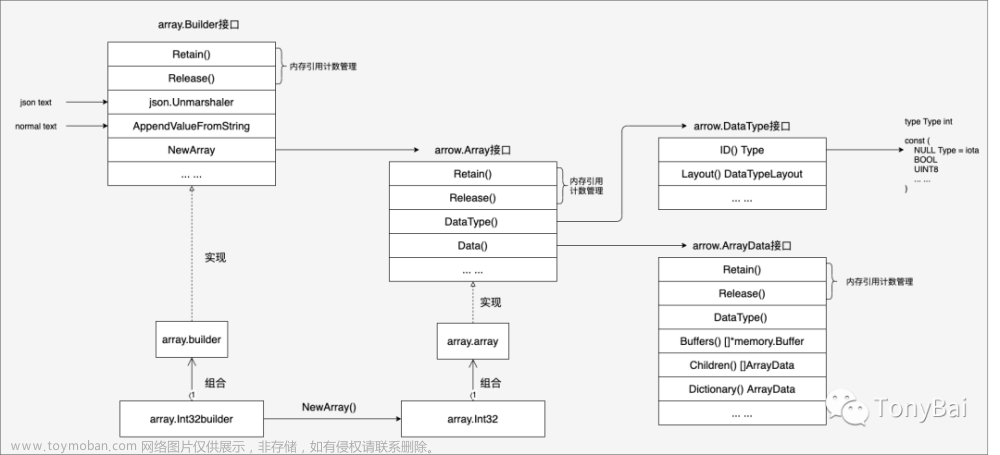
如何在apache Arrow定位与解决问题
最近在执行sql时做了一些batch变更,出现了一个 crash问题,底层使用了apache arrow来实现。本节将会从0开始讲解如何调试STL源码crash问题,在这篇文章中以实际工作中resize导致crash为例,引出如何进行系统性分析,希望可以帮助大家~
在最后给社区提了一个pr,感兴趣可以去查阅。
https://github.com/apache/arrow/pull/40817
背景
最近想修改一下arrow batch的大小,当调整为65536后发现crash,出现:
terminate called after throwing an instance of 'std::length_error'
what(): vector::_M_default_append然后通过捕获异常gdb找到异常位置,最后拿到堆栈,发现位置是在join里面构建哈希表侧的partition数组出了问题:
prtn_state.key_ids.resize(num_rows_before + num_rows_new);即问题转化为:resize操作为何引发throw?
研究了一下STL代码发现,会遇到两种场景,先把STL代码精简一下贴出来给大家看看:
if (__navail < __n) {
const size_type __len =
_M_check_len(__n, "vector::_M_default_append");
}
size_type _M_check_len(size_type __n, const char* __s) const {
if (max_size() - size() < __n)
__throw_length_error(__N(__s));
}其中最核心的就是_M_check_len函数,看到这个判断能想起哪两种场景呢?
场景1:内存确实不足了,超过了vector的max_size,此时会抛这个异常。
场景2:
__n传递的是一个负数,由于是size_t类型,则会变为超大值,从而抛出异常。
场景1在我们系统当中通过查看内存不会遇到,于是转到场景2,首先是猜测是个负数,然后搞了个log包,上去测试发现确实是这个问题,可以看到rows_new变为负数了。
part id 15, dop_ = 105,prtnid + 1 ranges = 0,prtnid ranges = 61434, part size:0, rows_new: -61434, cap: 0既然这里知道原因了,那么下一步就得继续分析为何会产生负数?
num_rows_new是有分区的range决定的,下面有个公式计算产生了负数
int num_rows_new =
locals.batch_prtn_ranges[prtn_id + 1] - locals.batch_prtn_ranges[prtn_id];继续跟进找到PartitionSort的Eval,里面有几处非常需要注意:
ARROW_DCHECK(num_rows > 0 && num_rows <= (1 << 15));首先第一个是这个断言,我明明传递的是65536,明显大于这里的32768,为何没有断言成功?事后发现这里是release包,只会报warning,不会fatal。
随后继续往下看,看到了一个比较明显的类型uint16_t,这个玩意就是在计算sum,而要让num_rows_new为负数,只有两种可能:
场景1: locals.batch_prtn_ranges[prtn_id + 1] < locals.batch_prtn_ranges[prtn_id]
场景2: locals.batch_prtn_ranges[prtn_id + 1] 是负数且locals.batch_prtn_ranges[prtn_id]是负数或者locals.batch_prtn_ranges[prtn_id + 1] 是负数且locals.batch_prtn_ranges[prtn_id]也是负数并且大于前者。
uint16_t sum = 0;
for (int i = 0; i < num_prtns; ++i) {
uint16_t sum_next = sum + prtn_ranges[i + 1];
prtn_ranges[i + 1] = sum;
sum = sum_next;
}看了这段代码可以知道,场景1排除了,因为是自增的,最差情况是相等,那么就只能场景2,变为负数就不用说了,又碰到了溢出问题,所以可以推测uint16_t溢出了,这个值我们知道是65535,而65536刚好超过它,所以有问题!
至此,这一轮的debug调试与分析到此结束~
往期干货:
热度更新,手把手实现工业级线程池
快速拿下面试算法
 文章来源:https://www.toymoban.com/news/detail-855484.html
文章来源:https://www.toymoban.com/news/detail-855484.html
 文章来源地址https://www.toymoban.com/news/detail-855484.html
文章来源地址https://www.toymoban.com/news/detail-855484.html
到了这里,关于如何在Apache Arrow中定位与解决问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!