一、实验目的
- 掌握在Linux虚拟机中安装Hadoop和Spark的方法;
- 熟悉HDFS的基本使用方法;
- 掌握使用Spark访问本地文件和HDFS文件的方法。
二、实验具体内容
2.1 HDFS常用操作
-
启动Hadoop,在HDFS中创建用户目录“/user/hadoop”
cd /usr/local/hadoop/ ./bin/hdfs dfs -mkdir -p /user/hadoop
-
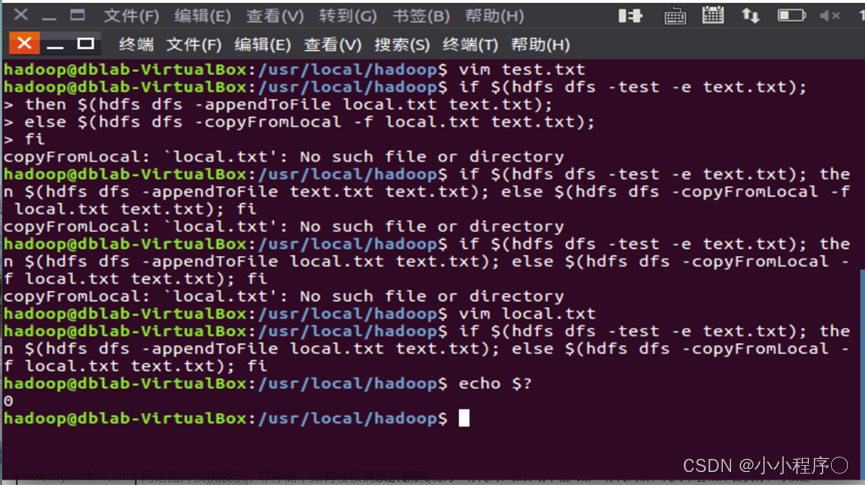
在Linux系统的本地文件系统的“/home/hadoop”目录下新建一个文本文件test.txt,并在该文件中随便输入一些内容,然后上传到HDFS的“/user/hadoop”目录下;
使用vim命令在本地新建一个文件,使用hdfs dfs -put将文件上传到hdfs,使用hdfs dfs -ls命令查看是否上传成功。vim /home/hadoop/test.txt ./bin/hdfs dfs -put /home/hadoop/test.txt ./bin/hdfs dfs -ls
-
把HDFS中“/user/hadoop”目录下的test.txt文件,下载到Linux系统的本地文件系统中的“/home/hadoop/下载”目录下;
使用hdfs dfs -get命令下载hdfs文件到本地
-
将HDFS中“/user/hadoop”目录下的test.txt文件的内容输出到终端中进行显示;
使用hdfs dfs -cat将文件内容输出到终端显示
-
在HDFS中的“/user/hadoop”目录下,创建子目录input,把HDFS中“/user/hadoop”目录下的test.txt文件,复制到“/user/hadoop/input”目录下;
用hdfs dfs -mkdir /user/hadoop/input来创建目录,
用hdfs dfs -cp来进行文件复制操作
-
删除HDFS中“/user/hadoop”目录下的test.txt文件,删除HDFS中“/user/hadoop”目录下的input子目录及其子目录下的所有内容。
hdfs dfs -rm /user/hadoop/test.txt hdfs dfs -rm -r /user/hadoop/input
2.2 Spark读取文件系统数据(本地和HDFS)
-
下面是我们的test.txt文件的内容(该文件已经在Linux本地和hdfs中存在了):

-
在pyspark中读取Linux系统本地文件“/home/hadoop/test.txt”(如果该文件不存在,请先创建),然后统计出文件的行数;
在shell中依次输入下面的代码: file_path = "file:///home/hadoop/test.txt" # 这是你自己的文件地址 data = sc.textFile(file_path) print("该文件的行数为:", data.count())
-
在pyspark中读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;
在shell中依次输入下面代码: file_path = "hdfs://localhost:9000/user/hadoop/test.txt" data = sc.textFile(file_path) print("该文件的行数为:", data.count())
-
编写独立应用程序,读取HDFS系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后,统计出文件的行数;通过spark-submit提交到Spark中运行程序。
创建~/mycode/LineCount.py文件,其中代码如下:from pyspark import SparkConf, SparkContext conf = SparkConf().setMaster("local").setAppName("line count") sc = SparkContext(conf = conf) file_path = "hdfs://localhost:9000/user/hadoop/test.txt" data = sc.textFile(file_path) print("该文件的行数为:", data.count())使用
/usr/local/spark/bin/spark-submit ~/mycode/LineCount.py提交程序文章来源:https://www.toymoban.com/news/detail-855280.html 文章来源地址https://www.toymoban.com/news/detail-855280.html
文章来源地址https://www.toymoban.com/news/detail-855280.html
到了这里,关于HDFS常用操作以及使用Spark读取文件系统数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!