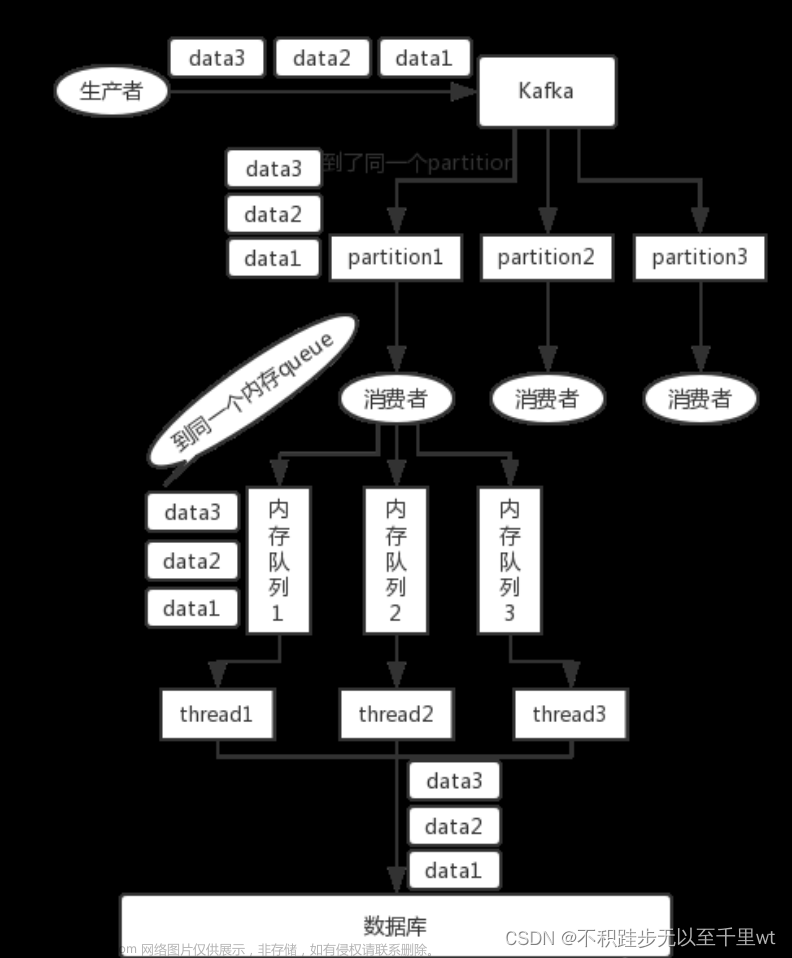
-
数据传输的事物定义有哪三种?
-
Kafka 判断一个节点是否还活着有那两个条件?
-
producer 是否直接将数据发送到 broker 的 leader(主节点)?
-
Kafa consumer 是否可以消费指定分区消息?
-
Kafka 消息是采用 Pull 模式,还是 Push 模式?
-
Kafka 存储在硬盘上的消息格式是什么?
-
Kafka 高效文件存储设计特点
-
Kafka 与传统消息系统之间有三个关键区别
-
Kafka 创建 Topic 时如何将分区放置到不同的 Broker 中
-
Kafka 新建的分区会在哪个目录下创建
-
partition 的数据如何保存到硬盘
-
kafka 的 ack 机制
-
Kafka 的消费者如何消费数据
-
消费者负载均衡策略
-
数据有序
大数据面试题大全
========
1、kafka 的 message 包括哪些信息
2、怎么查看 kafka 的 offset
3、hadoop 的 shuffle 过程
4、spark 集群运算的模式
5、HDFS 读写数据的过程
6、RDD 中 reduceBykey 与 groupByKey 哪个性能好,为什么
7、spark2.0 的了解
8、 rdd 怎么分区宽依赖和窄依赖
9、spark streaming 读取 kafka 数据的两种方式
10、kafka 的数据存在内存还是磁盘
11、怎么解决 kafka 的数据丢失
12、fsimage 和 edit 的区别?
13、列举几个配置文件优化?
14、datanode 首次加入 cluster 的时候,如果 log 报告不兼容文件版本,那需要namenode 执行格式化操作,这样处理的原因是?
15、MapReduce 中排序发生在哪几个阶段?这些排序是否可以避免?为什么?
16、hadoop 的优化?
17、设计题
18、有 10 个文件,每个文件 1G,每个文件的每一行存放的都是用户的 query,每个文件的 query 都可能重复。要求你按照 query 的频度排序。 还是典型的 TOP K 算法?
19、在 2.5 亿个整数中找出不重复的整数,注,内存不足以容纳这 2.5 亿个整数。
20、腾讯面试题:给 40 亿个不重复的 unsigned int 的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那 40 亿个数当中?
21、怎么在海量数据中找出重复次数最多的一个?
22、上千万或上亿数据(有重复),统计其中出现次数最多的钱 N 个数据。
23、一个文本文件,大约有一万行,每行一个词,要求统计出其中最频繁出现的前 10 个词,给出思想,给出时间复杂度分析。
24、100w 个数中找出最大的 100 个数。
25、有一千万条短信,有重复,以文本文件的形式保存,一行一条,有重复。 请用 5 分钟时间,找出重复出现最多的前 10 条。
Hadoop面试题及答案
============
1.您对“大数据”一词有何了解?
2.大数据的五个V是什么?
3.告诉我们大数据和Hadoop如何相互关联。
4.大数据分析如何有助于增加业务收入?
5.解释部署大数据解决方案时应遵循的步骤。
6.定义HDFS和YARN的相应组件
7.为什么Hadoop可用于大数据分析?
8.什么是fsck?
9. NAS(网络附加存储)和HDFS之间的主要区别是什么?
10.格式化NameNode的命令是什么?
11.您有大数据经验吗?如果有,请分享一下。
12.您更喜欢好的数据还是好的模型?为什么?
13.您是否会优化算法或代码以使其运行更快?
14.您如何处理数据准备?
15.您如何将非结构化数据转换为结构化数据?
16.哪种硬件配置对Hadoop作业最有利?
17.当两个用户尝试访问HDFS中的同一文件时会发生什么?
18.如何在NameNode关闭时恢复它?
19.您对Hadoop中的Rack Awareness有何了解?
20.“HDFS Block”和“Input Split”有什么区别?
21.解释Hadoop和RDBMS之间的区别。
22. Hadoop中常见的输入格式是什么?
23.解释Hadoop的一些重要特性。
24.解释Hadoop运行的不同模式。
25.解释Hadoop的核心组件。
26.“MapReduce”程序中的配置参数是什么?
27. HDFS中的块是什么?它在Hadoop 1和Hadoop 2中的默认大小是多少?我们可以改变块大小吗?
28.什么是MapReduce框架中的分布式缓存
29. Hadoop的三种运行模式是什么?
30.在Hadoop中解释JobTracker
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)
完结
Redis基于内存,常用作于缓存的一种技术,并且Redis存储的方式是以key-value的形式。Redis是如今互联网技术架构中,使用最广泛的缓存,在工作中常常会使用到。Redis也是中高级后端工程师技术面试中,面试官最喜欢问的问题之一,因此作为Java开发者,Redis是我们必须要掌握的。
Redis 是 NoSQL 数据库领域的佼佼者,如果你需要了解 Redis 是如何实现高并发、海量数据存储的,那么这份腾讯专家手敲《Redis源码日志笔记》将会是你的最佳选择。文章来源:https://www.toymoban.com/news/detail-854159.html

dis基于内存,常用作于缓存的一种技术,并且Redis存储的方式是以key-value的形式。Redis是如今互联网技术架构中,使用最广泛的缓存,在工作中常常会使用到。Redis也是中高级后端工程师技术面试中,面试官最喜欢问的问题之一,因此作为Java开发者,Redis是我们必须要掌握的。
Redis 是 NoSQL 数据库领域的佼佼者,如果你需要了解 Redis 是如何实现高并发、海量数据存储的,那么这份腾讯专家手敲《Redis源码日志笔记》将会是你的最佳选择。
[外链图片转存中…(img-Ceks60MY-1712076367214)]文章来源地址https://www.toymoban.com/news/detail-854159.html
到了这里,关于史上最全141道大数据面试题:Redis+Linux+kafka的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!