⭐简单说两句⭐
✨ 正在努力的小新~
💖 超级爱分享,分享各种有趣干货!
👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板
🌈 感谢关注,关注了你就是我的超级粉丝啦!
🔒 以下内容仅对你可见~作者:后端小知识,CSDN后端领域新星创作者 |阿里云专家博主
CSDN个人主页:后端小知识
🔎GZH:
后端小知识文章来源:https://www.toymoban.com/news/detail-854333.html🎉欢迎关注🔎点赞👍收藏⭐️留言📝文章来源地址https://www.toymoban.com/news/detail-854333.html
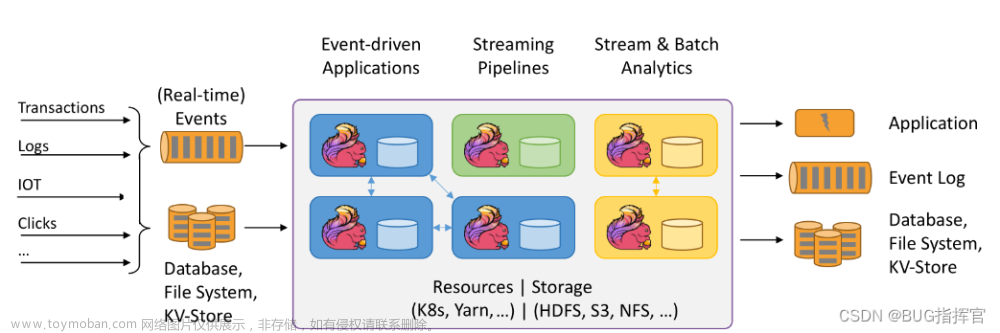
Flink设计&运行原理

在上一章节中,我们快熟入门学习了Flink的WordCount程序,在大数据领域,WordCount就像其他语言的HelloWord,展示了一个大数据引擎的基本规范。 麻雀虽小但五脏俱全,从这个样例中,我们可以看一看Flink设计和运行原理~
我们现在看下今天会将哪些东西,我们看一张思维导图

Flink数据流图
Flink程序三大部分
在说Flink数据流图(Streaming Dataflow)前,我们先来看下Flink程序的三大部分

我们用文字简单解释下
Source算子
读取数据源中的数据,数据源可以是数据流,也可以存储在文件系统中的文件
Transformation
算子对数据进行必要的计算处理
Sink
算子将处理结果输出,数据一般被输出到数据库、文件系统或消息队列
我们看下官网的一个图,里面在代码层面做了一个划分

在看下一个书中的图

Dataflow程序通常表示为有向图。图中顶点称为算子,表示计算;而边表示数据依赖关系。算子是 Dataflow 程序的基本功能单元 ,它们从输入获取数据,对其进行计算,然后产生数据并发往输出以供后续处理。没有输入端的算子称为数据源,没有输出端的算子称为数据汇。 Dataflow 图至少要有一个数据源和一个数据汇。
说白了其实就是:描述了数据如何在不同操作之间流动
逻辑视图到物理执行图
下面这个图就可以算是一个逻辑视图,

在绝大多数的大数据处理场景下,一个节点无法处理所有数据,数据会被切分到多个节点上。在大数据领域,当数据量大到超过单个节点处理能力时,需要将一份数据切分到多个分区(Partition)上,每个分区分布在一台虚拟机或物理机上。
逻辑视图只是一种抽象,需要将逻辑视图转化为物理执行图,才能在分布式的环境下运行~
物理执行图如下

在分布式计算环境下,执行计算的单个节点(物理机或虚拟机)被称为实例,一个算子在并行执行时,算子子任务会分布到多个节点上,算子子任务又被称为算子实例(Instance)。上面图中除去sink外的算子都被分成了2个算子实例,他们的并行度(Parallelism)为2,sink算子的并行度为1。并行度是可以被设置的,当设置某个算子的并行度为2时,也就意味着这个算子有2个算子子任务(或者说2个算子实例)并行执行。实际应用中一般根据输入数据量的大小,计算资源的多少等多方面的因素来设置并行度。
【Tips】:算子子任务是Flink物理执行的基本单元,算子子任务之间是相互独立的,某个算子子任务有自己的线程,不同算子子任务可能分布在不同的机器节点上
数据交换策略
交换策略定义:
数据交换策略定义了如何将数据项分配给物理数据流图中的不同任务。这些策略可以由执行引擎根据算子的语义自动选择,也可以由编程人员显式指定。
说白了就是:数据在不同的算子子任务上进行着数据交换
- 前向传播:前一个算子直接将数据传递给后一个算子,如果两个算子运行在同一个物理机器上,该交换策略可以避免网络通信。
- 广播:会把每个数据项发往下游算子的全部并行任务。 该策略会把数据复制多份且涉及网络通信,很消耗资源。
- 按Key分组:按Key进行分组,Key相同的会被发往同一个分区上,由同一个任务处理
- 随机:会将数据均匀分配至算子的所有任务,以实现计算任务的负载均衡(防止数据倾斜)
我们看图就很好理解了

Flink分布式架构&核心组件

前言
为了支持分布式运行,Flink和其他大数据框架一样,采用了主从架构。
Flink执行时,主要包括两个组件:
- Master:Master是Flink作业的主进程,作用:协调管理
- TaskManager:也可以叫Slave或Worker,是执行计算任务的进程,拥有CPU,内存等计算资源,Flink作业需要将计算任务分发到多个TaskManager上去并行执行
Flink作业提交过程
我们以Standalone模式为例来讲解Flink的作业提交流程

我们下面来分别解释下JobManager、TaskManager、
- JobManager
- JobMaster
- ResourceManager
- Dispatcher
- TaskManager
JobManager(作业管理器)
JobManager :是Flink 集群中任务管理和调度的核心,是控制应用执行的主进程,每个应用都应该被唯一的 JobManager 所控制执行
JobManger 还包含 3 个不同的组件
(1)JobMaster
JobMaster 是 JobManager 中最核心的组件,负责处理单独的作业(Job)。所以 JobMaster和具体的 Job 是一一对应的,多个 Job 可以同时运行在一个 Flink 集群中, 每个 Job 都有一个自己的 JobMaster。
在作业提交时,JobMaster 会先接收到要执行的应用,然后JobMaster 会把 JobGraph 转换成一个物理层面的数据流图【“执行图”(ExecutionGraph)】,它包含了所有可以并发执行的任务。JobMaster 会向资源管理器(ResourceManager)发出请求,申请执行任务必要的资源。一旦它获取到了足够的资源,就会将执行图分发到真正运行它们的 TaskManager上。
而 在 运 行 过 程 中 , JobMaster 会 负 责 所 有 需 要 中 央 协 调 的 操 作 , 比 如 说 检 查 点(checkpoints)的协调。
(2)ResourceManager
ResourceManager 主要负责资源的分配和管理,在 Flink 集群中只有一个。所谓“资源”,主要是指 TaskManager 的任务槽(task slots)。任务槽就是 Flink 集群中的资源调配单元,包含了机器用来执行计算的一组 CPU 和内存资源。每一个任务(Task)都需要分配到一个 slot上执行。
这里注意要把 Flink 内置的 ResourceManager 和其他资源管理平台(比如 YARN)的ResourceManager 区分开。
(3) Dispatcher
Dispatcher 主要负责提供一个 REST 接口,用来提交应用,并且负责为每一个新提交的作
业启动一个新的 JobMaster 组件。Dispatcher 也会启动一个 Web UI,用来方便地展示和监控
作业执行的信息。Dispatcher 在架构中并不是必需的,在不同的部署模式下可能会被忽略掉。
TaskManager(任务管理器)
TaskManager 是 Flink 中的工作进程,数据流的具体计算就是它来做的。Flink 集群中必须至少有一个 TaskManager;每一个 TaskManager 都包含了一定数量的任务槽(task slots)。Slot 是资源调度的最小单位,slot 的数量限制了 TaskManager 能够并行处理的任务数量。
启动之后,TaskManager 会向资源管理器注册它的 slots;收到资源管理器的指令后,TaskManager 就会将一个或者多个槽位提供给 JobMaster 调用,JobMaster 就可以分配任务来执行了。
在执行过程中,TaskManager 可以缓冲数据,还可以跟其他运行同一应用的 TaskManager交换数据。
任务执行&资源划分
再谈逻辑视图->物理视图
我们在上面聊了Flink的分布式架构和核心组件,下面我们再来看戏逻辑视图转换为物理执行图的过程,看下下面这张图~

这张图清晰的给出了Flink各个图的工作原理和转换过程。其中最后一个物理执行图并非Flink的数据结构,而是程序开始执行后,各个task分布在不同的节点上,所形成的物理上的关系表示。
- 从JobGraph的图里可以看到,数据从上一个operator流到下一个operator的过程中,上游作为生产者提供了IntermediateDataSet,而下游作为消费者需要JobEdge。事实上,JobEdge是一个通信管道,连接了上游生产的dataset和下游的JobVertex节点。
- ExecutionGraph:JobManager将JobGraph转化为ExecutionGraph。ExecutionGraph是JobGraph的并行化版本:假如某个JobVertex的并行度是2,那么它将被划分为2个ExecutionVertex,ExecutionVertex表示一个算子子任务,它监控着单个子任务的执行情况。每个ExecutionVertex会输出一个IntermediateResultPartition,这是单个子任务的输出,再经过ExecutionEdge输出到下游节点。ExecutionJobVertex是这些并行子任务的合集,它监控着整个算子的运行情况。ExecutionGraph是调度层非常核心的数据结构。
- ExecutionGraph已经可以用于调度任务。我们可以看到,flink根据该图生成了一一对应的Task,每个task对应一个ExecutionGraph的一个Execution。Task用InputGate、InputChannel和ResultPartition对应了上面图中的IntermediateResult和ExecutionEdge。
StreamGraph是对用户逻辑的映射。JobGraph在此基础上进行了一些优化,比如把一部分操作串成chain以提高效率。ExecutionGraph是为了调度存在的,加入了并行处理的概念。而在此基础上真正执行的是Task及其相关结构
任务、算子子任务与算子链
我们讲解这个前,先来了解一下并行子任务和并行度
当要处理的数据量非常大时,我们可以把一个算子操作,“复制”多份到多个节点,数据来了之后就可以到其中任意一个执行。这样一来,一个算子任务就被拆分成了多个并行的“子任务”(subtasks),再将它们分发到不同节点,就真正实现了并行计算。
在 Flink 执行过程中,每一个算子(operator)可以包含一个或多个子任务(operatorsubtask),这些子任务在不同的线程、不同的物理机或不同的容器中完全独立地执行。

一个特定算子的子任务(subtask)的个数被称之为其并行度(parallelism)。这样,包含并行子任务的数据流,就是并行数据流,它需要多个分区(stream partition)来分配并行任务。
一般情况下,一个流程序的并行度,可以认为就是其所有算子中最大的并行度。一个程序中,不同的算子可能具有不同的并行度。
好了,我们下面再来看一下任务和算子链
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。链行为是可以配置的;
下图中样例数据流用 5 个 subtask 执行,因此有 5 个并行线程。

Task Slots 和资源
任务槽(Task Slots)
Flink 中每一个 TaskManager 都是一个 JVM 进程,它可以启动多个独立的线程,来并行执行多个子任务(subtask)。很显然,TaskManager 的计算资源是有限的,并行的任务越多,每个线程的资源就会越少。那一个 TaskManager 到底能并行处理多少个任务呢?为了控制并发量,我们需要在TaskManager 上对每个任务运行所占用的资源做出明确的划分,这就是所谓的任务槽(taskslots)。
每个任务槽(task slot)其实表示了 TaskManager 拥有计算资源的一个固定大小的子集。这些资源就是用来独立执行一个子任务的。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。

默认情况下,Flink 允许 subtask 共享 slot,即便它们是不同的 task 的 subtask,只要是来自于同一作业即可。结果就是一个 slot 可以持有整个作业管道。允许 slot 共享有两个主要优点:
- Flink 集群所需的 task slot 和作业中使用的最大并行度恰好一样。无需计算程序总共包含多少个 task(具有不同并行度)。
- 容易获得更好的资源利用。如果没有 slot 共享,非密集 subtask(source/map())将阻塞和密集型 subtask(window) 一样多的资源。通过 slot 共享,我们示例中的基本并行度从 2 增加到 6,可以充分利用分配的资源,同时确保繁重的 subtask 在 TaskManager 之间公平分配。

好咯,今天的分享就到这里结束啦,这节很多理论知识,大家可以简单过一下,学习了后续的实操之后再回来细品~
番外篇
最后我给大家安排一本学习Flink原理的书籍
《Flink内核原理与实现》 冯飞,崔鹏云,陈冠华 著

对Flink原理感兴趣的友友不要错过了额~
购买链接: https://item.jd.com/12950924.html
【都看到这了,点点赞点点关注呗,爱你们】😚😚


💬
✨ 正在努力的小新~
💖 超级爱分享,分享各种有趣干货!
👩💻 提供:模拟面试 | 简历诊断 | 独家简历模板
🌈 感谢关注,关注了你就是我的超级粉丝啦!
🔒 以下内容仅对你可见~
作者:后端小知识,CSDN后端领域新星创作者 | 阿里云专家博主
CSDN个人主页:后端小知识
🔎GZH:后端小知识
🎉欢迎关注🔎点赞👍收藏⭐️留言📝
到了这里,关于Flink设计&运行原理 | 大数据技术的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!