TCP协议有了拥塞控制机制,为什么还会网络拥塞?
随着骨干带宽增长,拥塞被阻滞在接入网,大规模拥塞崩溃难再呈现,tcp 拥塞控制(不仅限于 tcp,但以 tcp 为主线来说)从避免崩溃,保证可用性逐渐转到提高效率。
过程曲折而漫长。
起初 aimd 挺好,为了更好,bic/cubic 相继出炉,此过程正与 linux 蓬勃发展同步,大概从 1990 年初一直持续到 2005 年前后,linux kernel 内置所谓 “拥塞状态机” 逻辑,以至于完全不同于传统 aimd 的 delay-based cc 比如 vegas 竟无处安放。
拥塞状态机其实就是 loss-based cc 的抽象,将 “拥塞避免”,“快速重传” 等这些状态与 tcp 语义的传输和重传强制捆绑,以至于只要出现丢包进入快速重传,必须无条件执行固定逻辑,比如降窗(比如 prr)。这种框架下,如果想在丢包时不降窗就无从谈起,显然 vegas 不适合这框架。但由于这种方式工作的足够好,vegas 几乎被遗忘。
进入 2010 年代,随着摩尔定律效应减弱,主机带宽逐渐追平交换带宽,而移动互联网兴起,图片,视频等大流量激增,单位带宽逐渐吃紧,带宽资源不能再继续以粗放方式被使用,另一方面,受限于时延 qoe,buffer 不能继续增大,cc 开始以带宽利用率为目标,pacing 代替突发降低报文到达率,减少对 buffer 的依赖。
bbr 在此背景下产生。
为支持 bbr,linux kernel 引入 cong_control 回调,允许 cc 自定义行为,开辟了拥塞状态机之外的新路。
但直到今日这条新路上大量的代码都在处理 “兼容公平性”。
当年 vegas 被诟病不能和 cubic 共存,解法其实是全网部署 vegas。如今 bbr 又落入寻求 “与 aimd(主要是 cubic) 公平混部” 的老路,而这些问题几乎不能彻底解决。
分布式网络是个博弈网络,即使 bbr 优秀到让人们明确想用 bbr 替换 cubic,但随着替换的进行,替换收益递减,人们的替换动机减弱,最终 bbr 占比将稳定在不到 80%,bbr 还是要兼容 cubic,因此 bbr3 或许是个好算法。
但数据中心则是个不同的场子。
如果在数据中心大搞公平混部就大可不必了,找经理开会能解决的事就不要用算法自适应。一个简单方法是增量部署算法默认设置在装机脚本,存量逐渐分批次切换。或全部 cubic,或全部 bbr,或全部 vegas。
最近一直强调同质,卡车从不考虑与轿车碰撞时的公平性问题。核心还是那些车轱辘话,让算法尽量少做甚至不做判断,猜测,评估,针对的事,简单才能高效,大一统对效率反而是拖累,俾斯麦明白的道理,将奥地利排除在帝国之外,主打一个纯净。
暂时不说关于同质的话题了,说恶心了。接下来看 bbr。
不管哪个场子,也不管目标是避免崩溃还是提高效率,拥塞控制的核心都是 数据包守恒,在这个视角下重新审视 bbr,看它有什么问题:
具体可参考 bbr 模型 以及 更合理的 bbr。
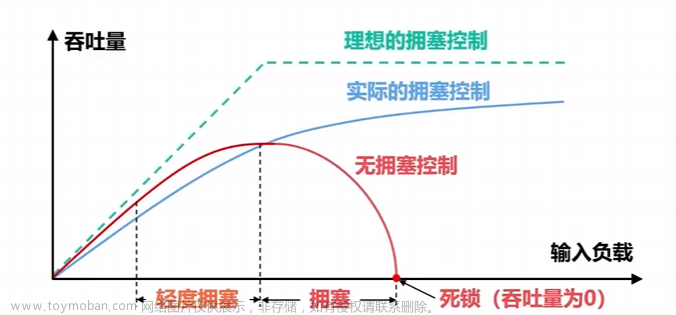
此前说过,bbr 看起来好只因为它的大开合动作,并且很多人理解的 “bbr 好” 就是和 cubic 相比 bbr 的吞吐更高,这是对拥塞控制最大的误解,你不光要看结果,还要看拿什么换的结果。其实 bbr 选的操作点非常不稳定,所以无法自适应收敛,需要一个状态机不断进行刺激和反应,总体上大开合的意思就是激进。如果操作点对了,什么都不需要做就能收敛。
看上图的下半部分,合理的 bbr 操作点更偏右,在这个操作点上,和理想情况相反,bbr 需要持续占据一些 buffer 空间,用它来做带宽变化的自动探测。
bbr 用 maxbw 追踪最佳操作点是追不到的,在多流共享带宽时更是捕风捉影。如果办不到就不要办了,计算是滞后的,且根本算不准,那么追踪 max(bw / rtt) 就豁然开朗:
- 在 winmax 中追踪 alpha rounds 的 bw / rtt,将其 bw 记为 b;
- 在 winmin 中追踪 k*alpha rounds 的 rtt,记为 minrtt;
- 保持 inflight = b * minrtt + beta。
这就避开了复杂的状态机,probe,drain 等逻辑。围绕上面的 3 步算法做任何事都行,其实只这 3 步就够了。
本文不详细聊这个算法动力学,简单推理一下,如果有新带宽,max(bw / rtt) 会更新,bw 增加,inflight 增加,如果有效带宽减少,早晚 max(bw / rtt) 会滑走而更新,bw 减少,inflight 减少,而如果 bw 和 rtt 同时增加或减少,minrtt 在更长周期不改变,算法就可以自适应它们而改变 inflight。
解释一下最后一步为啥要 + beta,这是 vegas 里的办法,目的是 “始终在 buffer 中保留一些报文”,效果是:
- 有流退出,这些报文可以瞬间分享腾出的带宽;
- 有流进入,这些报文避免当前流被挤占而抖动。
是不是简单又有趣。
那么 pacing 哪去了?和传统 bbr 不同,pacing 退居二线,而 inflight 成了第一控制要素,只要保持 inflight 就那么多,pa 不 pacing 不重要,反正都要回来,核心还是守恒律。
人们对 pacing 的误解在于以为 pacing rate 是端到端的,但它只对第一跳有效。数据包在网络转发过程中,其形式完全受交换机(等一切转发节点)当前状态的影响,在没有任何 aqm,qos 配置的简单 fifo 情形,一条流的 pacing rate 完全由该交换机当前的 buffer 构成决定。
端到端控制需要控制 inflight,而不是 pacing rate。
pacing 按照 delivery rate 的 n 倍吐,简单给前面第一跳交换机 buffer 留点 time slot,不用太精确算计,因为算了也没用,统计复用要按统计方法来,抓住统计量,追踪,过滤它们,做出判断,执行守恒律。
拥塞控制的核心是在 pipe 中保有多少 inflight,而不是以多大的 pacing rate 发送,所以控制要素还得是 cwnd,而测量 delivery rate 只做采集 bw / rtt 而计算 inflight。
好,该总结一下了。
tcp 拥塞控制从最初 1980 年代末的 aimd 随着 linux kernel 经过 1990 年代直到 2010 年代引入 bbr,要分清楚新的,旧的,就知道哪些是核心,而哪些是为了兼容公平性。其中摩尔定律,移动互联网,视频流的发展也对 tcp 拥塞控制的形态产生了甚至决定性的影响。
提到拥塞控制就是慢启动,拥塞避免,快速重传那一套非常教条,拥塞控制和丢包检测和重传是没有关系的两件事,恰巧 tcp 在初期实现 linux kernel 的拥塞控制算法时作为内置硬编码实现,而后来模块化时又没有将其分开,埃里克作为后来的妹忒呢儿自己可能对这方面也不是非常清楚,本没关系的逻辑就被拥塞状态机关联了起来,但如果网络发生拥塞,用 inflight = 100 来控制拥塞,这 100 个报文中并不规定哪些是新报文哪些是重传报文。
30 多年的发展让 tcp 拥塞控制算法自发多样化,但兼容公平性并不是每个场景都需要考虑,比如数据中心。bbr3 作为以兼容公平性为目标的算法,它进入通用 linux kernel 的目标或许能实现,但作为 bbr 本身,bbr4,bbr5 应该在其提高带宽利用率以及自身公平性方面有更多迭代。
最后,我认为以守恒律为核心的 inflight 控制才是高尚的,E = max(bw / rtt) 是一个好收敛点,以 inflight = bw * minrtt + beta。而不是捕风捉影的 pacing 计算。文章来源:https://www.toymoban.com/news/detail-855473.html
浙江温州皮鞋湿,下雨进水不会胖。文章来源地址https://www.toymoban.com/news/detail-855473.html
到了这里,关于大历史下的 tcp:从早期拥塞控制 到 bbr 再到未来的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!