LangChain-Chatchat 是基于 ChatGLM 等大语言模型与 LangChain 等应用框架实现,开源、可离线部署的 RAG 检索增强生成大模型知识库项目。最新版本为 v0.2.10,目前已收获 26.7k Stars,非常不错的一个开源知识库项目。
项目地址:https://github.com/chatchat-space/Langchain-Chatchat
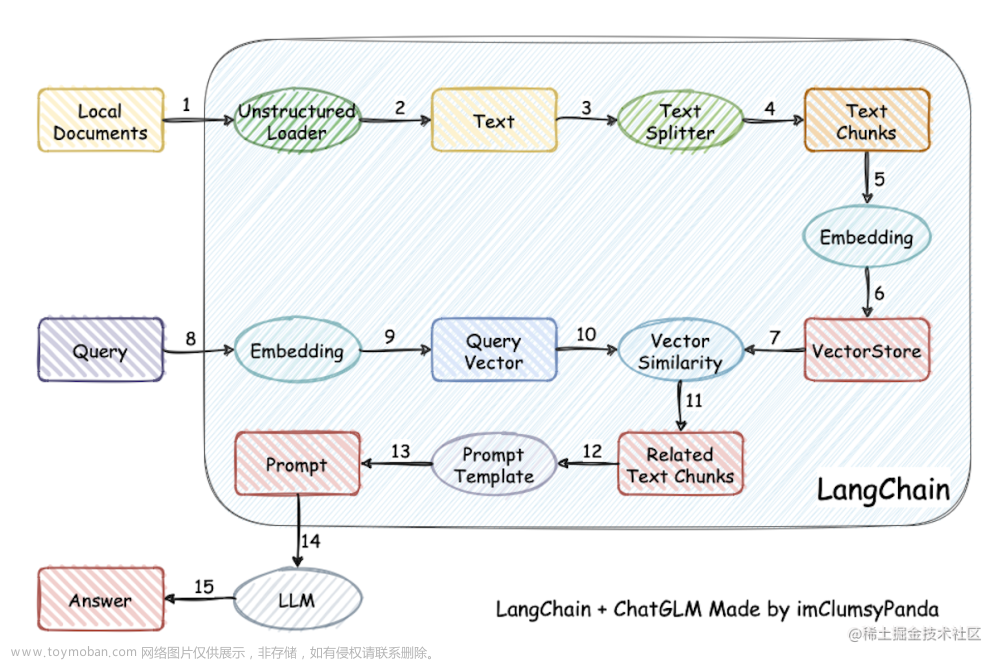
LangChain-Chatchat 架构设计
顾名思义,LangChain-Chatchat 利用 LangChain 思想实现的基于本地知识库的问答应用,目标期望建立一套对中文场景与开源模型支持友好、可离线运行的知识库问答解决方案。
依托于本项目支持的开源 LLM 大模型与 Embedding 嵌入模型,本项目可实现全部使用开源模型 离线私有部署。与此同时,本项目也支持 OpenAI GPT API 的调用,并将在后续持续扩充对各类模型及模型 API 的接入。
本项目实现原理如下图所示,过程包括 加载文件 -> 读取文本 -> 文本分割 -> 文本向量化 -> 问句向量化 -> 在文本向量中匹配出与问句向量最相似的 Top K 个 -> 匹配出的文本作为上下文和问题一起添加到 Prompt 中 -> 提交给 LLM 大模型生成回答。

从文档处理角度来看,实现流程如下:

LangChain-ChatChat 具体实现过程
-
任务定义
首先,我们需要定义问答任务。在 LangChain 中,任务是通过一系列 JSON 格式的配置文件来定义的。对于问答任务,我们需要指定输入文本、输出文本、知识库等相关信息。 -
模型选择
在定义完任务后,我们需要选择合适的模型来完成任务。LangChain 支持多种自然语言处理模型,比如:BERT、GPT 等。对于问答任务,我们可以选择使用问答模型,比如:QA-BERT、QA-GPT 等。 -
数据处理
在模型选择完成后,我们需要对输入数据进行处理。这包括文本清洗、分词、编码等步骤。LangChain 提供了一系列工具和库,方便我们进行数据处理。文章来源:https://www.toymoban.com/news/detail-854254.html -
输出生成
最后,我们需要将模型的输出转换为人类可读的格式。在问答任务中,输出通常是一个答案文本。我们可以使用 LangChain 提供的输出生成工具,将模型的输出转换为格式化的答案文本。文章来源地址https://www.toymoban.com/news/detail-854254.html
一键本地离线部署
软件环境
- Linux Ubuntu 22.04.5 kernel version 6.7
- Python 版本: >= 3.8(很不稳定), < 3.12,推荐 3.11.7
- CUDA 版本: >= 12.1,推荐 12.1
硬件环境
- 取决于选择的大模型,在 GPU 运行本地模型的 FP16 版本,至少需要以下的硬件配置,来保证对话的稳定连续。
- ChatGLM3-6B & LLaMA-7B-Chat 等 7B 模型
- 最低显存要求: 14GB
- 推荐显卡: RTX 4080
- Qwen-14B-Chat 等 14B 模型
- 最低显存要求: 30GB
- 推荐显卡: V100
支持三种部署方式
- 轻量化部署、Docker 部署、常规部署
- 建议使用 Docker 一键部署
docker run -d --gpus all -p 80:8501 registry.cn-beijing.aliyuncs.com/chatchat/chatchat:0.2.0
到了这里,关于LangChain-Chatchat 开源知识库来了的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!