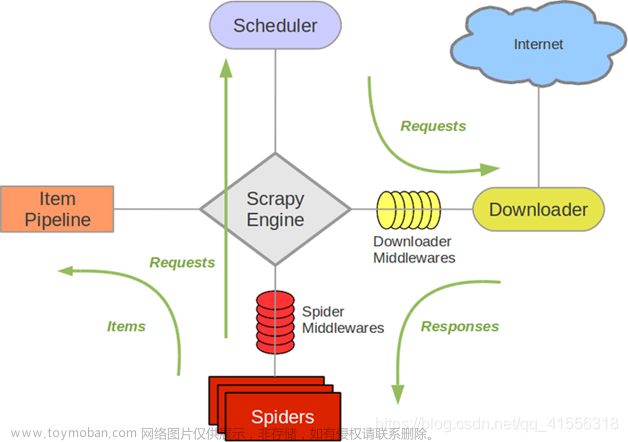
今天学了个爬虫。在此记录
目录
一.通过scrapy在命令行创建爬虫项目
二.判断数据为静态还是动态
三.pycharm中的设置
三:爬虫主体
四.pipelines配置(保存数据的)
五.最终结果
一.通过scrapy在命令行创建爬虫项目
1.首先需要在cmd中进入到python文件对应的文件夹目录下
2.下载scrapcy模块
(如果是在conda环境下的话直接配置就行了ps:(conda是款工具,里面有自带的python环境))
3.创建项目
scrapy startproject test (创建一个爬虫工程,名字为test2 (ps:前面那两一定得加,如果不指定目录默认安装在当前的路径下边指定目录的话按后面这样写scrapy startproject ⼯程名 [⼯程⽬录]))


进入pycharm中发现创建成功。ps:如果没使用ancoda,直接本机pycharm安装,这里面可能有些东西会标红,把鼠标放到红色的地方会弹出来个导包选项,导进去就行。
scrapy.cfg是最终部署爬⾍的配置⽂件
items.py设置要爬取的字段
pipelines.py设置保存爬取内容
settings.py设置⽂件,⽐如User-Agent spiders⽬录保存genspider⽣成的爬⾍⽂件
genspider表示⽣成爬⾍,example表示爬⾍名称,可以对应爬取⽹址域名的前缀,example.com是要爬取的⽹址
而后回到项目目录下创建爬虫文件


创建成功后,就会在spiders下看到创建的.py文件。其中,里面这两地址是可以改的,改成准备爬取的地址也可以在创的时候就改好,这里爬一个搜索 | 腾讯招聘这玩意。

二.判断数据为静态还是动态
创建好后,可以通过postman(一个软件,可以解析url的具体请求)对其进行分析,看看爬取类型是动态还是静态。(网页中分为静态爬取和动态爬取)通过f12查看页面源码,观察具体情况。

f12点开后,首先便将点击图中的网络,即可看到关于页面网络的相关信息(刚点击去应该是空的,会有个提示ctrl+R查看网络信息),而后点击fetch/xhr,这是网络中一个查看网页中异步请求的模块。(异步:说到异步处理就得提它兄弟,同步处理。(举例子,具体区别搜别的佬怎么写的)同步处理很好理解,就是一条一条请求顺序执行,第一条执行完才执行第二个。但这样就会出现一种情况,如果第一条是个很庞大的命令,那就要执行很久,就会导致长时间的等待,出现堵塞情况。而异步就是解决此问题,如果出现一条需要执行很长很久的命令或者任务,异步处理会先将其挂起,转而处理下一条命令。比如一条命令需要执行1000秒,异步请求就会先将其挂在后台一个叫任务队列的东西,先执行下一条数据。等到1000秒后才会执行前面这条挂起的数据。)由于js是单线程运行的(设计原因),只能一条一条执行,因此异步就变得非常关键。
通过刷新页面,这个页面就会出现几个数据包(报头)。其中就可以看到一条关于腾讯招聘的数据信息及其url,此时可以将其放到postman中获取具体的信息。

进入postman(下载很简单,默认ok就行),放入url进行一个发送,可以看到下面得到的响应数据,将其拖到最下面发现总行数为208行。因为要判断数据是静态还是动态,需要翻到这个网站页面的第二页查看情况。


发现其数据的总数依旧是208。正常情况来看,如果数据发生了变化,其所对应的代码量应该也是会出现变化的。但这里依旧是208,并没有改变,因此可以初步判断此处的数据是一个动态获取的数据,通过服务器内一些内部的调用来回显信息。

确定为动态数据后,可以先对url进行判断。可以发现这里只有index那么一个参数是有变化的(timestamp是个时间戳,判断时间用的,这里没啥用),因此后续爬取的时候只需要对index部分进行相关的更改即可。

确定数据类型后,则需要观察有哪些数据包的字段是可以爬取的,这里postman里可以直接看到,选取需要的数据进行爬取。(ps:有些网站postman可能无法直接将数据查出来,可以在上面的headers中添加一些refer,cookie来完成更详细的数据读取,还有些可能还有编码,需要去解)
三.pycharm中的设置
得到的需要的相关信息后,则要对pycharm中的爬虫模块进行配置,首先便是配置setting中的数据。

由于咱们是在爬取对方的数据,理论上来说这是违法的,并且直接进行爬取的话,对方网站也有相应的反爬措施,因此需要构造一些伪造的请求来对网站进行访问。这里也是从网上找了一些伪造的UA头,而后放在这个#user_agent下,后续进行调取来伪造我们是一个正常的网页对其进行访问。

而后进入middle-ware中间件,在download下对刚刚引入的ua头进行随机的引用。(为什么在download下引用是scrapy的工作原理,建议百度查查)

而后便在item下对所需要得到的数据进行简单的应用,表示⽤它来存储爬取到每⼀条职位信息对应字段的值,它继承的是scrapy.Item,这个是必须继承的,否则这些字段的值是⽆法保存到⾃定义的变量⾥⾯

将pipe这个注释取消掉(pipe是scrapy中的存储数据的管道,具体工作原理请百度),并且添加上
"scrapy.downloadermiddleware.useragent.UserAgentMiddleware": None(作用,确保一开始中间件没有使用ua头,而是调用那些外部导入的伪造ua头)
三:爬虫主体


由于url过长,因此使用拼接的方法将其连起来。因为pageindex是翻页的信息,因此后续这个东西是要一直变的,所以把这个参数放到最后,方便后续的使用。再定义一个起始页,将它与url拼接(str的形式)。

这里需要先提前导入一下Test2中(我的项目名)中的items文件,导入items.py中的类,否则下面引用的时候会出现报错。(ps:这里出现红线没关系,也能正常使用)

这里便是爬虫方法中的一个主体,其中,刚初始化时parse这个爬虫函数是只有两个参数的,而实际使用的话该函数需要再加一个参数才能正常运行。因此搜索了一下函数文档,发现需要加上一个关键字的传递参数kwargs(前面的两个*是默认格式) 由于爬的数据都是字符串且都是json格式的,所以通过json.loads转换成一个反序列化的结构,从而更方便的得到key也就是数据(具体请查反序列化是啥 咱就一写作业的)。并使其存储导data_obj里面(这玩意叫a叫b都行),而count则是其中的总数据,posts则是数据存储的一个位置。里面有相关的数据信息。因此通过这个data_obj去取得data下面的Posts里面的数据以及count总数,并对此进行反复循环得到相关的数据。后面那一串便是通过item中定义的数据去与posts中的数据一一对应,最后通过yield将其循环反复得到数据。ps(这个网址也需要看一下,直接导入网址是无法成功的,这里选择将url进行一个简单的拼接得到(可以通过postman看到具体情况))

下面这些则是进行一个基本的页数判断。可以通过postman发现,总数据总共是有2882条,如果只是进行一个简单的+=判断,这个是无法得到最后的那几条数据的,会出现小数。因此这里通过累计加1,调用math.ceil这个函数(向上取整,举例:一个3.15的数据,通过这个函数,最终取值为4;一个18.33的数据,通过这个函数最终取值为19)因此通过该函数来得到数据,重新写入url,通过scrapy获得一个请求,拼接上相关的url地址,再写一个callback(回调方法),使整体定义的这个parse重新循环,接着爬取数据。(self可以理解成我的,这里self写在parse函数内,因此可以理解成parse的xxx,来确保引用的page_index和parse是属于parse的)


四.pipelines配置(保存数据的)

这里首先定义一个初始化的方法,通过写的方法去创造一个doucment.txt的文件(文件名随意)python中w的含义:打开一个文件只用于写⼊。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。如 果该文件不存在,创建新文件。因此这里就算没有这个txt文件也没关系,而encoding则是确认编码形式。
dict_item=dict(item):将item对象转换成字典对象,后续使用字典去进行爬取
json.dump则是将此前反序列化的对象转换成一个序列化的文本(爬虫时将其反序列化是为了更加方便的得到数据中的值,而这里又将其序列化出来则是为了让输出的信息更加完整),并将其复制给text,加上ensure_acill确保是以文本的形式出现。而后将序列化后的text写入到文件中。
最后定义的close函数则是为了关闭原先定义的document.txt文本,python中 写入文件的话需要将其关闭,不然可能会出现一些异常。
五.最终结果
全部完成定义后,在命令行中通过scrapy crawl zuoye对其进行爬取,crawl为爬取的命令,zuoye则是创建的项目 就是那个name。所得的数据将会存入定义的document.txt文件中。




ps:有可能会出现以下错误,这个是由于python中一个叫twisted的配置文件版本导致的,可以选择加到最高版本或降点版本看看,如果还有问题可以尝试降低python的环境来进行配置。文章来源:https://www.toymoban.com/news/detail-855367.html
 文章来源地址https://www.toymoban.com/news/detail-855367.html
文章来源地址https://www.toymoban.com/news/detail-855367.html
到了这里,关于pycharm爬虫模块(scrapy)基础使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[爬虫]3.4.1 Scrapy框架的基本使用](https://imgs.yssmx.com/Uploads/2024/02/598070-1.jpg)