1.Hadoop 生态圈组件
Hadoop是一个分布式系统基础架构,具备可靠、高效、可伸缩等特点。它的核心设计是HDFS、MapReduce。
1.1.HDFS(分布式文件系统)
HDFS是整个hadoop体系的基础,负责数据的存储与管理。HDFS有着高容错性(fault-tolerant)的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
1.2.MapReduce(分布式计算框架)
MapReduce是一种基于磁盘的分布式并行批处理计算模型,用于处理大数据量的计算。其中Map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,Reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
1.3.Spark(分布式计算框架)
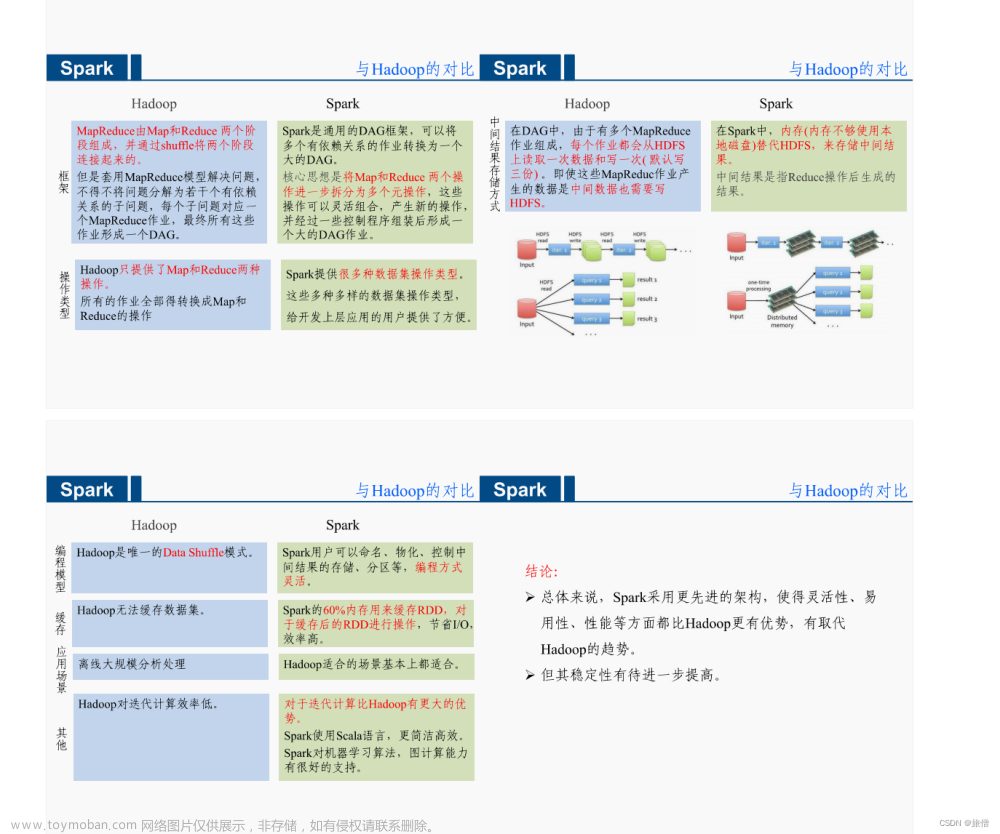
Spark是一种基于内存的分布式并行计算框架,不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
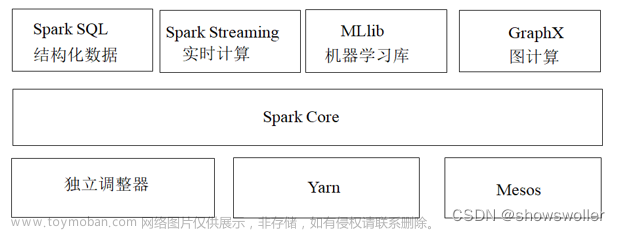
1.4.Yarn/Mesos(分布式资源管理器)
YARN是下一代MapReduce,即MRv2,是在第一代MapReduce基础上演变而来的,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
Mesos诞生于UC Berkeley的一个研究项目,现已成为Apache项目,当前有一些公司使用Mesos管理集群资源,比如Twitter。与yarn类似,Mesos是一个资源统一管理和调度的平台,同样支持比如MR、steaming等多种运算框架。
2.mapreduce
2.1.MapReduce的定义
MapReduce是一个分布式运算程序的编程框架,核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个Hadoop集群上。
2.2 MapReduce优缺点
.2.2.1 优点
(1)易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。
(2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
(3)高容错性
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上,这就要求它具有很高
的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行, 不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由 Hadoop 内部完成的。
(4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
2.2.2 缺点
(1)不擅长实时计算
MapReduce 无法像 MySQL 一样,在毫秒或者秒级内返回结果。
(2)不擅长流式计算
流式计算的输入数据是动态的,而 MapReduce 的输入数据集是静态的,不能动态变化。
这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。
(3)不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,
MapReduce 并不是不能做,而是使用后,每个 MapReduce 作业的输出结果都会写入到磁盘, 会造成大量的磁盘 IO,导致性能非常的低下。
2.3. MapReduce核心思想
分布式的运算程序往往需要分成至少2个阶段。
2.3.1.第一个阶段的MapTask并发实例,完全并行运行,互不相干。
2.3.2.第二个阶段的ReduceTask并发实例互不相干,但是他们的数据依赖于上一个阶段的所有MapTask并发实例的输出。
2.3.3MapReduce编程模型只能包含一个Map阶段和一个Reduce阶段,如果用户的业务逻辑非常复杂,那就只能多个MapReduce程序,串行运行。
3.spark技术特点和概述
Spark是用于大规模数据处理的统一分析引擎,其具有如下特点:
3.1.快速
Spark 使用DAG执行引擎以支持循环数据流与内存计算,其在内存中的运算速度是 Hadoop MapReduce运行速度的 100 多倍,在硬盘中是 Hadoop MapReduce的 10 多倍。
3.2.易用
支持使用scala、Java、python、R等语言进行编程,
3.3.通用
spark提供完整强大的技术栈,包括Spark SQL(SQL查询)、Spark Streaming(流式计算)、MLib (机器学习)及 GraphX(图算法)等
3.4.随机运行
支持多种运行方式
4.对比mapreduce和spark的区别
4.1. mapreduce是基于磁盘的,spark是基于内存的。mapreduce会产生大量的磁盘IO,而 spark基于DAG计算模型,会减少Shaffer过程即磁盘IO减少。
4.2.spark是多线程运行,mapreduce是多进程运行。进程的启动和关闭和会耗费一定的时间。
4.3.兼容性:spark可单独也可以部署为on yarn模式,mapreduce一般都是on yarn模式
4.4.shuffle与排序,mapreduce有reduce必排序
4.5.spark有灵活的内存管理和策略
5.结构化数据与非结构化数据是什么?
5.1.结构化数据
结构化数据:也称行数据,指可以使用关系型数据库表示和存储,表现为二维形式的数据。
特点:数据以行为单位,一行数据表示一个实体的信息,每一行数据的属性是相同的。
5.2.非结构化数据
非结构化数据:指数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、各类报表、图像和音频/视频信息等等
6.Linux简单操作命令实训练习
6.1实验任务一:文件与目录操作
6.1.1步骤一:pwd 命令

6.1.2步骤二:ls 命令

6.1.3步骤三:cd 命令

6.1.4步骤四:mkdir 命令

6.1.5步骤五:rm 命令

6.1.6步骤六:cp 命令

6.1.7步骤七:mv 命令

6.1.8步骤八:cat 命令

6.1.9步骤九:tar 命令
6.2实验任务二:用户操作
6.2.1步骤一:useradd 命令

6.2.2步骤二:passwd 命令

6.2.3步骤三:chown 命令

6.2.4步骤四:chmod 命令

6.2.5步骤五:su 命令文章来源:https://www.toymoban.com/news/detail-854036.html
 文章来源地址https://www.toymoban.com/news/detail-854036.html
文章来源地址https://www.toymoban.com/news/detail-854036.html
到了这里,关于spark hadoop的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!