本人小白,因为毕设项目需要用的语音交互,便查网上的资料利用百度api实现,比较简单的过程,供大家借鉴批判。
项目框架大致分为3步:(1)百度语音识别可以将我们输入的语音转化为文本输入到文心一言大模型;(2)文心一言大模型根据输入以输出响应文本;(3)百度语音合成将文本转化为语音并播放。至此一套完整的语音交互便实现了。
实现条件:
(1)开通百度智能云官方中千帆大模型和语音技术的api应用并获得API_KEY、SECRET_KEY,并且开通付费服务(如语音生产要开通音库付费服务)开通过程网上的教程非常多,很简单,我就不多赘述了。
(2)有Python环境即可
实现成本:百度的千帆大模型(也就是大语言模型)有20元的抵用券,好像是自动发放的,能用很久。并且语音技术方面可以领取免费资源,如下图中右上角就可以领。
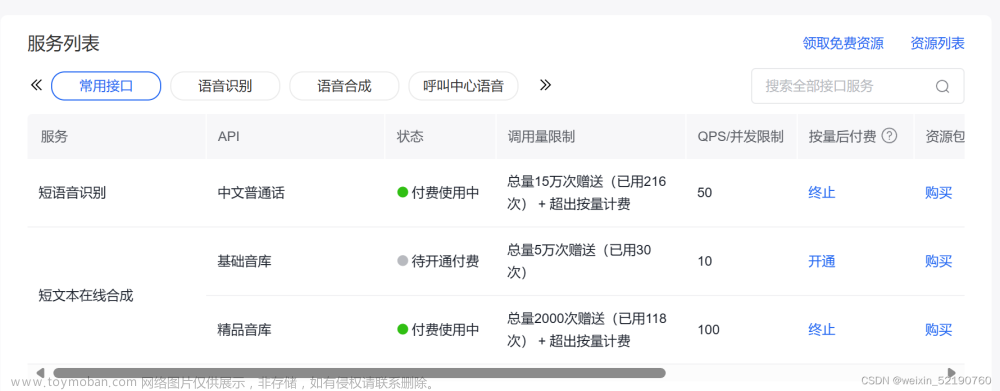
并且其实不用这些免费资源,完全自费,一次完整的语音交互的成本也大概只有元,这个量级,很便宜。
实现步骤非常简单,大家把下面三段代码分别复制到自己的Python的IDE中,并且安装每段代码所需的第三方库,然后将自己在百度智能云的申请的API_KEY、SECRET_KEY,就可以运行实现了。
接下来就是实现步骤,一共三段代码(基本都是我复制整合了一下),很简单:
第一步:
百度语音识别可以将我们输入的语音转化为文本,此段代码Python文件命名“speech_to_text.py”,导入文件开头所需的第三方Python库。并且将API_KEY、SECRET_KEY换成你自己在百度智能云的语音技术中申请的就行,(别忘了开通计费服务)
import librosa
import soundfile as sf
import speech_recognition as sr
import requests
import json
import base64
# API配置
API_KEY = "YxkeQS64jILPN51*********"
SECRET_KEY = "viepyIPbZxkm9uiSy*********"
# 获取Token
def fetch_token():
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
params = {'grant_type': 'client_credentials', 'client_id': API_KEY, 'client_secret': SECRET_KEY}
response = requests.post(TOKEN_URL, params=params).json()
return response['access_token']
def speech_text(audio):
# 将AudioData对象保存为临时WAV文件
with open("temp.wav", "wb") as f:
f.write(audio.get_wav_data())
# 使用librosa读取WAV文件并转换采样率
y, sr1 = librosa.load("temp.wav", sr=16000) # 转换采样率到16000Hz
# 将调整采样率后的音频保存为新的WAV文件
sf.write("temp_resampled.wav", y, sr1)
# 读取调整采样率后的音频文件,准备发送给API
with open("temp_resampled.wav", "rb") as f:
wav_data = f.read()
# 将音频数据转换为Base64编码
encoded_audio = base64.b64encode(wav_data).decode("utf-8")
# 获取access_token
token = fetch_token()
# 准备请求
url = "https://vop.baidu.com/server_api"
payload = {
"format": "wav",
"rate": 16000,
"channel": 1,
"token": token,
"cuid": "9zh2Ldb9IXsMdhOsjOdyid2KL6EcNxND",
"speech": encoded_audio,
"len": len(wav_data)
}
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
# 发送请求
response = requests.post(url, headers=headers, data=json.dumps(payload))
result = response.json().get("result", ["无法识别"])[0]
return result
if __name__ == "__main__":
# 测试
while True:
try:
# 初始化麦克风
recognizer = sr.Recognizer()
# 打开麦克风并且录制
with sr.Microphone() as source:
print("Please say something...")
audio = recognizer.listen(source)
result = speech_text(audio)
if result == "退出程序。": # 如果说“退出程序”则退出程序
print("Exiting...")
break
print("You sai:", result)
except sr.UnknownValueError:
print("Could not understand audio")
except sr.RequestError as e:
print("Could not request results from Google Speech Recognition service; {0}".format(e))
第二步:
百度语音合成将文本转化为语音并播放,此段代码Python文件命名“text_to_speech.py”,导入文件开头所需的第三方Python库。并且也将API_KEY、SECRET_KEY换成你自己在百度智能云的语音技术中申请的就行,注意,语音识别和语音合成都属于语音技术,所以API_KEY、SECRET_KEY可以是一样的(也别忘了开通计费服务)。
语音合成可以合成不同的声音,音色,音调等都是可以通过设置参数接口进行设置的,可以看下列代码的备注,也可以参考官方文档。(注意要用精品音库的话,别忘了开通精品音库的计费服务或者领取免费额度,要不然就用不了,个人感觉精品音库确实比基础音库感觉更拟人化)
import requests
from urllib.parse import quote_plus
import os
import pygame
import time
# API配置
API_KEY = 'YxkeQS64jILPN5*********'
SECRET_KEY = 'viepyIPbZxkm9uiSyE*********'
TTS_URL = 'http://tsn.baidu.com/text2audio'
TOKEN_URL = 'http://aip.baidubce.com/oauth/2.0/token'
# 发音人选择, 基础音库:0为度小美,1为度小宇,3为度逍遥,4为度丫丫,
# 精品音库:5为度小娇,103为度米朵,106为度博文,110为度小童,111为度小萌,默认为度小美
PER = 110
# 语速,取值0-15,默认为5中语速
SPD = 5
# 音调,取值0-15,默认为5中语调
PIT = 5
# 音量,取值0-9,默认为5中音量
VOL = 5
# 下载的文件格式, 3:mp3(default) 4: pcm-16k 5: pcm-8k 6. wav
AUE = 3
# 获取Token
def fetch_token():
params = {'grant_type': 'client_credentials', 'client_id': API_KEY, 'client_secret': SECRET_KEY}
response = requests.post(TOKEN_URL, data=params).json()
return response['access_token']
# 语音合成并保存文件
def text_to_speech(text):
token = fetch_token()
params = {
'tok': token,
'tex': quote_plus(text),
'per': PER,
'spd': SPD,
'pit': PIT,
'vol': VOL,
'aue': AUE,
'cuid': "123456PYTHON",
'lan': 'zh',
'ctp': 1
}
response = requests.post(TTS_URL, params=params)
content_type = response.headers['Content-Type']
if 'audio/' in content_type:
filename = 'result.mp3'
with open(filename, 'wb') as f:
f.write(response.content)
print(f"Audio saved as {filename}")
# 播放音频文件
# 初始化pygame
pygame.mixer.init()
pygame.mixer.music.load(filename)
pygame.mixer.music.play()
while pygame.mixer.music.get_busy(): # 检查音乐流播放是否正在进行中
time.sleep(1)
# 确保音频播放完毕后停止并释放资源
pygame.mixer.music.stop()
pygame.mixer.quit()
# 播放完毕后删除文件
os.remove(filename)
else:
print("Error:", response.text)
if __name__ == '__main__':
TEXT = "大家好,欢迎使用百度语音合成,感谢使用。"
text_to_speech(TEXT)
第三步:
调用“speech_to_text.py”语音识别获得文本,输入到文心一言大模型响应并且输出文本,然后在调用“text_to_speech.py”语音合成将文心一言的输出合成语音,以完成整个流程。此段代码Python文件命名“voice_interation.py”(这个文件名因为不再调用,所以大家可以随意命名),导入文件开头所需的第三方Python库和我们之前写的“speech_to_text.py”、“text_to_speech.py”。并且将API_KEY、SECRET_KEY换成你自己在百度智能云的千帆大模型中申请的就行,(别忘了开通计费服务),我创立了一个dialogue_history以储存每次的交互数据以达到多轮连续对话的目的。文章来源:https://www.toymoban.com/news/detail-854794.html
import requests
import json
import speech_recognition as sr
import speech_to_text4 as stt
import text_to_speech3 as tts
# API配置
API_KEY = "QKyIsmmy8YF6*********"
SECRET_KEY = "Y0uLafDicDSPQoAo************"
dialogue_history = []
# 获取Token
def get_access_token():
"""
使用 AK,SK 生成鉴权签名(Access Token)
"""
url = "https://aip.baidubce.com/oauth/2.0/token"
params = {"grant_type": "client_credentials", "client_id": API_KEY, "client_secret": SECRET_KEY}
response = requests.post(url, params=params)
return response.json().get("access_token")
def get_resp(question):
access_token = get_access_token()
url = f"https://aip.baidubce.com/rpc/2.0/ai_custom/v1/wenxinworkshop/chat/eb-instant?access_token={access_token}"
# 更新对话历史
dialogue_history.append({"role": "user", "content": question})
# print(dialogue_history)
payload = json.dumps({
"user_id": "孙景涛",
"system": "你是桌面智能机器人的大语言模型,名字叫做:'团子'。",
"messages": dialogue_history
})
headers = {'Content-Type': 'application/json'}
response = requests.request("POST", url, headers=headers, data=payload)
resp_content = response.json().get('result')
# print("Robot: ", resp_content)
dialogue_history.append({"role": "assistant", "content": resp_content})
print(dialogue_history)
return resp_content
# 初始化麦克风识别器
r = sr.Recognizer()
while True:
try:
# 使用默认麦克风
with sr.Microphone() as source:
print("Please say something...")
audio = r.listen(source)
text = stt.speech_text(audio) # 百度语音识别可以将我们输入的语音转化为文本
print("You said: " + text)
# 检查是否退出程序
if text == "退出程序。":
print("Exiting...")
break
response = get_resp(text)
print("robot said:", response)
tts.text_to_speech(response)
except sr.UnknownValueError:
print("Could not understand audio")
except sr.RequestError as e:
print(f"Could not request results; {e}")
至此就结束了,有问题或者建议批判大家直接说哦!我们一起进步!!文章来源地址https://www.toymoban.com/news/detail-854794.html
到了这里,关于基于百度语音识别、文心一言大模型、百度语音合成的一套完整的语音交互(利用Python实现)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!