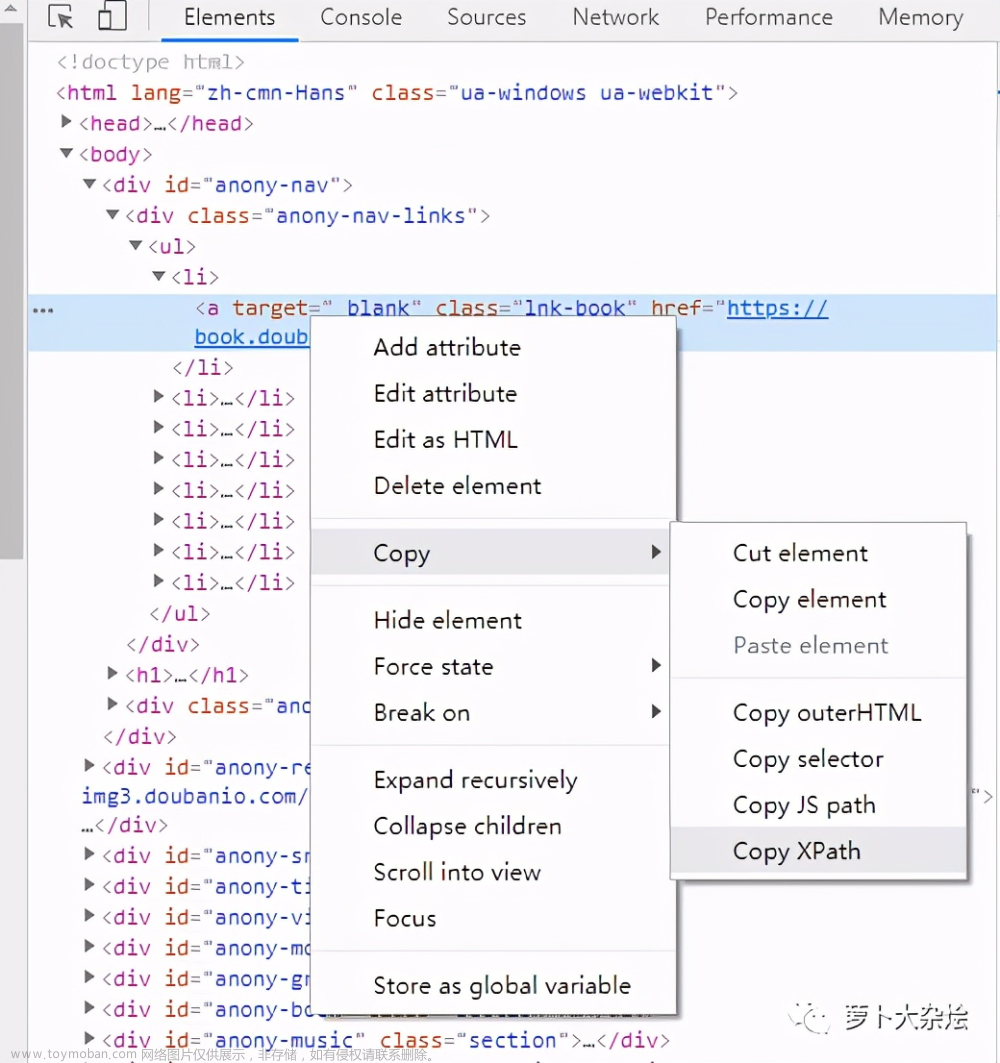
audio_DATA_get = requests.get(url=audio_DATA,headers=headers)
audio_DATA_get_text = audio_DATA_get.text
audio_DATA_download_url = re.findall(‘“src”:“(.*?)”’,audio_DATA_get_text)
print(audio_DATA_download_url)
download_data_url = audio_DATA_download_url[0]
try:
open_download_data_url = urllib.request.urlopen(download_data_url)
except:
print(download_data_url,“---->ERROR!”)
read_download_data_url = open_download_data_url.read()
def download_data():
with open(“%s.mp3”%data_name_2,“wb”) as writes:
writes.write(read_download_data_url)
download_data()
download_2()
第四步
以上就是这段代码的主要实现,最后使用print()函数提示音频下载完成。
完整代码
import random
import time
import requests
import urllib.request
import re
book_url = “https://www.ximalaya.com/album/22088719”
user_agent = [
“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3”,
“Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:54.0) Gecko/20100101 Firefox/54.0”,
“Mozilla/5.0 (Windows NT 10.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.3”,
“Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.3”,
“Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.101 Safari/537.36 Edg/91.0.864.54”
]
headers = {“User-Agent” :random.choice(user_agent)}# 采用user-agent随机反爬机制
url_get_ximalaya = requests.get(headers=headers,url=book_url)
url_get_ximalaya_webcode = url_get_ximalaya.text
def with_url_get_ximalaya_webcode():
with open(“url_get_ximalaya_webcode.txt”,“a”,encoding=“utf-8”) as w:
w.write(url_get_ximalaya_webcode)
with_url_get_ximalaya_webcode()
data_id_name_code_page_1 = re.findall(‘“trackId”😦\d+),“isPaid”:false,“tag”:0,“title”:“(.*?)”’,url_get_ximalaya_webcode)# 1集------>29集
data_id_name_code_page_2 = re.findall(‘“trackId”😦\d+),“trackName”:“(.*?)”’,url_get_ximalaya_webcode)# 21集------>120集
print(“加载列表清单…”)
time.sleep(2)
def download_1():
for data_id_1,data_name_1 in data_id_name_code_page_1:
audio_DATA = f"https://www.ximalaya.com/revision/play/v1/audio?id={data_id_1}&ptype=1" #---->接收data_id至url数据包
time.sleep(0.1)
print(“正在下载—>%s”%data_name_1)
audio_DATA_get = requests.get(url=audio_DATA,headers=headers)
audio_DATA_get_text = audio_DATA_get.text
audio_DATA_download_url = re.findall(‘“src”:“(.*?)”’,audio_DATA_get_text) #提取下载链接
print(audio_DATA_download_url[0])
download_data_url = audio_DATA_download_url[0]
try:
open_downloda_data_url = urllib.request.urlopen(download_data_url)
except:
print(download_data_url,“---->ERROR!”)
read_download_data_url = open_downloda_data_url.read()
def download_data():
with open(“%s.mp3”%data_name_1,“wb”) as writes:
writes.write(read_download_data_url)
download_data()
#print(data_name)
#print(audio_DATA)
download_1()
def download_2():
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数网络安全工程师,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年网络安全全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-2.png)
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-3.png)
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-4.png)
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-5.png)
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-6.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上网络安全知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加VX:vip204888 (备注网络安全获取)![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-7.png)
一、网安学习成长路线图
网安所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-8.png)
二、网安视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-9.png)
三、精品网安学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-10.png)
四、网络安全源码合集+工具包
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-11.png)
五、网络安全面试题
最后就是大家最关心的网络安全面试题板块![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-12.png)
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-13.png)
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频,2024年程序员学习,爬虫,python,音视频](https://imgs.yssmx.com/Uploads/2024/04/855397-14.png) 文章来源:https://www.toymoban.com/news/detail-855397.html
文章来源:https://www.toymoban.com/news/detail-855397.html
人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
[外链图片转存中…(img-Mj9DFVpR-1712566660996)]文章来源地址https://www.toymoban.com/news/detail-855397.html
到了这里,关于[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!