声明:笔记是做项目时根据B站博主视频学习时自己编写,请勿随意转载!
一、环境安装
VScode/Pycharm终端进入虚拟环境后,输入下面代码安装pyside6,若用的Pycharm作为集成开发环境,也下载个pyqt5:
pip install pyside6pip install pyqt5安装完pyside6时其实一并安装了qtdesigner,这个工具可让我们以拖拽的方式设计界面,按下面方法找到这个工具放在桌面以便后续使用:
终端输入:
where python 现在用的虚拟环境是第二个,找到找到虚拟环境path/lib/site-packages/Pyside6/designer.exe:
现在用的虚拟环境是第二个,找到找到虚拟环境path/lib/site-packages/Pyside6/designer.exe:

右键创建桌面快捷方式并打开,界面如下:

注意:这个工具生成的文件为.ui文件,不是.py文件,还需要一个编译器编译为.py文件,若用的VScode,在左侧扩展中安装插件qt for python即可;若用的Pycharm,ui文件转换为py可参考这篇博客(记得先安装pip install pyqt5):
Pycharm的QT Designer的.ui转.py文件
二、QT Designer进行UI设计
①创建一个Main Window

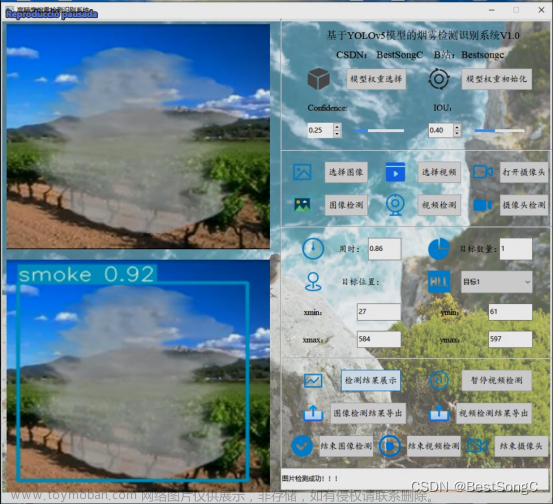
②利用左侧的Label,创建两个图片显示框,一个显示原图片/视频,另一个显示检测结果

③按钮选择是检测图片还是视频,用到左侧的Push Button:
 布局如下,文字位置等可在右侧属性编辑器中更改居中,图片和检测结果框需选中scaledContents勾选,因为实际图片的尺寸是不确定的。
布局如下,文字位置等可在右侧属性编辑器中更改居中,图片和检测结果框需选中scaledContents勾选,因为实际图片的尺寸是不确定的。

为了区分名称可以在右侧对象框中,根据实际作用更改名称原始图片Label命名为input,检测结果Label命名为output,按钮分别是det_image和det_video:

如此UI设计结束,将其保存在我们的yolov5-7.0文件夹中,.ui文件命名为main_window:

三、后端逻辑设计
首先利用上面提供的方法将.ui文件转换为.py文件,同名放在了文件夹如下图:

在yolov5-7.0文件夹中创建一个名为base_ui.py的文件用于编写我们的后端逻辑,先写个框架:
import sys
from PyQt5.QtWidgets import QMainWindow, QApplication #注:如果用的VScode就是from Pyside6
from main_window import Ui_MainWindow
class MainWindow(QMainWindow, Ui_MainWindow): #新建一个MainWindow类,继承了两个类(一个导入的QMainWindow,另一个是main_window.py文件里的Ui_MainWindow)
def __init__(self):
super(MainWindow, self).__init__()
self.setupUi(self) #调用setupUi(),它是main_window.py文件里的Ui_MainWindow类里的函数
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
app.exec_()点击运行即可加载出刚才设计的UI界面:

然后在代码框架中逐个定义需要的逻辑或者说函数。功能按钮的编写关键在于绑定信号与槽(bind_slots),即为每个按钮绑定触发事件。
import sys
import cv2
import torch
from PyQt5.QtWidgets import QMainWindow, QApplication, QFileDialog #注:如果用的VScode就是from Pyside6
from PyQt5.QtGui import QPixmap, QImage
from PyQt5.QtCore import QTimer #解决视频检测时阻塞问题,循环不用while True用timer
from main_window import Ui_MainWindow
def convert2QImage(img): #将array转换为UI Label可以显示的格式
height, width, channel= img.shape
return QImage(img, width, height, width*channel, QImage.Format_RGB888)
class MainWindow(QMainWindow, Ui_MainWindow): #新建一个MainWindow类,继承了两个类(一个导入的QMainWindow,另一个是main_window.py文件里的Ui_MainWindow)
def __init__(self):
super(MainWindow, self).__init__()
self.setupUi(self) #调用setupUi(),它是main_window.py文件里的Ui_MainWindow类里的函数
# Model 使用torch.hub.load()函数加载YOLOv5目标检测模型
self.model = torch.hub.load("./", "custom", "runs/train/exp9/weights/best", source="local") #参照hub_detect代码加载模型
self.timer = QTimer() #解决视频检测时阻塞问题,循环不用while True用timer
self.timer.setInterval(100) #计时间隔ms
self.video = None
self.bind_slots()
def image_pred(self, file_path):
# 使用加载的模型对指定的图像进行目标检测。
# model()方法接受一个图像路径作为输入,并返回检测结果。检测结果包含了检测框的坐标、类别标签和置信度等信息。
results = self.model(file_path)
image = results.render()[0] #检测结果图片的array数组,但没法直接显示在ui的Label,需要上面编写的转换函数convert2QImage
return convert2QImage(image)
def open_image(self):
#print("检测图片")
file_path = QFileDialog.getOpenFileName(self, "选择图片", "./datasets/images/train", "Images (*.jpg *.png *.jpeg)") #第一个参数是弹出框的名字,第二个参数是默认跳转路径,第三个参数过滤只显示某些文件格式的文件
#file_path返回一个元组,('.../datasets/images/train/30.jpg', 'Images (*.jpg *.png *.jpeg)'),
# 我们只需要第一个元素file_path[0]。不选路径元组为空
if file_path[0]:
file_path = file_path[0]
qimage = self.image_pred(file_path)
self.input.setPixmap(QPixmap(file_path)) #依据选择路径传入图片文件并显示
self.output.setPixmap(QPixmap.fromImage(qimage)) #显示检测结果
#print(file_path)
def video_pred(self):
ret, frame = self.video.read() # 抽取一帧放在frame
if not ret:
self.timer.stop()
else:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB) # 将这一帧frame转换为常规的RGB格式
self.input.setPixmap(QPixmap.fromImage(convert2QImage(frame))) # 依据选择路径传入图片文件并显示
# 使用加载的模型对指定的图像进行目标检测。
# model()方法接受一个图像路径作为输入,并返回检测结果。检测结果包含了检测框的坐标、类别标签和置信度等信息。
results = self.model(frame)
image = results.render()[0] #检测结果图片的array数组,但没法直接显示在ui的Label,需要上面编写的转换函数convert2QImage
self.output.setPixmap(QPixmap.fromImage(convert2QImage(image))) # 显示检测结果
def open_video(self): #抽帧+单个图片检测+显示
print("检测视频")
file_path = QFileDialog.getOpenFileName(self, "选择图片", "./datasets", "Images (*.mp4)")
if file_path[0]:
file_path = file_path[0]
self.video = cv2.VideoCapture(file_path)
self.timer.start()
def bind_slots(self):
self.det_image.clicked.connect(self.open_image) #当det_image按钮点击时(链接)执行open_image函数
self.det_video.clicked.connect(self.open_video)
self.timer.timeout.connect(self.video_pred)
if __name__ == "__main__":
app = QApplication(sys.argv)
window = MainWindow()
window.show()
app.exec_()
上面是最终更改好的代码。函数逻辑:按钮bind_slots函数里面套了open_image函数和open_video函数(绑定槽) ;然后open_image函数和open_video函数里面分别套了image_pred函数和video_pred函数,使得选好图片/视频路径后自动开始检测并显示。
其中原本视频检测用的是抽帧和while true循环检测并显示的逻辑,但在前端中经常会遇到时间步长不合适出现阻塞问题,后来跟着博主用了qtimer计数器的方法,更改过程的视频如下:
YOLOv5检测UI可视化:timer时间步长更改
最终效果演示如下:
YOLOv5检测可视化界面效果演示
如果嫌显示的视频太卡顿,可在代码中更改时间步长:
self.timer.setInterval(100) #计时间隔ms,可以把100改的更小小BUG
检测视频时,切换图片检测输入图片后一闪即逝,还在检测刚才的视频。这是由于计时器timer一直在运行,需要在open_image()函数中加一句,打开图片时关闭timer即可:
def open_image(self):
#print("检测图片")
self.timer.stop()
.....往期精彩
STM32专栏(付费9.9)
OpenCV-Python专栏(付费9.9)
AI底层逻辑专栏(付费9.9)文章来源:https://www.toymoban.com/news/detail-853406.html
机器学习专栏(免费)FreeRTOS专栏(免费)电机控制专栏(免费)文章来源地址https://www.toymoban.com/news/detail-853406.html
到了这里,关于【YOLOV5 入门】——Pyside6/PyQt5可视化UI界面&后端逻辑的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!