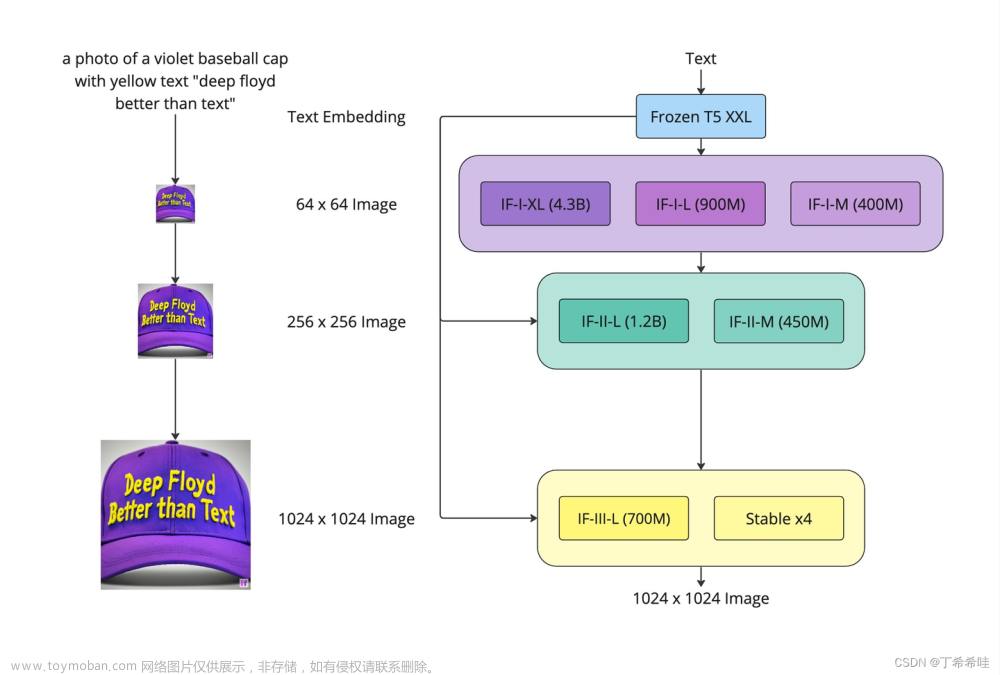
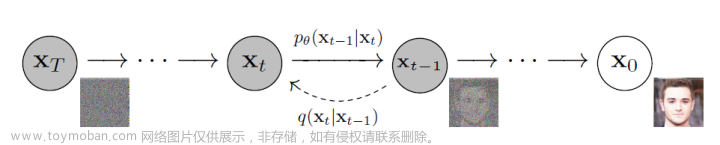
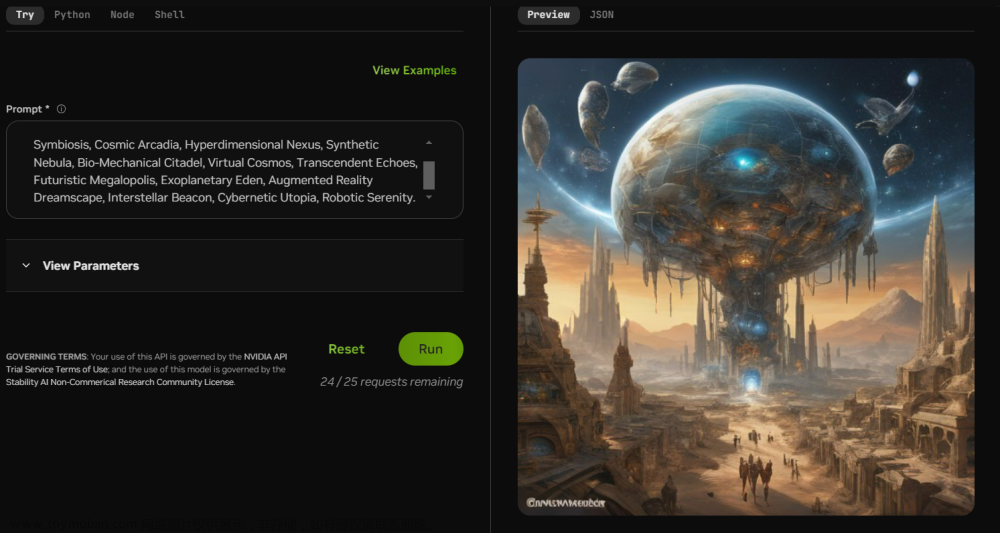
Playground v2.5介绍
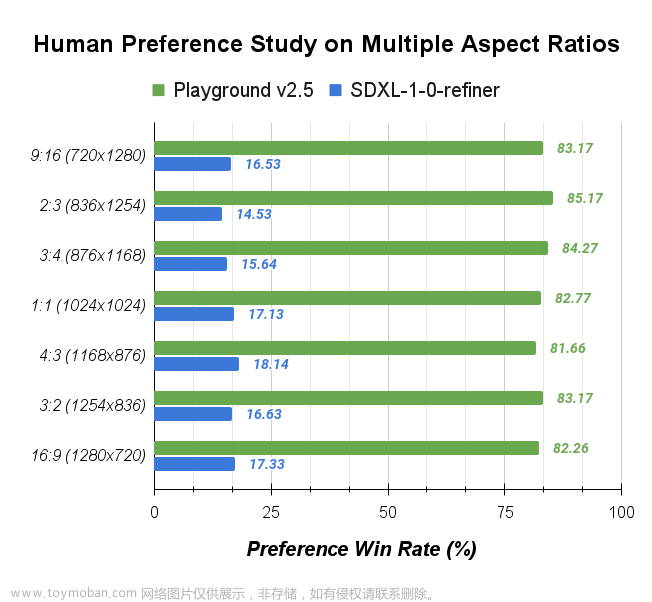
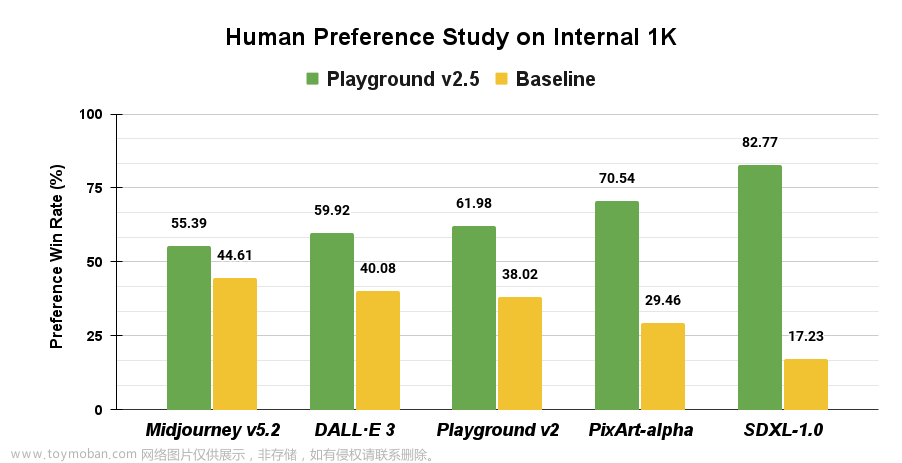
Playground在去年发布Playground v2.0之后再次开源新的文生图模型Playground v2.5。新版本提升了图像的美学质量,增强了颜色和对比度、改进了多纵横比图像生成,可以生成各种比例图像以及人像细节的提升。官方宣称:根据用户研究表明,V2.5的模型优于 SDXL、Playground v2、PixArt-α、DALL-E 3 和 Midjourney 5.2。

Playground v2.5 的美学质量显着优于当前最先进的开源模型 SDXL(提高了4.8倍) 和 PIXART-α(提高了2.4倍) 以及 Playground v2。由于 Playground V2.5 和 SDXL 之间的性能差异如此之大,我们还针对 DALL-E 3 和 Midjourney 5.2 等世界级闭源模型测试了我们的美学质量,发现 Playground v2.5 的性能也优于它们。
模型下载
-
模型:https://huggingface.co/playgroundai/playground-v2.5-1024px-aesthetic文章来源:https://www.toymoban.com/news/detail-854599.html
-
官网: 文章来源地址https://www.toymoban.com/news/detail-854599.html
到了这里,关于Playground v2.5最新的文本到图像生成模型,官方宣称V2.5的模型优于 SDXL、Playground v2、PixArt-α、DALL-E 3 和 Midjourney的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!