用
kafka下载地址:http://kafka.apache.org/downloads.html
kafka安装步骤:首先kafka安装需要依赖与zookeeper,所以小伙伴们先准备好zookeeper环境(三个节点即可),然后我们来一起构建kafka broker。

创建两个topic
创建topic
kafka-topics.sh --zookeeper 192.168.11.111:2181 --create --topic app-log-collector --partitions 1 --replication-factor 1
kafka-topics.sh --zookeeper 192.168.11.111:2181 --create --topic error-log-collector --partitions 1 --replication-factor 1
我们可以查看一下topic情况
kafka-topics.sh --zookeeper 192.168.11.111:2181 --topic app-log-test --describe
可以看到已经成功启用了app-log-collector和error-log-collector两个topic

4
filebeat安装和启用:
filebeat下载
cd /usr/local/software
tar -zxvf filebeat-6.6.0-linux-x86_64.tar.gz -C /usr/local/
cd /usr/local
mv filebeat-6.6.0-linux-x86_64/ filebeat-6.6.0
配置filebeat,可以参考下方yml配置文件
vim /usr/local/filebeat-5.6.2/filebeat.yml
###################### Filebeat Configuration Example #########################
filebeat.prospectors:
- input_type: log
paths:
app-服务名称.log, 为什么写死,防止发生轮转抓取历史数据
- /usr/local/logs/app-collector.log
#定义写入 ES 时的 _type 值
document_type: “app-log”
multiline:
#pattern: ‘^\s*(\d{4}|\d{2})-(\d{2}|[a-zA-Z]{3})-(\d{2}|\d{4})’ # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: ‘^[’ # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 2000 # 最大的行数
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: app-log-collector ## 按服务划分用作kafka topic
evn: dev
- input_type: log
paths:
- /usr/local/logs/error-collector.log
document_type: “error-log”
multiline:
#pattern: ‘^\s*(\d{4}|\d{2})-(\d{2}|[a-zA-Z]{3})-(\d{2}|\d{4})’ # 指定匹配的表达式(匹配以 2017-11-15 08:04:23:889 时间格式开头的字符串)
pattern: ‘^[’ # 指定匹配的表达式(匹配以 "{ 开头的字符串)
negate: true # 是否匹配到
match: after # 合并到上一行的末尾
max_lines: 2000 # 最大的行数
timeout: 2s # 如果在规定时间没有新的日志事件就不等待后面的日志
fields:
logbiz: collector
logtopic: error-log-collector ## 按服务划分用作kafka topic
evn: dev
output.kafka:
enabled: true
hosts: [“192.168.11.51:9092”]
topic: ‘%{[fields.logtopic]}’
partition.hash:
reachable_only: true
compression: gzip
max_message_bytes: 1000000
required_acks: 1
logging.to_files: true
filebeat启动:
检查配置是否正确
cd /usr/local/filebeat-6.6.0
./filebeat -c filebeat.yml -configtest
Config OK
启动filebeat
/usr/local/filebeat-6.6.0/filebeat &
检查是否启动成功
ps -ef | grep filebeat
可以看到filebeat已经启动成功

然后我们访问192.168.11.31:8001/index和192.168.11.31:8001/err,再查看kafka的logs文件,可以看到已经生成了app-log-collector-0和error-log-collector-0文件,说明filebeat已经帮我们把数据收集好放到了kafka上。
5
logstash安装
logstash的安装可以参考《Logstash的安装与使用》。
我们在logstash的安装目录下新建一个文件夹
mkdir scrpit
然后cd进该文件,创建一个logstash-script.conf文件
cd scrpit
vim logstash-script.conf
multiline 插件也可以用于其他类似的堆栈式信息,比如 linux 的内核日志。
input {
kafka {
app-log-服务名称
topics_pattern => “app-log-.*”
bootstrap_servers => “192.168.11.51:9092”
codec => json
consumer_threads => 1 ## 增加consumer的并行消费线程数
decorate_events => true
#auto_offset_rest => “latest”
group_id => “app-log-group”
}
kafka {
error-log-服务名称
topics_pattern => “error-log-.*”
bootstrap_servers => “192.168.11.51:9092”
codec => json
consumer_threads => 1
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后


《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!**
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
最后
[外链图片转存中…(img-JUkfIcPn-1712681006601)]文章来源:https://www.toymoban.com/news/detail-853140.html
[外链图片转存中…(img-rdt0SknF-1712681006601)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!文章来源地址https://www.toymoban.com/news/detail-853140.html
到了这里,关于SpringBoot+Kafka+ELK 完成海量日志收集(超详细)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!