hadoop作为一个开源的分布式计算和存储框架,在人工智能、大数据领域有非常广泛的应用。笔者在查阅资料发现网络博客介绍的配置方法大多需要借助虚拟机,或者需要重新创建ubuntu账户并设置密码为空以避免hadoop连接不上的问题,甚至是在ubuntu系统内再搭建一个虚拟机的ubuntu系统,太麻烦。
本文介绍一种直接在ubuntu系统上配置hadoop的方法,亲测有效,希望能帮到读者。
一、安装包下载
hadoop下载网址
Apache Download MirrorsHome page of The Apache Software Foundationhttps://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.2.3/hadoop-3.2.3.tar.gz
spark下载网址
Apache Download MirrorsHome page of The Apache Software Foundationhttps://www.apache.org/dyn/closer.lua/spark/spark-3.2.4/spark-3.2.4-bin-without-hadoop.tgz笔者使用的hadoop版本号是hadoop-3.2.3,spark版本号是spark-3.2.4-bin-without-hadoop,注意如果读者自行安装时选择了hadoop的其他版本,请保证spark版本号和hadoop相匹配,是否匹配可查阅spark官网信息。
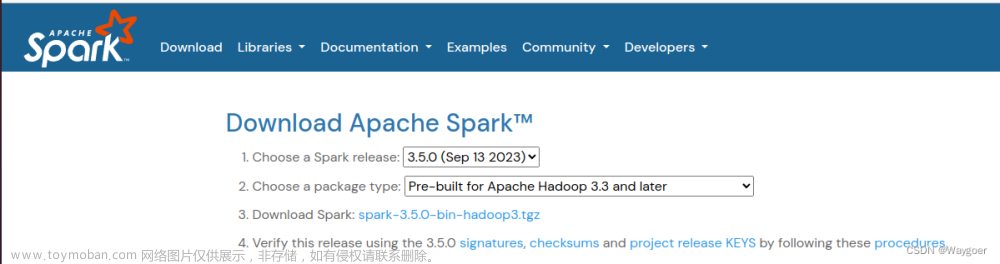
“2.Choose a package type”一行就显示了适配的hadoop版本。
如果下载缓慢,请科学上网,或者从清华大学开源软件镜像站中搜索下载,hadoop和spark均在apache文件夹中。
二、设置免密登陆
为了方便和增强集群节点之间的通信和协作,在安装Hadoop时要预先设置免密登录。
首先执行下方指令安装ssh,需要输入的地方输入y即可。
sudo apt install openssh-client openssh-server执行下方指令生成密钥对,需要输入的地方点击回车即可。
ssh-keygen -t rsa执行下方指令以拷贝公钥到主机,需要回答问题的地方输入yes。
ssh-copy-id -i ~/.ssh/id_rsa.pub localhost执行下方指令,如果没有要求输入密码,则免密登陆设置成功。
ssh localhost三、安装JDK
可以直接选择openjdk进行安装,比较简单,请直接移步下面的链接文章。
ubuntu20.04安装JDK11-CSDN博客https://blog.csdn.net/wyr1849089774/article/details/133823977
四、安装Hadoop
在主目录中创建一个opt文件夹用来放置待配置的文件
mkdir opt通过图形界面将之前下载过的安装包解压到opt文件夹中
然后执行下方命令设置软链接
cd ~/opt
ln -s hadoop-3.2.3/ hadoop执行下方命令打开bashrc文件,进行环境配置
sudo gedit ~/.bashrc如果执行上述命令没有反应,则先Ctrl+C退出一下,再重新执行上述命令,可正常开启
在.bashrc文档末尾添加如下两行语句,注意第一行的XXX要改成自己的用户名。
export HADOOP_HOME=/home/XXX/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin执行下方指令打开hadoop-env.sh配置文件,进行环境变量的配置。
gedit ~/opt/hadoop/etc/hadoop/hadoop-env.sh将文档中export JAVA_HOME=${JAVA_HOME}这句话改为下面这句话,然后保存。
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
输入以下命令使.bashrc文档的修改生效,可用hadoop命令验证配置是否成功
source ~/.bashrc
hadoop
如果输入hadoop后显示如上,则安装成功
五、配置Hadoop伪分布式
在伪分布式的配置中,需要配置的文件都在~/opt/hadoop/etc/hadoop目录下,因此要执行下面的指令,切换到这个目录下进行操作。
cd ~/opt/hadoop/etc/hadoop之后涉及到的文件,可以通过可视化界面直接打开文件修改,也可以通过 sudo gedit 或者 sudo vim 的方式进行修改。
记得将XXX修改为自己的用户名!
1.core-site.xml
打开core-site.xml文件,在configuration标签中加入以下内容,保存。
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/XXX/opt/hadoop/tmp</value>
</property>2.hdfs-site.xml
打开hdfs-site.xml文件,在configuration标签中加入以下内容,保存。
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/XXX/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/XXX/opt/hadoop/tmp/dfs/data</value>
</property>3.mapred-site.xml
如果没有这个配置文件,可以执行下方指令,根据样本文件mapred-site.xml.template复制一份,注意要在~/opt/hadoop/etc/hadoop目录下操作。
cd ~/opt/hadoop/etc/hadoop
cp mapred-site.xml.template mapred-site.xml如果本来就有,则打开mapred-site.xml文件,在configuration标签中加入以下内容,保存。
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.job.ubertask.enable</name>
<value>true</value>
</property>4.yarn-site.xml
打开yarn-site.xml文件,在configuration标签中加入以下内容,保存。
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>除此之外,还需要添加在此文件中添加hadoop的classpath
在命令行中输入
hadoop classpath回车后会显示若干路径,将这些路径全部复制并添加到文件中,格式如下(用路径替换XXX的部分):
<property>
<name>yarn.application.classpath</name>
<value>XXXXXXXXX</value>
</property>六、启动与测试
在第一次启动Hadoop时,需要执行下方的指令对HDFS进行格式化
还需要借助ssh完成免密登陆
hdfs namenode -format在~/opt/hadoop下执行下面的指令启动Hadoop
cd ~/opt/hadoop
start-all.sh执行下面的指令查看进程
jps
务必保证六个进程都在,如果缺少进程,那么说明在安装过程中出现了问题,建议删除hadoop文件并重新安装
七、web访问
在虚拟机中,使用浏览器打开如下两个网址,可以查看HDFS的NameNode和YARN的ResourceManager相关信息。
localhost:9870
localhost:8088

八、测试
在home主目录下创建一个文本文件test.txt,文本文件中输入若干字母或者单词,不同字母或者单词之间用空格分隔,然后执行下方命令行上传到HDFS文件系统。
笔者使用示例文件如下:

将该txt文件上传到hdfs根目录中
hdfs dfs -put test.txt /运行mapreduce示例代码,进行词频统计,然后查看运行结果
hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.3.jar wordcount /test.txt /out
hdfs dfs -ls /out
#查看输出内容
hdfs dfs -cat /out/part*结果展示如下

如果正常显示,则hadoop安装成功且可以正常使用
如果想要关闭hadoop节点,则可以运行以下指令
cd hadoop
close-all.sh如果想要从hdfs系统中删除已有的文件,则可以运行以下指令(/filename需要替换成想要删除的文件的路径)
hadoop删除操作
hadoop fs -rm -r -skipTrash /filename九、安装Spark
将之前下载的spark安装包解压缩到opt文件夹中,并设置软链接
cd ~/opt
ln -s spark-3.2.4-bin-without-hadoop spark执行下方指令打开bash配置文件,进行环境变量的配置
sudo gedit ~/.bashrc在.bashrc文档末尾添加如下两行语句,注意第一行的XXX要改成自己的用户名
export SPARK_HOME=/home/XXX/opt/spark
export PATH=$SPARK_HOME/bin:$PATH输入以下命令使修改生效
source ~/.bashrc先执行下方的指令
cd ~/opt/spark/conf
cp spark-env.sh.template spark-env.sh然后执行下方指令打开spark-env.sh文件
sudo gedit spark-env.sh在文件末尾添加配置如下信息,配置SPARK_DIST_CLASSPATH 变量注意更换成自己的用户名。
export SPARK_DIST_CLASSPATH=$(/home/XXX/opt/hadoop/bin/hadoop classpath)使用如下命令进入scala交互界面:
spark-shell
执行下方代码,如果可以输出结果,即为spark成功安装。
var r = sc.parallelize(Array(1,2,3,4))
r.map(_*10).collect()
如果想要退出scala,则运行指令(注意冒号需要使用英文输入法输入)
:quit十、利用Spark的rdd完成词频统计
首先执行指令进入scala交互界面
spark-shellSpark可以从Hadoop支持的任何存储源中加载数据去创建RDD,包括本地文件系统和HDFS等文件系统
上文中已经将test.txt传递到了hdfs中,故这里从hdfs创建RDD,并用RDD对这个文件进行词频分析
在scala下执行下方的代码,依托这个文件创建RDD。
//依托hdfs新建rdd
val test=sc.textFile("/test.txt")
//将test中的每一行按照空格进行切分
val word = test.flatMap(line=>line.split(" "));
//通过map方法将word中的每个单词转换为 (单词,1) 的元组形式
var wordmap=word.map(x=>(x,1));
//通过 reduceByKey 方法对 RDD wordmap 中的每个单词进行聚合,累加
var wordcount=wordmap.reduceByKey((a,b)=>a+b);
//输出结果
wordcount.foreach(println);
最终结果输出如下:

十一、利用Spark的rdd完成词频统计(程序处理)
这里我们使用scala语言创建RDD并进行词频分析
新建一个文件WordCount.scala放在home文件夹下用于词频分析,文件内容如下
val test=sc.textFile("/test.txt")
//依托hdfs新建rdd
//val test=sc.textFile("file:///home/test.txt")
//这种方法是依托虚拟机中的文件新建RDD
//file://后为本地路径
val word = test.flatMap(line=>line.split(" "));
//将test中的每一行按照空格进行切分
var wordmap=word.map(x=>(x,1));
//通过map方法将word中的每个单词转换为 (单词,1) 的元组形式
var wordcount=wordmap.reduceByKey((a,b)=>a+b);
//通过 reduceByKey 方法对 RDD wordmap 中的每个单词进行聚合,累加
wordcount.foreach(println);
//输出结果执行如下命令进入scala交互界面:
spark-shell进入scala交互界面后,执行下方指令运行WordCount.scala这一程序,并获取输出
:load WordCount.scala其中,:load命令加载脚本文件,并执行其中的代码。输出结果如下:
 文章来源:https://www.toymoban.com/news/detail-854044.html
文章来源:https://www.toymoban.com/news/detail-854044.html
至此,hadoop和spark安装和应用教程展示完毕~ 文章来源地址https://www.toymoban.com/news/detail-854044.html
到了这里,关于ubuntu20.04配置hadoop&&spark(直接配置,无需借助虚拟机)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!










