实时数据处理,从名字上看,很好理解,就是将数据进行实时处理,在现在流行的微服务开发中,最常用实时数据处理平台有 RabbitMQ、RocketMQ 等消息中间件。
这些中间件,最大的特点主要有两个:
-
服务解耦
-
流量削峰
在早期的 web 应用程序开发中,当请求量突然上来了时候,我们会将要处理的数据推送到一个队列通道中,然后另起一个线程来不断轮训拉取队列中的数据,从而加快程序的运行效率。

但是随着请求量不断的增大,并且队列通道的数据一致处于高负载,在这种情况下,应用程序的内存占用率会非常高,稍有不慎,会出现内存不足,造成程序内存溢出,从而导致服务不可用。
随着业务量的不断扩张,在一个应用程序内,使用这种模式已然无法满足需求,因此之后,就诞生了各种消息中间件,例如 ActiveMQ、RabbitMQ、RocketMQ等中间件。
采用这种模型,本质就是将要推送的数据,不在存放在当前应用程序的内存中,而是将数据存放到另一个专门负责数据处理的应用程序中,从而实现服务解耦。

消息中间件:主要的职责就是保证能接受到消息,并将消息存储到磁盘,即使其他服务都挂了,数据也不会丢失,同时还可以对数据消费情况做好监控工作。
应用程序:只需要将消息推送到消息中间件,然后启用一个线程来不断从消息中间件中拉取数据,进行消费确认即可!
引入消息中间件之后,整个服务开发会变得更加简单,各负其责。
Kafka 本质其实也是消息中间件的一种,Kafka 出自于 LinkedIn 公司,与 2010 年开源到 github。
LinkedIn 的开发团队,为了解决数据管道问题,起初采用了 ActiveMQ 来进行数据交换,大约是在 2010 年前后,那时的 ActiveMQ 还远远无法满足 LinkedIn 对数据传递系统的要求,经常由于各种缺陷而导致消息阻塞或者服务无法正常访问,为了能够解决这个问题,LinkedIn 决定研发自己的消息传递系统,Kafka 由此诞生。
在 LinkedIn 公司,Kafka 可以有效地处理每天数十亿条消息的指标和用户活动跟踪,其强大的处理能力,已经被业界所认可,并成为大数据流水线的首选技术。
二、架构介绍
======
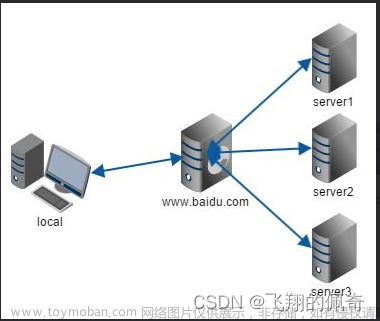
先来看一张图,下面这张图就是 kafka 生产与消费的核心架构模型!

如果你看不懂这些概念没关系,我会带着大家一起梳理一遍!
-
Producer:Producer 即生产者,消息的产生者,是消息的入口
-
Broker:Broker 是 kafka 一个实例,每个服务器上有一个或多个 kafka 的实例,简单的理解就是一台 kafka 服务器,kafka cluster表示集群的意思
-
Topic:消息的主题,可以理解为消息队列,kafka的数据就保存在topic。在每个 broker 上都可以创建多个 topic 。
-
Partition:Topic的分区,每个 topic 可以有多个分区,分区的作用是做负载,提高 kafka 的吞吐量。同一个 topic 在不同的分区的数据是不重复的,partition 的表现形式就是一个一个的文件夹!
-
Replication:每一个分区都有多个副本,副本的作用是做备胎,主分区(Leader)会将数据同步到从分区(Follower)。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为 Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本
-
Message:每一条发送的消息主体。
-
Consumer:消费者,即消息的消费方,是消息的出口。
-
Consumer Group:我们可以将多个消费组组成一个消费者组,在 kafka 的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
-
Zookeeper:kafka 集群依赖 zookeeper 来保存集群的的元信息,来保证系统的可用性。
简而言之,kafka 本质就是一个消息系统,与大多数的消息系统一样,主要的特点如下:
-
使用推拉模型将生产者和消费者分离
-
为消息传递系统中的消息数据提供持久性,以允许多个消费者
-
提供高可用集群服务,主从模式,同时支持横向水平扩展
与 ActiveMQ、RabbitMQ、RocketMQ 不同的地方在于,它有一个**分区Partition**的概念。
这个分区的意思就是说,如果你创建的topic有5个分区,当你一次性向 kafka 中推 1000 条数据时,这 1000 条数据默认会分配到 5 个分区中,其中每个分区存储 200 条数据。
这样做的目的,就是方便消费者从不同的分区拉取数据,假如你启动 5 个线程同时拉取数据,每个线程拉取一个分区,消费速度会非常非常快!
这是 kafka 与其他的消息系统最大的不同!
2.1、发送数据
========
和其他的中间件一样,kafka 每次发送数据都是向Leader分区发送数据,并顺序写入到磁盘,然后Leader分区会将数据同步到各个从分区Follower,即使主分区挂了,也不会影响服务的正常运行。

那 kafka 是如何将数据写入到对应的分区呢?kafka中有以下几个原则:
-
1、数据在写入的时候可以指定需要写入的分区,如果有指定,则写入对应的分区
-
2、如果没有指定分区,但是设置了数据的key,则会根据key的值hash出一个分区
-
3、如果既没指定分区,又没有设置key,则会轮询选出一个分区
2.2、消费数据
========
与生产者一样,消费者主动的去kafka集群拉取消息时,也是从Leader分区去拉取数据。
这里我们需要重点了解一个名词:消费组!

考虑到多个消费者的场景,kafka 在设计的时候,可以由多个消费者组成一个消费组,同一个消费组者的消费者可以消费同一个 topic 下不同分区的数据,同一个分区只会被一个消费组内的某个消费者所消费,防止出现重复消费的问题!
但是不同的组,可以消费同一个分区的数据!
你可以这样理解,一个消费组就是一个客户端,一个客户端可以由很多个消费者组成,以便加快消息的消费能力。
但是,如果一个组下的消费者数量大于分区数量,就会出现很多的消费者闲置。
如果分区数量大于一个组下的消费者数量,会出现一个消费者负责多个分区的消费,会出现消费性能不均衡的情况。
因此,在实际的应用中,建议消费者组的consumer的数量与partition的数量保持一致!
三、kafka 安装
==========
光说理论可没用,下面我们就以 centos7 为例,介绍一下 kafka 的安装和使用。
kafka 需要 zookeeper 来保存服务实例的元信息,因此在安装 kafka 之前,我们需要先安装 zookeeper。
3.1、安装zookeeper
===============
zookeeper 安装环境依赖于 jdk,因此我们需要事先安装 jdk
# 安装jdk1.8
yum -y install java-1.8.0-openjdk
下载zookeeper,并解压文件包
#在线下载zookeeper
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.4.12/zookeeper-3.4.12.tar.gz
#解压
tar -zxvf zookeeper-3.4.12.tar.gz
创建数据、日志目录
#创建数据和日志存放目录
cd /usr/zookeeper/
mkdir data
mkdir log
#把conf下的zoo_sample.cfg备份一份,然后重命名为zoo.cfg
cd conf/
cp zoo_sample.cfg zoo.cfg
配置zookeeper
#编辑zoo.cfg文件
vim zoo.cfg
重新配置dataDir和dataLogDir的存储路径

最后,启动 Zookeeper 服务
#进入Zookeeper的bin目录
cd zookeeper/zookeeper-3.4.12/bin
#启动Zookeeper
./zkServer.sh start
#查询Zookeeper状态
./zkServer.sh status
#关闭Zookeeper状态
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

复习的面试资料
这些面试全部出自大厂面试真题和面试合集当中,小编已经为大家整理完毕(PDF版)
- 第一部分:Java基础-中级-高级

- 第二部分:开源框架(SSM:Spring+SpringMVC+MyBatis)

- 第三部分:性能调优(JVM+MySQL+Tomcat)

- 第四部分:分布式(限流:ZK+Nginx;缓存:Redis+MongoDB+Memcached;通讯:MQ+kafka)

- 第五部分:微服务(SpringBoot+SpringCloud+Dubbo)

- 第六部分:其他:并发编程+设计模式+数据结构与算法+网络

进阶学习笔记pdf
- Java架构进阶之架构筑基篇(Java基础+并发编程+JVM+MySQL+Tomcat+网络+数据结构与算法)

- Java架构进阶之开源框架篇(设计模式+Spring+SpringMVC+MyBatis)



- Java架构进阶之分布式架构篇 (限流(ZK/Nginx)+缓存(Redis/MongoDB/Memcached)+通讯(MQ/kafka))



- Java架构进阶之微服务架构篇(RPC+SpringBoot+SpringCloud+Dubbo+K8s)


《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
*
[外链图片转存中…(img-I5Z78K9C-1712558670720)]
[外链图片转存中…(img-gvVN29n9-1712558670721)]
[外链图片转存中…(img-JFiefJnC-1712558670721)]
- Java架构进阶之微服务架构篇(RPC+SpringBoot+SpringCloud+Dubbo+K8s)
[外链图片转存中…(img-cvqF6ofU-1712558670721)]
[外链图片转存中…(img-ZYl9qdL8-1712558670721)]文章来源:https://www.toymoban.com/news/detail-853650.html
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!文章来源地址https://www.toymoban.com/news/detail-853650.html
到了这里,关于3分钟带你彻底搞懂 Kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!