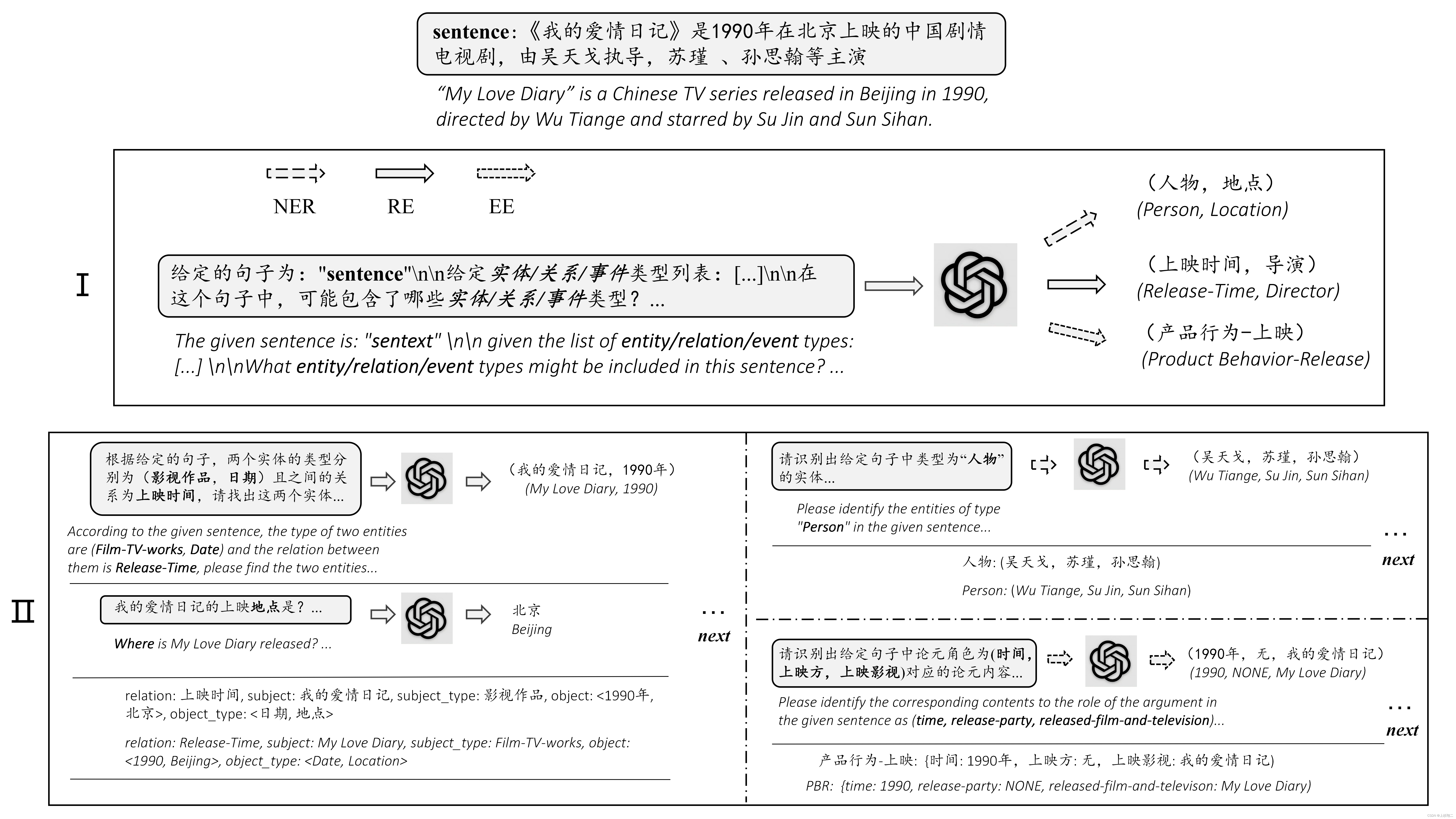
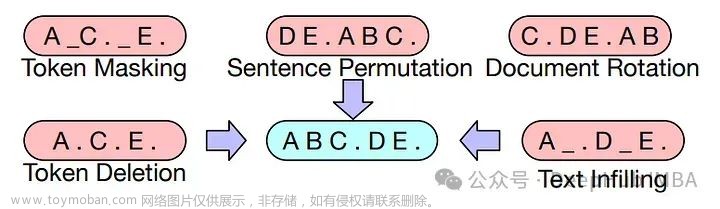
本文将介绍大语言模型中使用的不同令牌遮蔽技术,并比较它们的优点,以及使用Pytorch实现以了解它们的底层工作原理。
令牌掩码Token Masking是一种广泛应用于语言模型分类变体和生成模型训练的策略。BERT语言模型首先使用,并被用于许多变体(RoBERTa, ALBERT, DeBERTa…)。
而Text Corruption是一种更大的令牌遮蔽策略。在BART研究论文中,进行了大量实验来训练具有不同策略的编码器-解码器生成模型。
在进入正题之前,我们先介绍大型语言模型(llm)中掩码策略的背景
从监督到自监督
语言模型的初始训练中使用了大量文本,其目标是使模型学会正确地表示语言,并将这种知识隐式地存储在其参数权重中。
大量的文本必须具有用于训练的标签,因为必须在处理模型输入数据并使用参考数据之后计算损失(交叉熵)。但是注释如此大量的数据是不可行的。所以智能将问题从监督学习变为自动生成标签的自监督问题。
在这种情况下,被破坏的文本序列作为模型的训练输入,而所有或部分原始序列作为训练数据的标签。这样通过自动生成的标签,模型学习与每个训练示例关联的标签,就不需要手动的注释数据。
在Text Corruption中(特别是在Token Masking、Token Deletion和Text Infilling中),每个单词可能会按照固定概率(通常约为15-20%)进行遮蔽。这个概率保持较低,以便模型即使在序列被损坏的情况下也能学习每个句子的上下文。
还有一些技术,如Sentence Permutation 或Document Rotation,不会专注于按照一定概率遮蔽单词,我们后面会介绍。
在训练语言模型时,标签会根据是分类模型(仅编码器)还是生成模型(编码器-解码器)而变化。在分类模型中,使用的标签只关注输入中被遮蔽的区域。因此如果一个词在整个句子中被屏蔽,标签只是单个单词。而对于生成模型,由于模型必须能够连续生成文本,输出标签是初始未损坏的序列,关注整个序列本身。
环境配置
我们已经简要介绍了使用Text Corruption训练语言模型的一些背景知识,下面我们开始使用示例代码来介绍不同的Text Corruption技术。
我们将使用Stanza,一个由斯坦福NLP开发的库,其中包含不同的NLP工具,这些工具对我们的预处理非常有用。
importstanza
stanza.download('en')
# Text used in our examples
text="Huntington's disease is a neurodegenerative autosomal disease
resultsduetoexpansionofpolymorphicCAGrepeatsinthehuntingtingene.
Phosphorylationofthetranslationinitiationfactor4E-BPresultsinthe
alterationofthetranslationcontrolleadingtounwantedproteinsynthesis
andneuronalfunction. Consequencesofmutanthuntington (mhtt) gene
transcriptionarenotwellknown. Variabilityofageofonsetisan
importantfactorofHuntington's disease separating adult and juvenile types.
Thefactorswhicharetakenintoaccountare-geneticmodifiers, maternal
protectioni.eexcessivepaternaltransmission, superiorageinggenes
andenvironmentalthreshold. Amajorfocushasbeengiventothemolecular
pathogenesiswhichincludes-motordisturbance, cognitivedisturbanceand
neuropsychiatricdisturbance. Thediagnosisparthasalsobeentakencareof.
Thisincludesgenetictestingandbothprimaryandsecondarysymptoms.
ThepresentreviewalsofocusesonthegeneticsandpathologyofHuntington's
disease."
# We will use a stanza model for getting each different sentence
# as an element of the list
nlp=stanza.Pipeline('en', use_gpu=False)
doc=nlp(text)
sentences= [sentence.textforsentenceindoc.sentences]
Token Masking
令牌掩码用替换文本中的随机单词

这是从BERT引入的策略,它包括通过屏蔽随机单词来破坏输入序列,这些单词将在训练期间用作输出标签。
在分类模型中,我们可以直接使用Huggingface的DataCollatorForLanguageModeling类来生成必要的标签,这样就可以训练像BERT或RoBERTa这样的模型。
fromtransformersimportAutoTokenizer, DataCollatorForLanguageModeling
importtorch
defload_dataset_mlm(sentences, tokenizer_class=AutoTokenizer,
collator_class=DataCollatorForLanguageModeling,
mlm=True, mlm_probability=0.20):
tokenizer=tokenizer_class.from_pretrained('google-bert/bert-base-uncased')
inputs=tokenizer(sentences, return_tensors='pt', padding=True,
truncation=True)
# Random masking configuration
data_collator=collator_class(
tokenizer=tokenizer,
mlm=mlm,
mlm_probability=mlm_probability
)
"""The collator expects a tuple of tensors, so you have to split
the input tensors and then remove the first dimension and pass it
to a tuple. """
tuple_ids=torch.split(inputs['input_ids'], 1, dim=0)
tuple_ids=list(tuple_ids)
fortensorinrange(len(tuple_ids)):
tuple_ids[tensor] =tuple_ids[tensor].squeeze(0)
tuple_ids=tuple(tuple_ids)
# Get input_ids, attention_masks and labels for each sentence.
batch=data_collator(tuple_ids)
returnbatch['input_ids'], inputs['attention_mask'], batch['labels']
input_ids, attention_mask, labels=load_dataset_mlm(sentences)
"""
input_ids[0]:
tensor([ 101, 16364, 1005, 1055, 103, 2003, 1037, 103, 10976, 3207,
103, 25284, 103, 25426, 16870, 4295, 3463, 2349, 2000, 103,
1997, 26572, 18078, 6187, 2290, 17993, 1999, 1996, 5933, 7629,
103, 103, 102, 0, 0])
attention_mask[0]:
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0])
labels[0]:
tensor([ -100, -100, -100, -100, 4295, -100, -100, 11265, -100, -100,
6914, -100, 8285, -100, 2389, -100, -100, -100, -100, 4935,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
4962, 1012, -100, -100, -100]))
"""
生成的inputs_ids对原始文本的每个标记都是整数。一个特殊的标记表示被屏蔽的单词(在BERT中,这个标记是103)。这个特殊的标记根据所使用的语言模型而变化,因此不同的标记器将返回注意掩码的不同标识符。
Huggingface还在模型中使用不同的操作分配唯一的令牌,因此用“-100”表示的令牌表示模型应该忽略它们。
对于像BART这样的生成模型,我们可以使用DataCollatorForLanguageModeling类实现令牌屏蔽策略。但是需要一些小的更改,以使标记适应生成模型。
fromtransformersimportBartTokenizer, DataCollatorForLanguageModeling
importtorch
defload_dataset_mlm(sentences, tokenizer_class=BartTokenizer,
collator_class=DataCollatorForLanguageModeling,
mlm=True, mlm_probability=0.20):
tokenizer=tokenizer_class.from_pretrained('facebook/bart-base')
inputs=tokenizer(sentences, return_tensors='pt', padding=True,
truncation=True)
# Random masking configuration
data_collator=collator_class(
tokenizer=tokenizer,
mlm=mlm, # True for Masked Language Modelling
mlm_probability=mlm_probability # Chance for every token to get masked
)
"""The collator expects a tuple of tensors, so you have to split
the input tensors and then remove the first dimension and pass it
to a tuple. """
tuple_ids=torch.split(inputs['input_ids'], 1, dim=0)
tuple_ids=list(tuple_ids)
fortensorinrange(len(tuple_ids)):
tuple_ids[tensor] =tuple_ids[tensor].squeeze(0)
tuple_ids=tuple(tuple_ids)
# Get input_ids, attention_masks and labels for each sentence.
batch=data_collator(tuple_ids)
batch['labels'] =inputs['input_ids']
returnbatch['input_ids'], inputs['attention_mask'], batch['labels']
input_ids, attention_mask, labels=load_dataset_mlm(sentences)
"""
input_ids[0]:
tensor([ 0, 38831, 2577, 1054, 18, 2199, 16, 10, 14913, 28904,
5777, 3693, 32226, 38868, 2199, 775, 528, 7, 2919, 9,
48052, 636, 230, 3450, 35315, 11, 5, 50264, 50264, 50264,
4, 2])
attention_mask[0]:
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1])
labels[0]:
tensor([ 0, 38831, 2577, 1054, 18, 2199, 16, 10, 14913, 28904,
5777, 3693, 32226, 38868, 2199, 775, 528, 7, 2919, 9,
48052, 636, 230, 3450, 35315, 11, 5, 8217, 24276, 10596,
4, 2])
"""
每个输入标记都标记着与之对应的标记,无论它是否被屏蔽。这是因为与分类模型不同,模型必须能够基于给定给模型的序列生成文本序列。在BART的情况下,表示屏蔽的标记的ID是50264。
Token Deletion
使用标记删除 Token Deletion,模型必须学习确切的位置和缺失的词是什么,因此它必须比仅使用Token Masking学习更多的特征。

这种策略使用了一种不同的屏蔽方法。以一定的概率一个词从原始文本序列中被移除,因此模型必须找到缺失的单词及其位置。标准的屏蔽方法不会学习位置,因为屏蔽已经在模型的输入中指示
deftoken_deletion(sentences, tokenizer_class=BartTokenizer, collator_class=DataCollatorForLanguageModeling,
mlm=True, mlm_probability=0.20):
tokenizer=tokenizer_class.from_pretrained('facebook/bart-base')
inputs=tokenizer(sentences, return_tensors='pt', padding=True, truncation=True)
data_collator=collator_class(
tokenizer=tokenizer,
mlm=mlm,
mlm_probability=mlm_probability
)
tuple_ids=torch.split(inputs['input_ids'], 1, dim=0)
tuple_ids=list(tuple_ids)
fortensorinrange(len(tuple_ids)):
tuple_ids[tensor] =tuple_ids[tensor].squeeze(0)
tuple_ids=tuple(tuple_ids)
batch=data_collator(tuple_ids)
# We use the initial inputs as labels
batch['labels'] =batch['input_ids'].clone()
# We remove tokens with mask identifier and thus make token deletion
# Change the value to the mask identifier of the specific token model
# It is necessary to know the identifier of the mask token for
# that specific model
mask=batch['input_ids'] !=50264
initial_size=batch['input_ids'].size(1)
total_sentences=batch['input_ids'].size(0)
# When we remove the specific token, we must fill with the padding
# token otherwise the tensor size is not respected.
foriinrange(total_sentences):
new_tensor=batch['input_ids'][i][mask[i]]
new_tensor=F.pad(new_tensor, (0, initial_size-new_tensor.size(0)), value=1)
batch['input_ids'][i] =new_tensor
attention_mask=batch['input_ids'][i] ==1
inputs['attention_mask'][i][attention_mask] =0
returnbatch['input_ids'], inputs['attention_mask'], batch['labels']
input_ids, attention_mask, labels=token_deletion(sentences)
"""
input_ids[0]:
tensor([ 0, 38831, 2577, 1054, 2199, 14913, 28904, 3693, 32226, 38868,
2199, 775, 528, 7, 2919, 9, 23404, 636, 230, 35315,
11, 5, 24276, 10596, 4, 2, 1, 1, 1, 1,
1, 1])
attention_mask[0]:
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 0, 0, 0, 0, 0, 0])
labels[0]:
tensor([ 0, 38831, 2577, 1054, 50264, 2199, 50264, 50264, 14913, 28904,
50264, 3693, 32226, 38868, 2199, 775, 528, 7, 2919, 9,
23404, 636, 230, 50264, 35315, 11, 5, 50264, 24276, 10596,
4, 2])
"""
当使用Token Deletion训练BART时,长序列用于问答、摘要生成任务和会话任务会有一定的提高。
Text Infilling
文本填充 Text Infilling允许模型学习每个屏蔽位置可以有多少个单词。而先前的方法假设每个屏蔽位置只有一个单词。

Text Infilling与Token Masking类似,因为我们会以一定的概率在原始文本上使用屏蔽。但是不同之处在于屏蔽可以覆盖多个单词。在BART中,屏蔽是用泊松分布 lambda = 3 进行的;这意味着平均而言,每次对句子中的文本进行屏蔽时,会有三个单词被包含在一个单个的标记中,但由于这是一个概率分布,可能会有更多或更少的屏蔽单词。

我们将使用Numpy库和特定于我们的语言模型(在本例中是BART)的标记器来实现文本填充。
importnumpyasnp
fromtransformersimportBartTokenizer
deftext_infilling(sentence, probability=0.2, poisson_lambda=3):
# We'll use a binary mask to determine which words to replace
mask=np.random.choice([0, 1], size=len(sentence), p=[1-probability, probability])
# Now we'll replace the chosen words with a mask token
# We'll also use a Poisson distribution to determine the length of the spans to mask
foriinrange(len(mask)):
ifmask[i] ==1:
span_length=np.random.poisson(poisson_lambda)
forjinrange(span_length):
ifi+j<len(sentence):
sentence[i+j] ="<mask>"
infilled_sentence= []
fortokeninrange(len(sentence)):
ifsentence[token] =="<mask>":
iftoken<len(sentence)-1:
ifsentence[token+1] =="<mask>":
continue
else:
infilled_sentence.append(sentence[token])
else:
infilled_sentence.append(sentence[token])
else:
infilled_sentence.append(sentence[token])
return" ".join(infilled_sentence)
deftext_infilling_input(masked_sentences, sentences, tokenizer_class=BartTokenizer):
tokenizer=tokenizer_class.from_pretrained('facebook/bart-base')
inputs=tokenizer(masked_sentences, return_tensors='pt', padding=True, truncation=True)
labels=tokenizer(sentences, return_tensors='pt', padding=True, truncation=True)
returninputs['input_ids'], inputs['attention_mask'], labels['input_ids']
input_ids, attention_mask, labels=text_infilling_input(masked_sentences, sentences)
"""
input_ids[0]:
tensor([ 0, 50264, 16, 50264, 2199, 775, 528, 50264, 48052, 636,
50264, 8217, 24276, 10596, 4, 2, 1, 1, 1, 1,
1, 1, 1])
attention_mask[0]:
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0])
labels[0]:
tensor([ 0, 38831, 2577, 1054, 18, 2199, 16, 10, 14913, 28904,
5777, 3693, 32226, 38868, 2199, 775, 528, 7, 2919, 9,
48052, 636, 230, 3450, 35315, 11, 5, 8217, 24276, 10596,
4, 2])
"""
Text Infilling比Token Deletion更能改善BART语言模型的结果,在问题回答、文本摘要和会话任务中提供更好的生成。
Sentence Permutation
语言模型的输入文本被分成随机重新排列的句子,模型需要找出原始的顺序。

在Sentence Permutation中,考虑适合模型输入序列的句子数量是至关重要的(在小型模型中,输入序列在512到1024之间)。在确定符合序列的句子数量之后,需要将它们分离到一个列表或数组中,并随机选择,而不重复其中任何一个。
# It selects the first "number_sentences" within a given set of "sentences"
# and returns those sentences in a random order.
defsentence_permutation(sentences, number_sentences):
new_sentences=sentences[:number_sentences]
random.shuffle(new_sentences)
new_sentences=sentence_joiner(new_sentences)
returnnew_sentences
defpermuted_data_generation(sentences: list, total_sentences: int):
training_sentences= []
training_labels= []
sentences_copy=sentences.copy()
# We can apply sentence_permutation a number of times equal to the
# size of the list - 1 to get an example with each new sentence in
# the text, removing the oldest one.
for_inrange(len(sentences)-total_sentences+1):
new_sentences=sentence_permutation(sentences_copy, total_sentences)
joined_sentences=sentence_joiner(sentences_copy[:total_sentences])
sentences_copy=sentences_copy[1:]
training_sentences.append(new_sentences)
training_labels.append(joined_sentences)
returntraining_sentences, training_labels
defpermutation_training(sentences: list, sentences_labels: list,
tokenizer_class=BartTokenizer,
collator_class=DataCollatorForLanguageModeling,
mlm=True, mlm_probability=0.0):
# We get input_ids and attention mask from the permuted sentences
input, attention_mask, _=load_dataset_mlm(sentences, tokenizer_class, collator_class, mlm, mlm_probability)
# Labels from the original sentences
labels, _, _=load_dataset_mlm(sentences_labels, tokenizer_class, collator_class, mlm, mlm_probability)
returninput.squeeze(0), attention_mask.squeeze(0), labels.squeeze(0)
input_ids, attention_mask, labels=permutation_training(training_sentences, training_labels_sentences)
"""
input_ids[0]:
tensor([ 0, 38831, 2577, 1054, 18, 2199, 16, 10, 14913, 28904,
5777, 3693, 32226, 38868, 2199, 775, 528, 7, 2919, 9,
48052, 636, 230, 3450, 35315, 11, 5, 8217, 24276, 10596,
4, 2585, 33430, 8457, 9, 41419, 8217, 1054, 36, 119,
49491, 43, 10596, 37118, 32, 45, 157, 684, 4, 4129,
33839, 4405, 35019, 9, 5, 19850, 34939, 3724, 204, 717,
12, 21792, 775, 11, 5, 39752, 9, 5, 19850, 797,
981, 7, 15067, 8276, 37423, 8, 46282, 5043, 4, 2])
attention_mask[0]:
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1])
labels[0]:
tensor([ 0, 38831, 2577, 1054, 18, 2199, 16, 10, 14913, 28904,
5777, 3693, 32226, 38868, 2199, 775, 528, 7, 2919, 9,
48052, 636, 230, 3450, 35315, 11, 5, 8217, 24276, 10596,
4, 4129, 33839, 4405, 35019, 9, 5, 19850, 34939, 3724,
204, 717, 12, 21792, 775, 11, 5, 39752, 9, 5,
19850, 797, 981, 7, 15067, 8276, 37423, 8, 46282, 5043,
4, 2585, 33430, 8457, 9, 41419, 8217, 1054, 36, 119,
49491, 43, 10596, 37118, 32, 45, 157, 684, 4, 2])
"""
我们对于模型的每个数据输入,删除原始序列中出现的第一个句子,然后在执行基于要选择的固定句子数目的句子排列之前,将接下来的句子添加进去。这样虽然重新排列了输入序列中的句子,但保持了一个每个新例子中都会出现一个新的句子,并删除最旧的句子的上下文窗口。
Document Rotation
当旋转一个文档时,选择一个特定的词,并将其设定为起始词,而所有之前的词都被粘贴到文本的末尾。

如果要应用Document Rotation,必须考虑到每个批次使用的维度。在应用填充的情况下,这个填充不能与文档的其余部分一起旋转,而是必须保持其原始位置,同时整个文档旋转。
defsentence_joiner(sentences: list):
return' '.join(sentences)
# With this function we gather as many sentences as we want to form the input data to the tokenizer.
defrotated_data_generation(sentences: list, total_sentences: int):
training_sentences= []
sentences_copy=sentences.copy()
for_inrange(len(sentences)-total_sentences+1):
new_sentences=sentences_copy[:total_sentences]
new_sentences=sentence_joiner(new_sentences)
sentences_copy=sentences_copy[1:]
training_sentences.append(new_sentences)
returntraining_sentences
# Apply this function over the rotated sentences from previous function
defdocument_rotation_training(sentences, tokenizer_class=BartTokenizer):
tokenizer=tokenizer_class.from_pretrained('facebook/bart-base')
tokens=tokenizer(sentences, return_tensors='pt', padding=True, truncation=True)
tokens['input_ids'] =tokens['input_ids'].squeeze(0)
tokens['labels'] =tokens['input_ids'].clone()
iterations=tokens['input_ids'].size(0)
foriinrange(iterations):
# Get the attention mask and convert to list
attention_mask=tokens['attention_mask'][i].tolist()
# Calculate the position where padding starts
if0inattention_mask:
padding_start_position=attention_mask.index(0)
else:
padding_start_position=False
# We take into account the position of the padding so as not to rotate it along with the rest of the document.
ifpadding_start_position:
random_token=torch.randint(1, padding_start_position-1, (1,))
tokens['input_ids'][i] =torch.cat((tokens['input_ids'][i][0].unsqueeze(0), #initial token
tokens['input_ids'][i][random_token.item():padding_start_position-1], #from random to padding
tokens['input_ids'][i][1:random_token.item()], #from 1 to random
tokens['input_ids'][i][padding_start_position-1:-1],
tokens['input_ids'][i][-1].unsqueeze(0)), 0)
# If there is no padding, we rotate the document without taking the padding into account.
else:
random_token=torch.randint(1, tokens['input_ids'].size(0)-1, (1,))
tokens['input_ids'][i] =torch.cat((tokens['input_ids'][i][0].unsqueeze(0), #initial token
tokens['input_ids'][i][random_token.item():-1], #from random to end
tokens['input_ids'][i][1:random_token.item()],
tokens['input_ids'][i][-1].unsqueeze(0)), 0)
returntokens['input_ids'], tokens['attention_mask'].squeeze(0), tokens['labels']
data=rotated_data_generation(sentences, 3)
input_ids, attention_mask, labels=document_rotation_training(data)
"""
input_ids[2]:
tensor([ 0, 2433, 61, 32, 551, 88, 1316, 32, 12, 4138,
15557, 47605, 6, 22835, 2591, 939, 4, 242, 10079, 38422,
9235, 6, 10295, 22540, 14819, 8, 3039, 11543, 4, 347,
37347, 8457, 9, 41419, 8217, 1054, 36, 119, 49491, 43,
10596, 37118, 32, 45, 157, 684, 4, 41058, 4484, 9,
1046, 9, 23808, 16, 41, 505, 3724, 9, 18073, 18,
2199, 18246, 4194, 8, 13430, 3505, 4, 20, 2, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
attention_mask[2]:
tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0])
labels[2]:
tensor([ 0, 347, 37347, 8457, 9, 41419, 8217, 1054, 36, 119,
49491, 43, 10596, 37118, 32, 45, 157, 684, 4, 41058,
4484, 9, 1046, 9, 23808, 16, 41, 505, 3724, 9,
18073, 18, 2199, 18246, 4194, 8, 13430, 3505, 4, 20,
2433, 61, 32, 551, 88, 1316, 32, 12, 4138, 15557,
47605, 6, 22835, 2591, 939, 4, 242, 10079, 38422, 9235,
6, 10295, 22540, 14819, 8, 3039, 11543, 4, 2, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1])
"""
类似于序列排列,我们可以在每个数据输入中移除最旧的句子,并添加一个新句子,从而保持上下文窗口。
总结
本文介绍了讨论了训练语言模型的不同的令牌掩码。虽然这些都是比较常见的方法,但是大多数模型只使用了Token Masking。
对于短文本序列来说,Sentence Permutation 和Document Rotation技术可能没有帮助甚至会降低准确率。而Token Masking、Token Deletion和Text Infilling 在短文本和长文本序列中都可以使用。
https://avoid.overfit.cn/post/1b9d2c9d6b9a4bacbe6fa906c23aee7f文章来源:https://www.toymoban.com/news/detail-853950.html
作者:Fabio Yáñez Romero文章来源地址https://www.toymoban.com/news/detail-853950.html
到了这里,关于5种常用于LLM的令牌遮蔽技术介绍以及Pytorch的实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!