目录
1.node_exporter简介
2.部署node_exporter
2.1.安装node_exporter
2.2.编写system启动脚本
3.prometheus监控Linux主机
3.1.修改配置文件增加主机节点
3.2.主机添加成功
4.监控Linux主机CPU、内存、磁盘使用率
4.1.监控CPU使用率
4.1.1.获取空闲CPU监控数据
4.1.2.获取5分钟内的监控数据
4.1.3.获取5分钟内的CPU平均空闲情况
4.1.4.获取CPU5分钟内使用率
4.2.监控内存使用率
4.2.1.获取空闲内存
4.2.2.获取空闲内存率
4.2.3.获取内存使用率
4.3.监控磁盘使用率
4.3.1.获取磁盘空闲率
4.3.2.获取磁盘使用率
5.监控系统服务状态
5.1.配置node_exporter启动参数
5.2.查看服务的监控状态
1.node_exporter简介
node_exporter常用于系统监控,使用go语言编写的指标收集器
node_exporter操作文档:https://prometheus.io/docs/guides/node-exporter/
prometheus支持的exporters列表:https://prometheus.io/docs/instrumenting/exporters/
2.部署node_exporter
环境准备,在所有机器上都部署node_exporter,步骤都一样
| IP | 角色 |
|---|---|
| 192.168.81.210 | prometheus、node_exporter、docker |
| 192.168.81.220 | node_exporter、docker |
| 192.168.81.230 | node_exporter、docker |
2.1.安装node_exporter
node_exporter下载地址: https://github.com/prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
tar xf node_exporter-1.0.1.linux-amd64.tar.gz
mv node_exporter-1.0.1.linux-amd64 /data/node_exporter/
cp /data/node_exporter/node_exporter /usr/bin/
2.2.编写system启动脚本
1.编写文件
vim /usr/lib/systemd/system/node_exporter.service
[Unit]
Description=https://prometheus.io
[Service]
Restart=on-failure
ExecStart=/data/node_exporter/node_exporter
[Install]
WantedBy=multi-user.target
2.启动
systemctl daemon-reload
systemctl start node_exporter.service
systemctl enable node_exporter.service

3.prometheus监控Linux主机
3.1.修改配置文件增加主机节点
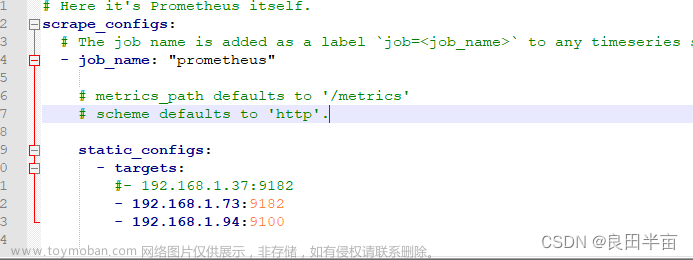
我们使用自动发现来实现,修改完配置加载一下
1.修改配置文件
[root@prometheus-server ~]# vim /data/prometheus/prometheus.yml
- job_name: 'centos7-node'
file_sd_configs:
- files: ['/data/prometheus/targets/node/*.yml']
refresh_interval: 5s
2.加载配置
[root@prometheus-server ~]# curl -XPOST 192.168.81.210:9090/-/reload
3.编写自动发现文件
[root@prometheus-server ~]# mkdir /data/prometheus/targets/node
[root@prometheus-server ~]# vim /data/prometheus/targets/node/node.yml
- targets:
- '192.168.81.210:9100'
- '192.168.81.220:9100'
- '192.168.81.230:9100'
labels:
idc: "bj"
3.2.主机添加成功

4.监控Linux主机CPU、内存、磁盘使用率
4.1.监控CPU使用率
CPU的监控项名称是:node_cpu_seconds_total,使用总量
直接执行node_cpu_seconds_total查询后会出现很多监控指标,显然不是想要的
node_cpu_seconds_total执行后会出现很多监控指标,其中各种类型的比如系统态、用户态都会由mode标签来区分
我们想要查询CPU的使用率的思路是:
查出当前空闲的CPU百分比,最后用100减去,mode标签值idle就表示当前空闲的CPU值

4.1.1.获取空闲CPU监控数据
mode标签值为idle的为空闲
node_cpu_seconds_total{mode='idle'}

4.1.2.获取5分钟内的监控数据
上一步虽然可以查出来结果,但是不太理想,因为CPU是不断波动的,我们可以在增加一个条件,查询5分钟内的一个CPU使用情况

4.1.3.获取5分钟内的CPU平均空闲情况
我们可以使用irate和avg函数结合刚才查询出5分钟内数据做一个平均情况展示
函数的使用方法:函数(指标获取方式)
avg(irate(node_cpu_seconds_total{mode=‘idle’}[5m])) by (instance)
by(instance)表示以instance标签进行分组

4.1.4.获取CPU5分钟内使用率
最后我们可以*100得出一个百分比的空闲率,再由100-即可得到CPU的使用率
100 - (avg(irate(node_cpu_seconds_total{mode='idle'}[5m])) by (instance) *100)

4.2.监控内存使用率
由于内存的监控项没有像CPU一样区分了很多标签,因此内存监控相较于CPU则需要结合很多个监控项
node_memory_MemFree_bytes //空闲内存
node_memory_MemTotal_bytes //总内存
node_memory_Cached_bytes //缓存
node_memory_Buffers_bytes //缓冲区内存
监控内存使用的思路:
1.空闲内存+缓存+缓冲区内存得出空闲总内存
2.得出的空闲总内存再除总内存大小再乘100,得出空闲率
3.再用100-空闲率就得出使用率
4.2.1.获取空闲内存
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes)

4.2.2.获取空闲内存率
(node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100

4.2.3.获取内存使用率
100 - ((node_memory_MemFree_bytes+node_memory_Cached_bytes+node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100)

4.3.监控磁盘使用率
关于磁盘使用率,这里我们用到的主要有:
node_filesystem_free_bytes //剩余磁盘空间
node_filesystem_size_bytes //磁盘空间总大小
这两个监控项中都有相同的标签可以关联,我们这里用到的标签有fstype,fstype标签值是关于磁盘的文件系统类型,对于磁盘监控,我们主要对xfs、ext4等文件系统的磁盘进行监控,像tmpfs这种的不必要监控,另一个主要的标签是mountpoint,这个标签值主要用来储存磁盘的挂载点,我们可以通过标签来选择要对那个挂载点的磁盘进行监控
磁盘使用率实现思路:
1.由磁盘空闲容量除磁盘总容量乘100即可得到磁盘空闲率
2.用100减磁盘空闲率即可得到磁盘使用率
在使用逻辑运算时最好习惯性加一个()防止错误
我们监控/目录的磁盘使用情况
4.3.1.获取磁盘空闲率
node_filesystem_free_bytes{fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"} *100
可以看到得出的结果和系统df命令查到的是一致的,空闲84,代表已经使用16

4.3.2.获取磁盘使用率
100 - (node_filesystem_free_bytes{fstype=~"ext4|xfs",mountpoint="/"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint="/"} *100)
所差不多

5.监控系统服务状态
监控服务的状态,例如nginx、docker这种服务器的启动状态
node_exporter是根据systemd去监控的,因此只有能用systemctl启动的服务器才能被监控到
配置非常简单,只需要在启动时开启system监控,并指定监控什么服务即可
配置system监控的参数:
–collector.systemd //开启system监控
–collector.systemd.unit-whitelist=".+" //对那些服务启动system监控,可以使用正则匹配
5.1.配置node_exporter启动参数
三台监控主机都要操作
vim /usr/lib/systemd/system/node_exporter.service
ExecStart=/data/node_exporter/node_exporter --collector.systemd --collector.systemd.unit-whitelist=(docker|sshd|node_exporter).service

重启服务
systemctl daemon-reload
systemctl restart node_exporter.service
5.2.查看服务的监控状态
以docker为例,我们查询docker存活状态
node_systemd_unit_state使用这个监控项查看,里面也有很多标签,name=“docker.service”,标签name表示服务的名称, state=“active”,state表示服务的状态,active表示活动的,对应的监控值也是1,如果为1则表示正常,不为1表示异常文章来源地址https://www.toymoban.com/news/detail-853588.html
node_systemd_unit_state{name="docker.service", state="active"}

存活状态文章来源:https://www.toymoban.com/news/detail-853588.html
node_systemd_unit_state使用这个监控项查看,里面也有很多标签,name=“docker.service”,标签name表示服务的名称, state=“active”,state表示服务的状态,active表示活动的,对应的监控值也是1,如果为1则表示正常,不为1表示异常
node_systemd_unit_state{name="docker.service", state="active"}到了这里,关于prometheus使用node_exporter监控Linux主机CPU、内存、磁盘、服务运行状况的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!