以下为一些知识点的简单记录,没有逻辑性,大多以分条形式展示。
由于是粗读,且个人水平有限,所以可能有些地方理解的不够准确,仅供参考。如有问题欢迎指正。
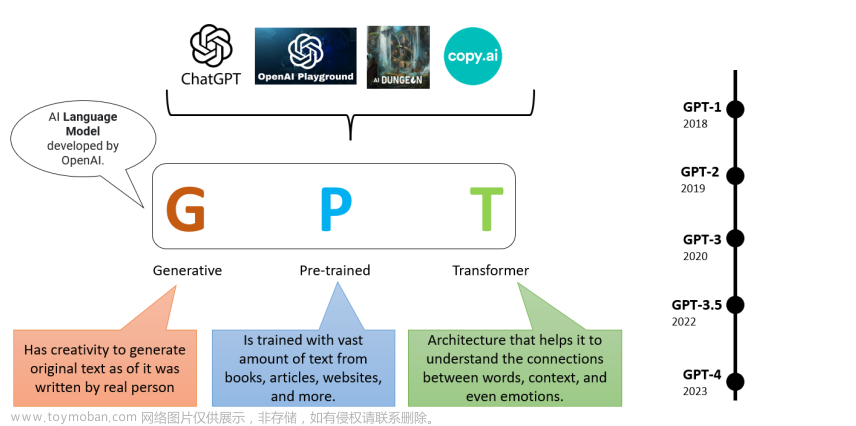
第0章 前言
类似产品:
第1章 ChatGPT的由来
(一)自然语言处理任务
包括:文本分类、语言翻译、情感分析、问答系统、对话生成。
(二)ChatGPT所用数据数据大小
1、OpenAI公司没有单独公布过细节
2、一位人工智能领域知名博士曾介绍过,根据OpenAI公司公开数据推测,GPT-3所有训练数据集大小一共有753.4G。
分布如下:

3、其他方面消息称,GPT-3语料高达45T。由于与博士说的相差太大,所以猜测是数据来源未精选前的规模。
4、ChatGPT的规模上面说了,那它能够在多大程度上代表互联网呢?经过一些列的推算,我们可以武断认为整个互联网上的文本大概是1000T。
所以大概是753.4G:1000T,抑或是45T:1000T。
(三)ChatGPT的神经网络模型有175亿个参数
(四)模型压缩 方案
即使获得可靠的预训练大模型,在本地化部署环境做推理计算也有较高成本。对特定领域进行微调也有一定难度。
可能后续需要引入一些模型压缩方案。例如:量化、蒸馏、剪枝、参数共享等。
知识蒸馏是之前大模型压缩的常用方案,但目前很难直接进行。(原因:ChatGPT只开放API,不开放模型)
一种可能的途径是利用ChatGPT的思维链功能,即,将问答记录里的思维链过程作为压缩小模型的训练数据。(但OpenAI明确禁止商用)
第2章 ChatGPT页面功能介绍
(一)ChatGPT聊天套路
我们把给ChatGPT输入的问题文本叫Prompt(提示词)。
Prompt Learning提示学习 = => In-Context Learning上下文学习 ==> Chain of Thought思维链
只有当模型参数大于100B(100亿参数)时,思维链的威力才能发挥出来。
(二)ChatGPT机制
ChatGPT使用的是基于Transformer的自回归语言模型,这种模型采用了自注意力季知(Self-Attention Mechanism),它可以让机器理解和捕捉对话的上下文,进而实现上下文连续对话。
ChatGPT还采用了LSTM长短期记忆模型,让ChatGPT准确地捕捉对话的上下文,从而实现更好的上下文连续对话能力。
(三)重新生成(相同问题和上下文生成不同回答)
原因/原理:
1、ChatGPT是一个基于神经网络的语言模型,其生成的回答是基于其在训练数据中学习到的语言规则、语义知识和上下文信息等因素。因此,对于同一个问题,ChatGPT可以根据不同的上下文和语境生成不同的答案。
2、ChatGPT模型中的权重参数是通过随机初始化开始训练的,而训练过程中也会受到随机性的影响。
3、ChatGPT还具有一些可以控制生成回答风格和特定输出的参数和超参数,如temperature、max_tokens、top-p采样等,这些参数也会影响生成的回答。
(四)提前终止
能够节省计算资源。
我们每次提问,ChatGPT都会基于自然语言处理(NLP)技术和深度学习算法进行大量的计算,不断地从历史文本中提取信息来预测下一个单词或短语,直到生成整个回答。
第3章 ChatGPT的法律风险
1、简单直接要求作恶的提问×
2、知名虚拟人物二次创作的要求×
3、(Z)(治)立场×
第4章 ChatGPT必坑指南
1、作诗×
2、有些回答是编造的(如新函数、新功能。在它的语料库中是没有的,基于它的算法,它会基于上文文字编造一个聊天的结果)
3、生成正则表达式×
第5章 ChatGPT场景案例
列举场景:自然语言处理类任务、编程辅助任务、格式化处理任务、多轮问答的开放式任务。
提问技巧:
- 小样本(few-shot)提示:先给ChatGPT主动提供几个例子,然后再提问。
- 思维链(CoT,Chant of Thought)提示:先给ChatGPT提供一个例子,然后主动解释例子中的推导过程,然后提问。思维链方法可以和小样本提示方法一起使用。
- 零样本(zero-shot)提示:在提问时,不做解释而是直接要求ChatGPT自己输出思考的过程。因为ChatGPT是逐字生成的,所以它自己生成的思考过程本身也会影响后续计算,提升效果。可以说是CoT的一种变体。
- 广度拆分问题:学术叫法是自一致性(self-consistency),也是CoT的一种变体,提供多种不同的推到过程,得到相同的最终结果。这样可以提升结果的稳定性。
- 深度拆分问题:学生叫法是子问答(self-ask),也是CoT的一种变体,主要是把推导过程变成拆解多个子问题在逐一回答的过程。为了回答主问题,先要回答第一个问题、第二个问题……最终才知道答案。事实上,由于ChatGPT本身的交互形式和字数限制,也鼓励我们在对话中主动思考问题,拆解问题,一步一步探索问题答案。
(一)提取概要
1、文本总结
2、逆向prompt:先复制一个种草秀原文,让ChatGPT提取prompt,然后根据提取的prompt,让ChatGPT再写一篇种草秀。
(二)stable diffusion prompt生成
stable diffusion:稳定扩散
1、直接生成
与上面逆向prompt类似
想要生成一个图像,先让ChatGPT给出关于该主题的英文prompt。
然后再给出某知名作者的风格,或者明星的外形,让ChatGPT给出prompt,这样我就得到作品创作风格和人物的外形prompt了。(为了规避版权风险)
将二者合并就可以创作了。
比如,主题:“冬天奔跑的小女孩”= => 生成prompt1
宫崎骏画风 = => 生成prompt2
新垣结衣的外形特征描述 ==> 生成prompt3
将这三个prompt合并,得到新图像。
2、思维链生成
相给个图片和prompt,让ChatGPT去学习,对于学习的结果进行调整,指出正确的规则。
再给出多个复杂格式的prompt示例,让ChatGPT加强理解并仿写。然后出题,让它生成一个新的prompt,调整后根据这个生成图片。
(三)情感分类
(四)词格分类
命名实体识别(NER,named entity recognization)和词性归类是NLP技术中的关键一环。
如给出一段文字,它把里面的名词、动词、副词甄别出来。
指挥:动词,作谓语
三条:数词,做数量修饰语
河流:名词,做宾语
(五)数据集模拟生成
简单来说,将一些人工编写好的或者挑选好的极少数训练数据,交给ChatGPT进行仿写,可以得到多出两三个数量级的新训练数据,这样有助于大语言模型的微调训练。
(六)生成复杂密码
如:
长度=12,大写=2,数字=3,特殊=3
生成的密码:D7#pL8%T3@k9
(仔细一看,并不符合我们的要求)ChatGPT数学水平差。
(七)多语言翻译
(八)生成代码
我用文心一言,生成了与书中示例几乎一样的代码:
问题:请使用python语言的flask框架实现一个API服务,用户可以通过GET请求发送城市名称,获取到该城市当天的天气情况
不同的是,ChatGPT直接给出了网站的url,而文心一言只给了一个模拟数据。
ChatGPT上面的代码可以直接执行,执行的话需要提前注册这个网站的账户,获取一个API key即可。
文心一言提供的回答结果可通过复制我上面的问题后自行百度。
(九)代码解释
(十)编程语言转换
(十一)服务器体验沙箱
(十二)网页自动化
(十三)生成知识图谱
请你生成一部分红楼梦中的知识图谱,并转换成Neo4j格式的数据插入语句。
书中ChatGPT生成失败了,在这种情况下,需要排查下prompt的问题。
ChatGPT说懂红楼梦,但无法生成Neo4j的插入语句。
那么就检查一下ChatGPT是否真的懂红楼梦。
提问:请你以三元组的形式生成红楼梦中的知识图谱
回答:
(贾宝玉,是,贾母的孙子)
(贾母,是,贾宝玉的祖母)
(林黛玉,是,贾宝玉的表妹)
(贾宝玉,爱,林黛玉)
(薛宝钗,是,贾宝玉的表妹)
(贾宝玉,爱,薛宝钗)
…
(贾宝玉,钟情于,落花生)
从输出结果往下看,准确度逐渐降低。
为了训练ChatGPT变得准确,首先给它一段文字,书中是全书开头宝黛初见一章的一段文本,然后要求变为知识图谱,这下对了。
然后排查ChatGPT生成Neo4j的能力。将刚才的知识图谱转换为Neo4j发现也对了。
这时就按照之前提到过的技巧,让ChatGPT一步一步完成。
具体就是在第一步失败的prompt后面加上这句:请你生成一部分红楼梦中的知识图谱,并转换成Neo4j格式的数据插入语句。Let's think step by step.
然后ChatGPT就一步一步把操作步骤写出来了。
结果与文心一言类似,不同的是,文心一言一次就成功了:
但是从ChatGPT被优化后的结果看,似乎更全面。
(十四)数据可视化
Grafana是开源社区最流行的数据可视化软件,一定程度上也和superset一起被视为tableau等商业BI的开源替代品,很多IT团队、科研团队都会使用Grafana来做数据监控、挖掘分析。
Grafana支持通过JSON字符串的方式直接定义整个仪表盘的所有细节参数。因此我们可以尝试让ChatGPT直接针对特定场景给出最终的JSON配置,直接贴入Grafana即可。
测试:对数据中心基础设施主机层监控做一次咨询,看看ChatGPT是否可以同时给出主机层应该监控哪些指标,采用什么统计分析方法,做什么类型的可视化,以及最后生成对应的JSON配置。
验证:打开一个frafana产品界面,单击"create dashboard",切换到setting中的JSON mode,把ChatGPT输出的JSON完整复制粘贴进去。保存后命名仪表盘(书中名称"Datacenter Health Score Monitor")。
grafana软件安装部署和使用细节,不详述。
刚才提到的superset等其他BI产品,也可以利用ChatGPT这么操作。
(十五)Leetcode
提问问题后,ChatGPT会给出代码答案并作出解释,帮助我们更好的理解掌握相关知识。基于这个问题,可以拓展思路,延伸出更多问题,用于学习和面试。
同时要对答案的真实性进行验证,小心被错误答案误导。
(十六)编写PRD需求说明书
PRD:Pruduction Requirement Documentation,产品需求文档
还有一些用法,如私房菜推荐、旅游攻略、表格处理什么的,略。
第6章 当前热门AI应用
(一)notion AI笔记
利用数据库block,可以实现敏捷看板、日历、画廊等诸多高级功能。
免费试用20次后,月卡10美元。(好的,当我没说……)
(二)Copilot编程助手
通过写注释就能生成代码。如生成斐波那契数列求和函数、贪吃蛇小游戏。
1、免费体验60天,然后每月10美元。
2、代码大差不差,参数传递等问题仍需要调试。
(三)Character.AI定制角色
定制一个AI角色。
(四)AIPRM扩展
网页插件。里面有一些模板,还可以投票啥的。
第7章 ChatGPT配合其他AI能力的应用
(一)和Dall2配合生成故事绘本
这个挺有意思的。
第一步,让ChatGPT生成一个场景。书中是一个关于各国程序员状态对比的笑话。
第二步,考虑做一个四格漫画。继续让ChatGPT生成一个prompt。
那么针对每一个图片,ChatGPT都会有一段描述了。
image1、image2……image4
大致思路是用keyboard、app、paper来做核心区分。尝试在免费的blue willow频道上运行prompt生成的图片,可以得到一个四格图片。
(下面还有一些具体步骤,大概就是单击这个按钮那个按钮的,不写了。然后图片就由草图变得越来越清晰和丰富了)
最后,把生成的插图拼接成四个漫画,可以利用PS、美图秀秀等。
书中的作者用了1个小时的时间。对于非美工专业的人来说,这个是不错的选择呢。
(二)解析Bing Chat逻辑
在必应搜索引擎中嵌入ChatGPT。
(三)和D-ID配合生成数字人视频
综合利用虚拟图片、剧本文案,生成一段对应的数字人短视频。
(四)BLIP2多模态聊天
(五)图文生成视频
第8章 OpenAI API介绍
(一)优势
如果希望将OpenAI的功能集成到自己的项目或者产品中,用于提升产品的交互或者为产品增加亮点,或者希望使用OpenAI解决复杂任务,那么OpenAI的API接口正好可以帮助实现这些想法。
OpenAI API是一个基于深度学习模型训练的自然语言处理API,旨在帮助用户生成、理解和处理自然语言文本。
可应用于各种任务,包括但不限于:自动化文本生成、语言翻译、内容分类和提取、智能问答等。
由于其具有高度可定制的特性,OpenAI API可以根据用户的需求进行灵活的调整和优化。
(二)几个常用模型
- GPT4系列:大型多模态模型。具有广泛的尝试和高级推理能力。
- GPT3.5系列:可以理解并生成自然语言或代码。
- Dall-E:可以根据自然语言的描述创建逼真的图像和艺术作品。
- Whisper:通用的语音识别模型,可以将音频转换为文字。
- Codex:可以理解和生成代码,它的训练数据包含自然语言和来自GitHub的数十亿行公共代码。
(三)付费
OpenAI API是商业服务,模型不同费用不同。
按token计费,每1000个token作为一个计费单元。
什么是token?
token是OpenAI对文本进行自然语言处理分词后切分成的最小字符序列。
举例:Hello ChatGPT World!
这句话会被切分成Hello、Chat、G、PT、World、!这六个token。
总结
总的来说,这本书比较浅显,用了一个下午粗粗看完。
技术上的高难度几乎没有,作为了解够我们普通人没事的时候吹吹牛了。
也算是对ChatGPT有个初步的认识,包括怎么提问,如何更高效的利用它,用它可以做什么,在遇到的什么事情的时候可以找它解决。文章来源:https://www.toymoban.com/news/detail-855400.html
以上。文章来源地址https://www.toymoban.com/news/detail-855400.html
到了这里,关于【机器学习】《ChatGPT速通手册》笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!