论文:https://arxiv.org/pdf/1806.01260.pdf
代码:https://github.com/nianticlabs/monodepth2
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何提高仅使用单目图像进行深度估计的性能。具体来说,它关注的是如何在没有像素级地面真实深度数据的情况下,通过自监督学习方法训练模型来生成高质量的深度图。论文中提出的方法旨在克服单目深度估计中的一些挑战,例如遮挡处理、视觉伪影减少以及相机运动假设的违反。作者通过提出几个关键的改进点,包括最小重投影损失、自适应遮罩损失和全分辨率多尺度采样方法,来提高与竞争性自监督方法相比的深度图的定量和定性质量。此外,这些改进点在不同的训练设置中(单目、立体或混合监督)都被证明是有效的,并且在KITTI基准测试中取得了最先进的结果。
Q: 论文如何解决这个问题?
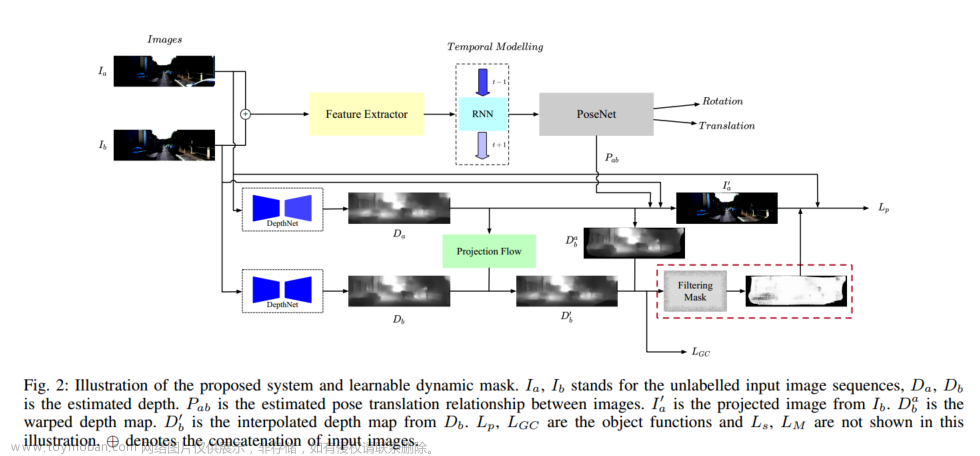
A: 论文通过提出一系列改进措施来解决单目深度估计的问题,这些措施共同导致了与竞争性自监督方法相比,在定量和定性上都有所改进的深度图。具体的解决方案包括:
最小重投影损失(Minimum Reprojection Loss):
为了鲁棒地处理遮挡问题,作者提出了一种新的重投影损失函数,它只考虑每个像素在可见视图中的最小重投影误差,而不是像传统方法那样对所有源图像的重投影误差取平均。
自适应遮罩损失(Auto-Masking Loss):
为了忽略违反相机运动假设的训练像素,作者引入了一种自适应遮罩机制。该机制可以自动过滤掉在连续帧中外观不变的像素,从而让网络忽略移动速度与相机相似的对象,或者在相机静止时忽略整个帧。
全分辨率多尺度采样方法(Full-Resolution Multi-Scale Sampling):
为了减少视觉伪影,作者提出了一种在输入分辨率下计算所有损失的多尺度外观匹配损失方法。这与传统方法在解码器的每个层级上计算损失不同,可以有效地减少深度图中的“空洞”和纹理复制伪影。
这些改进措施的结合使得所提出的Monodepth2模型能够在单目、立体或混合监督下进行有效训练,并在KITTI基准测试上取得了最先进的结果。此外,作者还展示了这些组件单独使用时的有效性,并通过实验验证了它们对整体性能的贡献。
最小重投影损失(Minimum Reprojection Loss)



自适应遮罩损失(Auto-Masking Loss):

通过最小前一侦和差距,来判断哪些车是跟车一个速度,从而mask这些车,来提高整体的深度图的生成。类似flow的形式
全分辨率多尺度采样方法(Full-Resolution Multi-Scale Sampling):
为了减少视觉伪影,作者提出了一种在输入分辨率下计算所有损失的多尺度外观匹配损失方法。这与传统方法在解码器的每个层级上计算损失不同,可以有效地减少深度图中的“空洞”和纹理复制伪影。

Final Training Loss
L = μ L p + λ L s L = \mu L_p + \lambda L_s L=μLp+λLs

用pose来做自监督,从而来监督深度图的生成。
因为这是一个自监督的学习过程,所以输入的图片没有预先定义的深度标签(即没有预设的正确答案来帮助优化输出的深度图)。因此,我们采用了一种联合训练方法。这种方法通过输入相邻的图像帧来训练一个网络,这个网络能预测这些帧之间的相对位置。通过这种训练,我们可以从原始帧生成重建帧。然后,我们用这些重建帧和原始输入帧之间的差异来作为训练信号,以此达到自我监督学习的效果。


参考:https://blog.csdn.net/qq_17027283/article/details/131841352
 文章来源:https://www.toymoban.com/news/detail-854767.html
文章来源:https://www.toymoban.com/news/detail-854767.html
结果图
 文章来源地址https://www.toymoban.com/news/detail-854767.html
文章来源地址https://www.toymoban.com/news/detail-854767.html
到了这里,关于【论文阅读】Digging Into Self-Supervised Monocular Depth Estimation的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!