一、摘要
摘要:DreamFusion 最近展示了使用预训练的文本到图像扩散模型来优化神经辐射场 (NeRF) 的实用性,实现了显着的文本到 3D 合成结果。然而,该方法有两个固有的局限性:(a)NeRF 的优化极慢和(b)NeRF 上的低分辨率图像空间监督,导致处理时间长的低质量 3D 模型。在本文中,我们通过利用两阶段优化框架来解决这些限制。首先,我们使用低分辨率扩散先验获得粗略模型,并使用稀疏 3D 哈希网格结构进行加速。使用粗略表示作为初始化,我们进一步优化了纹理 3D 网格模型,该模型具有与高分辨率潜在扩散模型交互的高效可微渲染器。我们的方法被称为 Magic3D,可以在 40 分钟内创建高质量的 3D 网格模型,比 DreamFusion 快 2 倍(据报道平均需要 1.5 小时),同时还实现了更高的分辨率。用户研究显示 61.7% 的评分者更喜欢我们的方法而不是 DreamFusion。结合图像条件生成功能,我们为用户提供了控制 3D 合成的新方法,为各种创意应用开辟了新途径。
二、地址
标题:Magic3D: High-Resolution Text-to-3D Content Creation
论文:https://arxiv.org/abs/2211.10440
demo展示(此地址还还可以访问):https://deepimagination.cc/Magic3D/
三、方法
DreamFusion是目前基于文本的3D生成任务的主流方法,但它有两个重要缺陷:
1)NeRF收敛速度慢;
2)用于监督NeRF训练的图片质量较差,导致生成的3D目标质量较差。
对于上述两个问题,本文提出:1)用Instant-NGP替换DreamFusion中的NeRF;
2)提出一种两阶段Coarse-to-fine的优化方法:
第一步:基于Instant NGP表示低分辨率的3D物体,通过eDiff-I计算L_SDS,它类似于DreamFusion中使用的Imagen的基础扩散模型,这种扩散先验被用于通过在低分辨率64 × 64的渲染图像上定义的损失来计算场景模型的梯度,更新NeRF;
第二步:使用潜在扩散模型(LDM),允许梯度反向传播到高分辨率512 × 512的渲染图像,实验中选择使用公开的stable diffusion model。用DMTet提取初始3D mesh,其次采样和渲染高分辨率图片,并和第一步类似,更新3D mesh。
上面简单来说:
第一阶段,利用低分辨率扩散先验并优化神经场表示(颜色、密度和正常场)来获得粗模型。
第二阶段:从粗模型的密度场和颜色场中提取纹理三维网格。然后用高分辨率潜在扩散模型对其进行微调。
经过优化后,模型生成了具有详细纹理的高质量3D网格。以从粗到细的方式从输入文本提示生成高分辨率的3D内容。
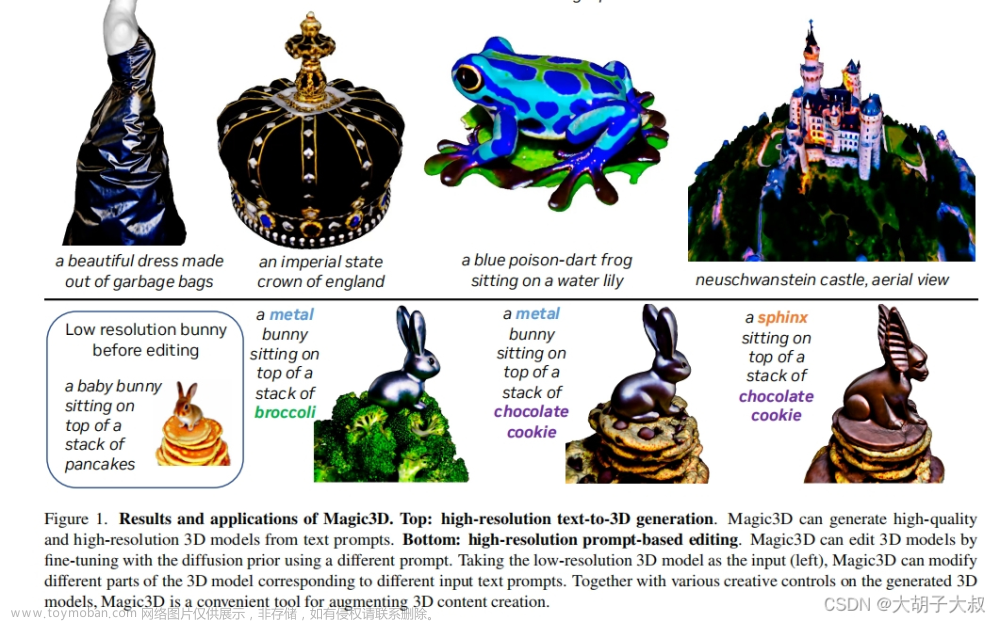
四、实现过程
DreamBooth描述了一种方法,通过对一个主题的几张图像微调预先训练的模型,来个性化文本到图像扩散模型。经过微调的模型可以学习将主题绑定到一个唯一的标识符字符串(记为[V]),并在文本提示中包含[V]时生成主题的图像。在文本到3D生成的上下文中,希望生成主题的3D模型。这可以通过首先使用DreamBooth方法微调扩散先验模型来实现,然后使用带有[V]标识符的微调扩散先验作为条件文本提示的一部分,在优化3D模型时提供学习信号。
为了证明DreamBooth在论文框架中的适用性,收集了一只猫的11张图像和一只狗的4张图像。微调eDiff-I和LDM,将文本标识符[V]绑定到给定的主题。然后在文本提示中用[V]对三维模型进行优化。使用批处理大小为1进行所有微调。对于eDiff-I,使用学习率为1 × 10−5的Adam优化器进行1500次迭代;对于LDM,对800次迭代的学习率进行微调,学习率为1 × 10−6。下图显示了个性化文本到3D结果:能够成功地修改3D模型,在给定的输入图像中保留主题。

五、GPU
使用8块A100
coarse stage训练5000 iter,大概训练15分钟;
fine stage训练3000 iter,大概训练25分钟。文章来源:https://www.toymoban.com/news/detail-853865.html
六、结论
我们提出了Magic3D,这是一个快速、高质量的文本到3D生成框架。我们以从粗到细的方法从高效的场景模型和高分辨率的扩散先验中获益。特别是,3D网格模型可以很好地与图像分辨率进行缩放,并在不牺牲其速度的情况下享受潜在扩散模型带来的高分辨率监督的好处。从atext提示到准备用于图形引擎的高质量3D网格模型需要40分钟。通过广泛的用户研究和定性比较,我们发现与DreamFusion相比,Magic3D更受评分者的青睐(61.7%),同时速度提高了2倍。最后,我们提出了一套在三维生成中更好地控制样式和内容的工具。我们希望通过Magic3D,我们可以使3D合成民主化,并在3D内容创作中打开每个人的创造力。文章来源地址https://www.toymoban.com/news/detail-853865.html
到了这里,关于英伟达文本生成3D模型论文:Magic3D: High-Resolution Text-to-3D Content Creation解读的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!