背景及问题说明
使用 Kafka client 版本 3.4.0
目前的默认分区策略如下:
NOTE this partitioner is deprecated and shouldn't be used. To use default partitioning logic remove partitioner. class configuration setting. See KIP-794 for more info. The default partitioning strategy:
- If a partition is specified in the record, use it
- If no partition is specified but a key is present choose a partition based on a hash of the key
- If no partition or key is present choose the sticky partition that changes when the batch is full. See KIP-480 for details about sticky partitioning.
渣翻+个人理解如下:
如果(producer)指定了分区,则使用指定的分区;
如果没有指定分区,但是使用了 key,则会基于 key 的 hash 选择一个分区;
如果没有指定分区也没有使用 key,选择当批处理满时改变的粘性分区(这里机翻了,大概意思就是会采用粘性分区策略),粘性分区策略详情查看 KIP-480: Sticky Partitioner
由于默认的粘性分区策略会导致短时间的的连续消息均被发送至同一个分区内,虽然时间拉长的话总体上仍然是平均的,但是碰到的业务需求需要尽可能每条都平均发到各个分区,所以选择修改配置,采用 RoundRobinPartitioner 使用轮询分区策略。
// ……
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,"org.apache.kafka.clients.producer.RoundRobinPartitioner");
// ……
然后上线之后发现只向偶数分区发送消息:
问题排查及原因说明
其实也没什么排查过程,就是疯狂 Google,然后最终定位到了 Kafka 的一个 BUG,以及对应的(20年&21年提出但是目前还是 Open 的)PR:
https://issues.apache.org/jira/browse/KAFKA-9965
https://github.com/apache/kafka/pull/8690
https://github.com/apache/kafka/pull/11326
没有特别深入去了解细节,简单了解了一下原因:
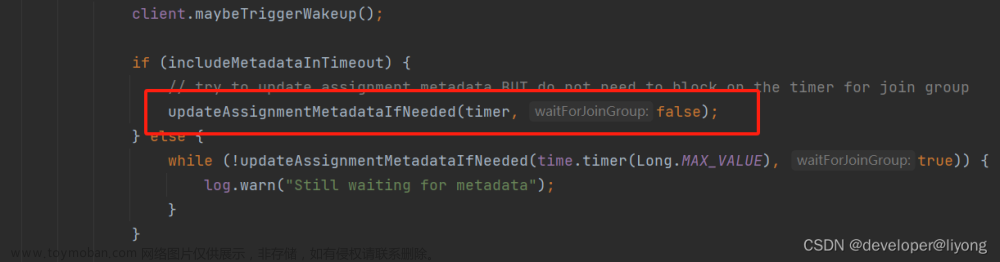
Kafka 通过 KIP-480 引入了 Sticky Partitioner,Partitioner 引入了一个待实现的方法 onNewBatch()。
顺便吐槽一下这个方法目前也已经 了,螺旋式上升是吧
根据 PR#11326 内的说法,没有实现这个方法导致 Partitioner 会调用两次 partition()。所以表现出来的就是:0-(+1+1)->2-(+1+1)->4 ...(理论上如果是从 1 开始的话就都是奇数了,但是没有发现)
解决方式
由于 PR 一直没有 merge,所以只能参照这个 PR 内容自定义实现一个 Partitioner。
然后选择使用这个自定义的 Partitioner文章来源:https://www.toymoban.com/news/detail-854399.html
// ……
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.xxx.xxx.FixRoundRobinPartitioner");
// ……
上线后问题得到解决: 文章来源地址https://www.toymoban.com/news/detail-854399.html
文章来源地址https://www.toymoban.com/news/detail-854399.html
到了这里,关于Kafka 采用 RoundRobinPartitioner 时仅向偶数分区发送消息的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!