目录
前言
设计思路
一、课题背景与意义
二、算法理论原理
2.1 DAST 技术
2.2 逻辑漏洞
2.3 哈希算法
三、检测的实现
最后
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于python的漏洞扫描系统的实现
设计思路
一、课题背景与意义
随着互联网的快速发展,网络安全问题日益突出,漏洞成为网络攻击的主要入口之一。为了保护网络系统的安全,漏洞扫描系统应运而生。漏洞扫描系统是一种利用计算机技术和网络扫描技术,对目标系统进行主动扫描和漏洞检测的系统。它可以帮助组织及时发现和修复系统中的漏洞,减少被攻击的风险。对于企业、组织和网络管理员而言,漏洞扫描系统是确保网络安全的重要工具。
二、算法理论原理
2.1 DAST 技术
基于Web的安全扫描器是为了满足企业对于漏洞检测的需求而开发出来的工具。它们分为几种类型,包括静态应用测试(SAST)扫描器、动态应用测试(DAST)扫描器和交互式应用测试(IAST)扫描器等。DAST主要用于已部署并运行的应用程序。它通过自动化或手动添加数据,将带有安全性测试的数据包发送到应用程序,并根据应用程序的响应来判断测试结果。这种方式类似于渗透测试(也称为黑盒测试)。

DAST主要工作于已部署并运行的应用上,通过发送带有安全性测试数据包的方式,并根据应用的响应来判断测试结果。它能够在应用程序的整个生命周期中进行安全性测试,并及时获取测试结果。相对于SAST,DAST更适用于实时的应用程序安全性测试,类似于渗透测试的方式。DAST的工作流程如下所示:首先,DAST需要确定安全性测试所需的测试用例(也称为POC)。准备完成后,它会使用算法在已部署的应用程序中寻找用户的输入点。DAST会循环查找程序的输入点,并在找到后将准备好的测试用例提交到程序的输入点中,等待应用程序的返回值。DAST会将应用程序的返回值与其内部的安全规则库进行对比,以匹配是否发现了安全问题。

2.2 逻辑漏洞
基于Web的应用可能存在安全缺陷,导致潜在的风险和攻击,如架构设计问题、失效的安全配置和不完善的用户输入验证策略等。逻辑漏洞是由于应用架构设计或业务逻辑设计缺陷而导致的安全漏洞。逻辑漏洞有以下几种。
- 认证类安全问题:这类问题主要发生在应用未对访问后端资源的用户身份进行校验时。某些应用缺乏授权验证,使用户能够绕过授权逻辑并直接访问需要认证的资源。
- 权限类安全问题:这类问题包括垂直权限问题和平行权限问题。平行权限问题主要存在于用户资源生命周期管理的业务逻辑中。例如,当用户调用相关接口进行查询、删除、修改等操作时,当前接口可能未验证用户是否具有相应数据的权限,从而导致用户能够访问未经授权的数据。垂直类越权问题主要存在于特权用户独有的接口中。由于未对特权用户(如网站管理员)的身份进行校验,普通用户可以利用精心构造的参数和自身的身份信息,修改特权用户才能访问的资源数据的生命周期,包括查看、添加、删除和篡改等操作。
2.3 哈希算法
哈希算法在漏洞扫描系统中扮演着多重角色。它用于文件完整性校验,确保文件未被篡改;在数据库校验中,保证数据的完整性和一致性;通过签名和验签,验证扫描器和扫描结果的来源和完整性;同时,哈希算法还可用于密码存储和比对,提高密码的安全性。综合来说,哈希算法在漏洞扫描系统中发挥着重要作用,增强系统的安全性和可信度。

希算法的流程图描述了哈希算法的执行过程。它包括以下主要步骤:输入数据、初始状态设置、数据处理、迭代计算、最终计算和输出哈希值。首先,将待哈希的数据输入算法。然后,根据具体算法,设置初始状态或初始哈希值。接下来,将输入数据按照规则进行分块处理,并对每个数据块进行迭代计算,通常与之前的计算结果进行组合操作。在处理完所有数据块后,进行最终计算,将最后一个数据块与之前的计算结果组合,并应用最后的转换函数。最终,输出生成的哈希值作为算法的结果。

相关代码示例:
import hashlib
def calculate_file_hash(file_path):
# 创建一个哈希对象
hash_object = hashlib.sha256()
try:
# 打开文件
with open(file_path, 'rb') as file:
# 逐块读取文件内容
for chunk in iter(lambda: file.read(4096), b''):
# 更新哈希对象
hash_object.update(chunk)
# 计算文件的哈希值
file_hash = hash_object.hexdigest()
return file_hash
except IOError as e:
print(f"无法打开文件: {e}")
return None
file_path = 'path/to/file.txt'
file_hash = calculate_file_hash(file_path)
if file_hash:
print(f"文件哈希值: {file_hash}")
# 将文件哈希值与预期的哈希值进行比对,以验证文件的完整性
if file_hash == expected_hash:
print("文件完整性验证通过")
else:
print("文件完整性验证失败")三、检测的实现
逻辑漏洞扫描器的开发主要使用Python语言。它包括信息爬取与清洗模块和漏洞检测模块。信息爬取与清洗模块包括信息爬取子模块和数据清洗子模块。信息爬取子模块用于采集扫描器数据源头的信息,并实现了页面识别与提取、登录和异常处理等功能。数据清洗子模块对采集的流量数据进行去重和清洗,以供漏洞检测模块使用。
任务调度模块负责分配和调度基于DAST技术的逻辑漏洞扫描器的工作,按照FIFO原则将任务分发给执行者,并根据任务数目和优先级进行调度。漏洞检测模块对清洗后的流量进行漏洞扫描,采用修改和重放的方式,并使用模糊哈希算法进行响应值的相似度计算。此外,逻辑漏洞扫描器与安全开发生命周期平台和安全平台进行联动,将漏洞扫描的细节以可视化形式展示,并在安全平台上完成漏洞工单的确认、签收、修复和关闭流程。
相关代码示例:
def calculate_hash(response):
# 创建哈希对象
hash_object = hashlib.sha256()
# 更新哈希对象
hash_object.update(response.encode('utf-8'))
# 计算哈希值
response_hash = hash_object.hexdigest()
return response_hash
def fuzzy_match(response1, response2):
# 计算两个响应的哈希值
hash1 = calculate_hash(response1)
hash2 = calculate_hash(response2)
# 比较哈希值的相似度
similarity = hash_similarity(hash1, hash2)
# 返回相似度结果
return similarity
def hash_similarity(hash1, hash2):
# 计算相似度
similarity = 0
if hash1 == hash2:
similarity = 1
else:
# 根据具体算法计算相似度
# ...
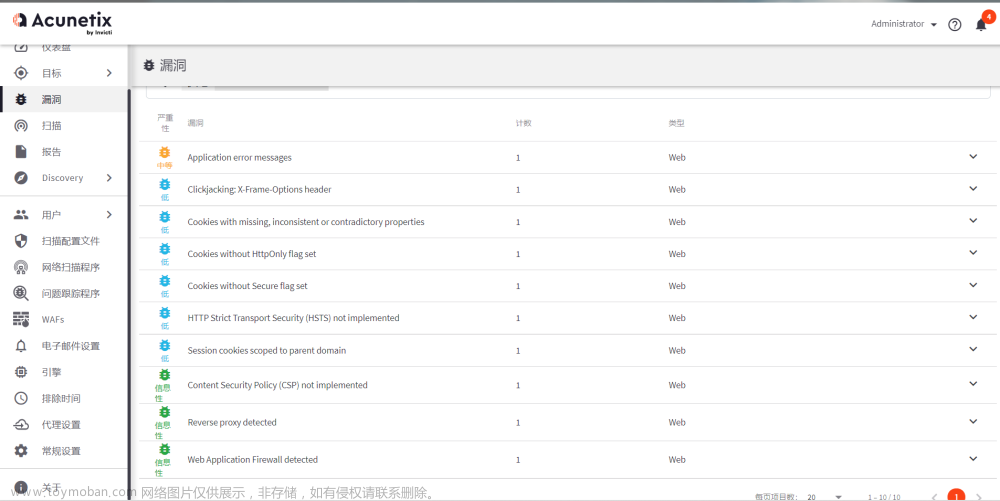
return similarity实现效果图样例:




创作不易,欢迎点赞、关注、收藏。文章来源:https://www.toymoban.com/news/detail-854647.html
毕设帮助,疑难解答,欢迎打扰!文章来源地址https://www.toymoban.com/news/detail-854647.html
最后
到了这里,关于毕业设计:基于python的漏洞扫描系统的实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!