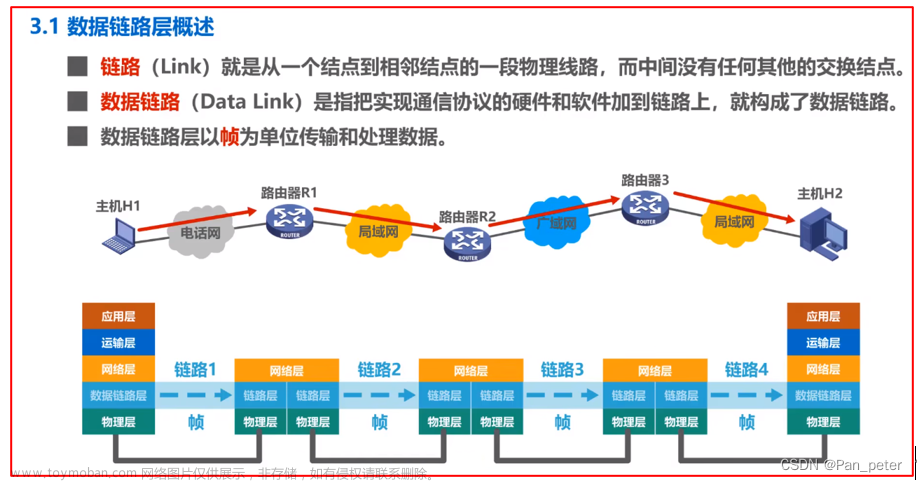
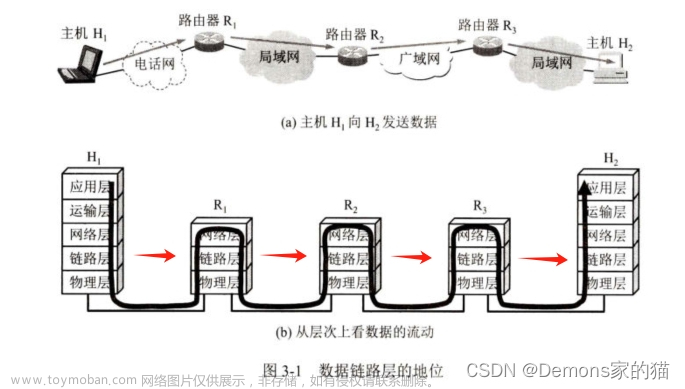
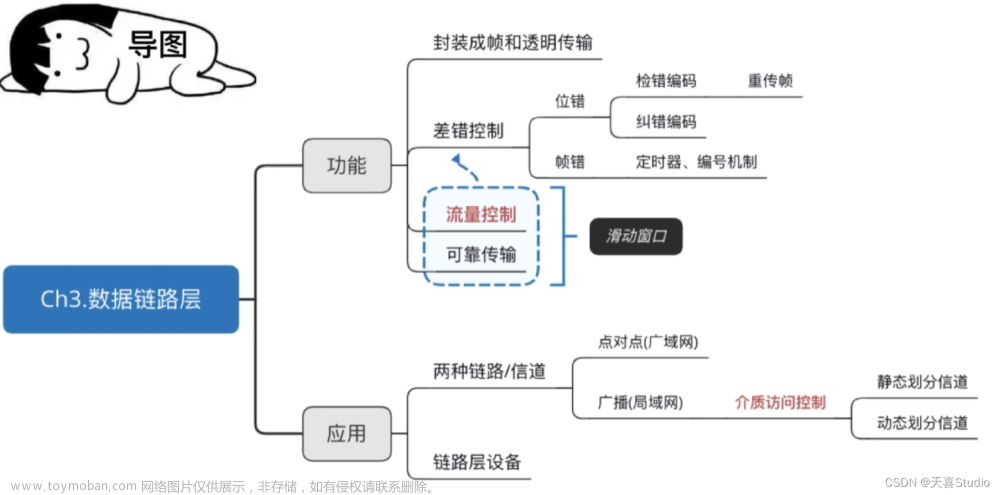
计算机视觉笔记:第一章 图像分类-CSDN博客
计算机视觉笔记 第二章 图像语义分割-CSDN博客
计算机视觉笔记 第三章:目标检测-CSDN博客
计算机视觉 第四章:图像识别、目标跟踪-CSDN博客
计算机视觉 第五章 多目视觉(立体视觉)-CSDN博客
标定图像中目标的位置,并给出目标的类别
目标检测和语义分割的区别:
语义分割:包含低层的像素级别的处理方法,也包含高层的语义级别的处理方法
目标检测:基本都是高层的语义级别的处理方法
基于经典手工特征的目标检测算法
通用流程:1. 使用滑动窗口寻找目标;
2. 使用模板匹配或者其改进方法对滑窗选中的区域进行判断。
滑动窗口与模板匹配检测法(蛮力搜索):
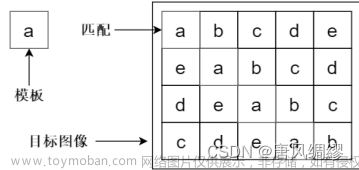 目标发生旋转或大小变化等,方法都会失效
目标发生旋转或大小变化等,方法都会失效
选择性搜索:
 用类似区域分裂合并法的方法找到目标候选区域
用类似区域分裂合并法的方法找到目标候选区域
多元化策略---色彩空间多样化:使用不同的色彩空间,以提取不同的不变属性
相似度度量多样化:颜色、纹理、尺寸等多方面相似度匹配
改变起始区域:采用不同算法选取起始区域,以达到最佳分隔效果
优点:多尺度,多元化,快速
VJ检测器:
传统滑动窗口检测+ 
Haar特征:


Haar特征反映了局部区域之间的相对明暗关系,能够为人脸和非人脸的区分提供有效的信息
特征选择方法:
既想要速度也想要准确率,于是使用Adaboost决策器---把多个简单分类器组合起来,聚弱为强。整个检测器由多级Adaboost 决策器组成。
多阶段处理:
将较少的计算资源分配 背景窗口,而将较多的计算资源分配在目标窗口。 如果某一级决策器将当前窗口判定为背景,则无需后 续决策就可继续开始下一个窗口的判断。
可变形部件模型:
 将传统对目标整体的检测问题拆分并转化为对模型各个部件的检测问题,然后将各部件检测结果聚合成最终结果。即“从整体到部分,再从部分到整体”。
将传统对目标整体的检测问题拆分并转化为对模型各个部件的检测问题,然后将各部件检测结果聚合成最终结果。即“从整体到部分,再从部分到整体”。
模型由基滤波器和一系列部件滤波器构成。
对模型输出结果采用采用边界框回归提升边框位置精度,采用上下文信息集成提升检测准确率。(上下文信息反映了各个类别的目标在图像中的联合先验概率密度分 布,即哪些类别的目标可能同时出现,哪些类别的目标则不太可能同时出现。)
深度学习目标检测
RNN系列:两阶段算法。先产生目标候选区域,再做分类回归。准确率高。
Yolo系列,SSD系列:只用一个卷积网络预测目标位置和类别。速度快。
RNN系列:
RCNN:
借鉴滑动窗口思想,从图片中提取2000个候选区域;
每个候选区域利用卷积神经网络获取一个特征向量;
对于每个区域相应的特征向量,利用支持向量机进行分类;
边界框回归,调整目标边界框的大小。
缺点:选择性搜索效率低;串行CNN特征提取需要逐个候选框提取特征效率低;三个模块(特征提取,SVM,边框修正)是分别训练的,空间占用大
Fast RCNN:
使用一个卷积神经网络对全图进行特征提取;
使用一个感兴趣区域池化层在全图特征上摘取每一个感兴趣区域对应的特征;
加入了多任务损失函数,除了选择性搜索,其他模块都可以合在一起训练
缺点:选择性搜索仍在
Faster RCNN:
区域提议网络(RPN)取代选择性搜索

锚框(先验框):RPN预置了九种尺寸(三种面积128×128,256×256,512×512,每种面 积又包含三种长宽比1:1,1:2,2:1)的锚框在图像上滑动来寻找目标。一张图片需要的锚框总数约为20000个。
Mask RCNN:
用感兴趣区域(即先将原图和特征图的像素对应起来,然后将特征图和固定的特征区域对应起来)对齐取代感兴趣区域池化;
对这些感兴趣区域进行分类(N类别分类)、边界框回归和掩模生成(在每一个感兴趣区域里面进行FCN(全卷积)操作)
Yolo和ssd系列: 将物体分类和物体检测网络合二为一,都在全连接层完成
Yolo:
网络结构分为三部分:卷积层,目标检测层,非极大值抑制筛选层
卷积层提取特征,提高模型的泛化能力。目标检测层为每个边界框计算一个置信度(置信度包含两个方面,一是这个边界框含有目标的可能性大小,二是这个边界框的准确度)。非极大值抑制筛选层:基本同边界框回归。
SSD:
结合了RNN和YOLO的优点。文章来源:https://www.toymoban.com/news/detail-854793.html
多尺寸特征图上进行目标检测:每一个卷积层,都会输出不同大小感受野的特征图。在这些不同尺度的特征图上,进行目标位置和类别的训练和预测,从而达到多尺度检测的目的。文章来源地址https://www.toymoban.com/news/detail-854793.html
到了这里,关于计算机视觉笔记 第三章:目标检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!