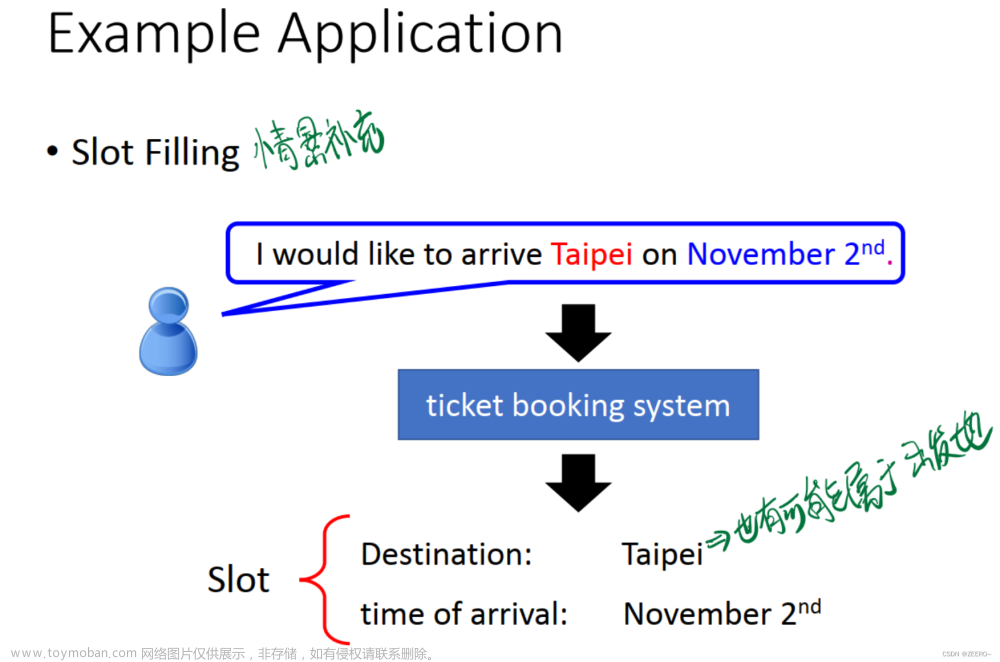
Day 10 Genaral GUidance
这节课主要介绍机器学习和深度学习任务中常见的问题分类以及相应的解决之道
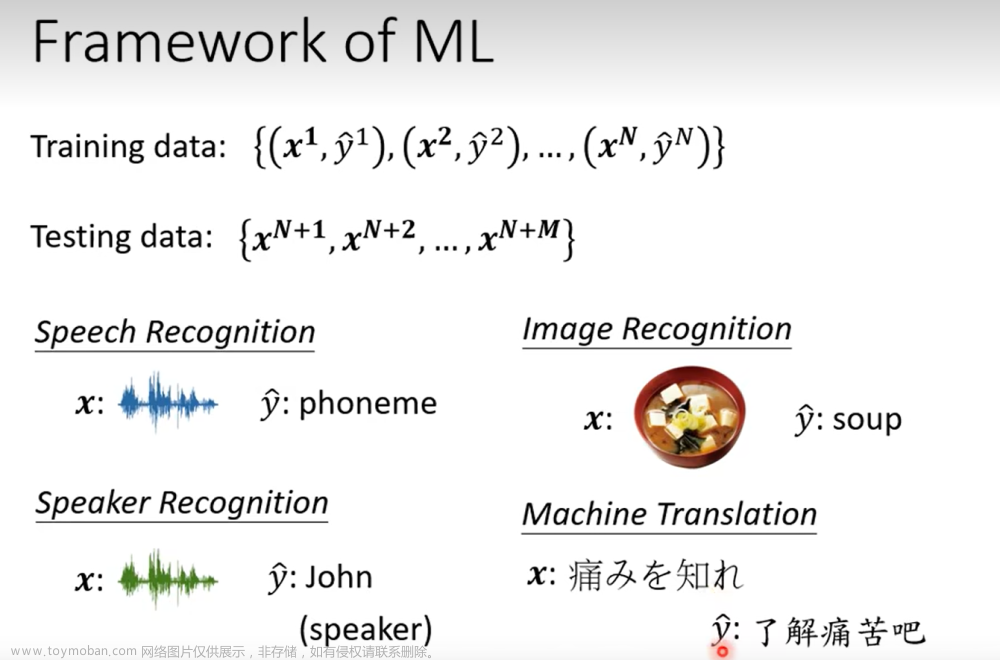


这张图总体的概述了一个任务中的大小坎坷,不认得英文? 去Google吧~
training Loss 不够的case







Loss on Testing data
over fitting


为什么over fitting 留到下下周哦~~ 期待
solve



CNN卷积神经网络
Bias-Conplexiy Trade off


cross Validation

how to split?
N-fold Cross Validation

mismatch
 文章来源:https://www.toymoban.com/news/detail-854764.html
文章来源:https://www.toymoban.com/news/detail-854764.html
这节课总体听下来比较轻松,二倍速一路刷过去了,看看明天的课还会不会这么轻松吧哈哈,期待,今天实操了一下线性回归的东西 还不错有意思~文章来源地址https://www.toymoban.com/news/detail-854764.html
到了这里,关于机器学习和深度学习-- 李宏毅(笔记与个人理解)Day10的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!