目录
实用篇-ES-环境搭建
1. 什么是elasticsearch
2. 倒排索引
3. elasticsearch对比mysql
4. 安装elasticsearch
5. 安装kibana
6. 安装IK分词器
7. IK分词器的词典扩展和停用
实用篇-ES-DSL操作文档
1. mapping属性
2. 创建索引库
3. 查询、修改、删除索引库
4. 新增、查询、删除文档
5. 修改文档
实用篇-ES-RestClient操作文档
1. RestClient案例准备
2. hotel数据结构分析
3. 初始化RestClient
4. 创建索引库
5. 删除和判断索引库
6. 新增文档
7. 查询文档
8. 修改文档
9. 删除文档
10. 批量导入文档
实用篇-ES-DSL查询文档
1. DSL基本语法
2. 全文检索查询
3. 精确查询
4. 地理查询
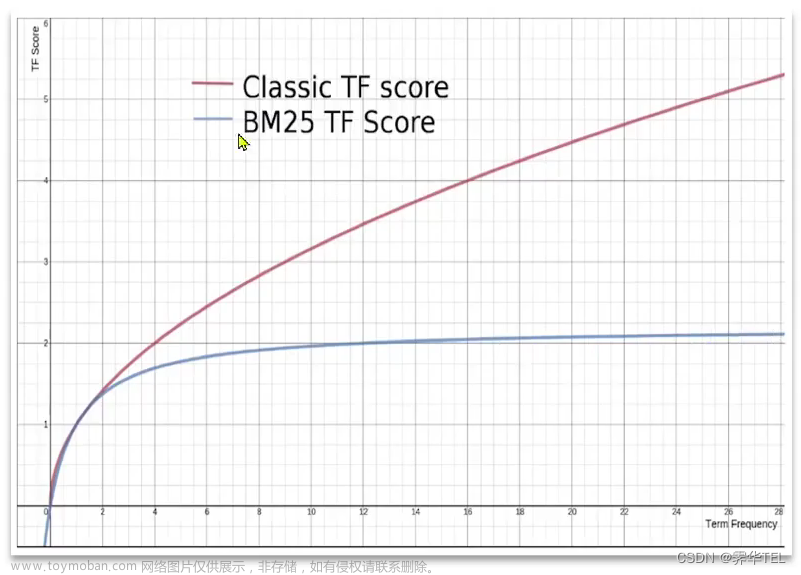
5. 相关性算分
6. 函数算分查询
7. 布尔查询
8. 搜索结果处理-排序
9. 搜索结果处理-分页
10. 搜索结果处理-高亮
11. 搜索结果处理-总结
实用篇-ES-RestClient查询文档
1. 快速入门
2. match的三种查询
3. 解析代码的抽取
4. term、range精确查询
5. bool复合查询
6. geo_distance地理查询
7. 排序和分页
8. 高亮显示
实用篇-ES-黑马旅游案例
1. 环境准备-docker
2. 环境准备-elasticsearch
3. 环境准备-mysql
4. 环境准备-项目导入
5. 环境准备-同步数据
6. 搜索、分页
7. 条件过滤
8. 我附近的酒店
9. 广告置顶
10. 高亮显示
实用篇-ES-数据聚合
1. 聚合的分类
2. DSL实现Bucket聚合
3. DSL实现Metrics聚合
4. RestClient实现聚合
5. 多条件聚合
6. hm-带过滤条件的聚合
实用篇-ES-自动补全
1. 安装拼音分词器
2. 自定义分词器
3. 解决自定义分词器的问题
4. DSL实现自动补全查询
5. hm-修改酒店索引库数据结构
6. RestAPI实现自动补全查询
7. hm-搜索框自动补全查询
实用篇-ES-数据同步
1. 同步方案分析
2. hm-导入酒店管理项目
3. hm-声明队列和交换机
4. hm-消息发送
5. hm-消息接收
6. hm-测试数据同步功能
实用篇-ES-es集群
1. 集群结构介绍
2. 搭建es集群
3. 集群状态监控
4. 创建索引库
5. 集群职责及脑裂
6. 新增和查询文档
7. 故障转移
实用篇-ES-环境搭建
ES是elasticsearch的简称。我在SpringBoot学习 '数据层解决方案' 的时候,写过一次ES笔记,可以结合一起看一下。
之前在SpringBoot里面写的相关ES笔记是基于Windows的,现在我们是基于docker容器来使用,需要你们提前准备好自己的docker容器以及掌握docker操作
常见的分布式搜索的技术,如下
- 1、Elasticsearch: 开源的分布式搜索引擎
- 2、Splunk: 商业项目,收费
- 3、Solr: Apache的开源搜索引擎

随着业务发展,数据量越来越庞大,传统的MySQL数据库难以满足我们的需求,所以在微服务架构下,一般都会用到一种分布式搜索的技术,下面我们会学分布式搜索中最流行的一种,也就是elasticsearch的用法。包括学习elasticsearch的概念、安装、使用。其中学习elasticsearch的使用的时候,主要通过两个方面,一方面是elasticsearch对于索引库(类似于数据库,把数据导入进索引库,导入的数据就是所谓的文档,我们要实现文档的增删改查)的操作,另一方面我们还会学习elasticsearch官方提供的Restful的API(也就是Java客户端),来更方便的操作elasticsearch
1. 什么是elasticsearch
elasticsearch(读 yī læ sī tǐ kě sè chǐ)
kibana (读 kī bā nǎ)
elasticsearch是一款非常强大的开源搜索引擎技术,可以帮助我们从海量数据中快速找到需要的内容
1、elasticsearch是elastic stack的核心,负责存储、搜索、分析数据。我们主要学习这个,elasticsearch底层实现是基于Lucene技术
2、Kibana是数据可视化的组件,也就是展示搜索出来的数据。elasticsearch的相关技术,了解即可
3、Logstash、Beats是负责数据抓取的组件。elasticsearch的相关技术,了解即可

Lucene是一个Java语言的搜索引擎类库(其实就是一个jar包),是Apache公司的顶级项目,由DougCutting于1999年研发
Lucene官网: https://lucene.apache.org
Lucene的优势
1、易扩展
2、高性能 (基于倒排索引)
Lucene的缺点
1、只限于Java语言开发
2、学习曲线陡峭,也就是API复杂不利于学习
3、不支持水平扩展,只负责如何实现搜索,不支持高并发、集群扩展
由于Lucene的缺点,诞生出了elasticsearch,与Lucene相比,elasticsearch(基于Lucene,且Compass是elasticsearch的前身)具有以下优点
1、支持分布式,可水平扩展
2、提供Restful接口,可被任何语言调用
elasticsearch的核心技术是倒排索引,下面会学
2. 倒排索引
传统数据库(例如MySQL)采用正向索引,例如给下表(tb_goods)中的id创建索引

elasticsearch采用倒排索引,例如给下表(tb_goods)中的id创建索引

总结
1、正向索引: 基于文档id来创建索引。查询词条时必须先找到文档,而后判断是否包含词条
2、倒排索引: 对文档内容进行分词,对词条创建索引,并记录词条所在文档的信息。查询时先根据词条去查询文档id,然后获取到文档
3. elasticsearch对比mysql
elasticsearch
elasticsearch是面向文档存储的,可以是数据库中的一条商品数据,一个订单信息。注意elasticsearch的文档是以json形式存储的,也就是说,我们把数据(也叫文档)存储进elasticsearch时,这些文档数据就会自动被序列化为json格式,然后才存储进elasticsearch
elasticsearch的索引: 相同类型的文档的集合。索引和映射的概念,如下图

下面的表格是介绍elasticsearch中的各个概念以及含义,看的时候重点看第二、三列,第一列是为了让你更理解第二列的意思,所以在第一列拿MySQL的概念来做匹配。例如elasticsearch的Index表示索引也就是文档的集合,就相当于MySQL的Table(也就是表)
| MySQL |
Elasticsearch |
说明 |
| Table |
Index |
索引(index),就是文档的集合,类似数据库的表(table) |
| Row |
Document |
文档(Document),就是一条条的数据,类似数据库中的行(Row)。这里的文档都是JSON格式 |
| Column |
Field |
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema |
Mapping |
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL |
DSL |
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
我们下面会学习映射的创建,以及文档的增删改查。这些操作在MySQL里面是通过SQL语句实现,但我们在elasticsearch中,会使用的是DSL语句来操作。
在elasticsearch中,当我们写好DSL语句,要通过http请求发给elasticsearch,elasticsearch才会响应,原因是在elasticsearch对外暴露的是Restful接口
上面基本都是在讲elasticsearch,那么是不是elasticsearch已经完全代码MySQL,答案并不是,两者擅长的事情不一样,如下
- 1、MySQL: 擅长事务类型的操作,可以确保数据的安全和一致性。一般用于增删改
- 2、Elasticsearch: 擅长海量数据的搜索、分析、计算。一般用于查询
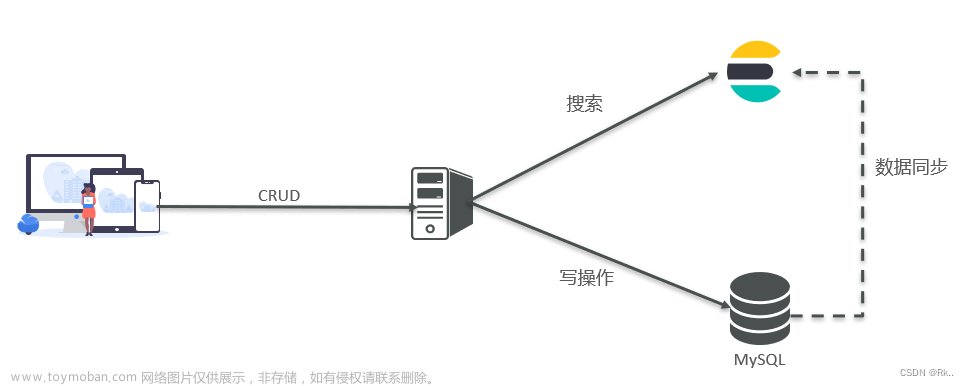
- 两者是互补关系,不是替代关系,因此在业务系统架构中,两者都会存在,让用户在MySQL里面增删改数据,然后MySQL把数据同步给elasticsearch,用户要查询的时候,就在elasticsearch里面进行查询
4. 安装elasticsearch
elasticsearch(读 yī læ sī tǐ kě sè chǐ)。注意elasticsearch、kibana、IK分词器,这三者通常是一起使用的
注意: 我们学习elasticsearch是基于docker容器来使用,需要你们提前准备好自己的docker容器以及掌握docker操作。elasticsearch一般都是搭配kibana(下节会学如何安装)来使用,kibana的作用是让我们非常方便的去编写elasticsearch中的DSL语句,从而去操作elasticsearch
【安装elasticsearch,简称es】
第一步: 创建网络。因为我们还需要部署kibana容器,因此需要让es和kibana容器互联

systemctl start docker # 启动docker服务
docker network create es-net #创建一个网络,名字是es-net
第二步: 加载es镜像。采用elasticsearch的7.12.1版本的镜像,这个镜像体积有800多MB,所以需要在Windows上下载链接安装包,下载下来是一个es的镜像tar包,然后传到CentOS7的/root目录
es.tar下载: https://cowtransfer.com/s/c84ac851b9ba44kibana.tar下载: https://cowtransfer.com/s/a76d8339d7ba4d
第三步: 把在CentOS7的/root目录的es镜像,导入到docker
docker load -i es.tar
docker load -i kibana.tar
docker images
第四步: 创建并运行es容器,容器名称就叫es。在docker(也叫Docker大容器、Docker主机、宿主机),根据es镜像来创建es容器
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
命令解释:
●-e "cluster.name=es-docker-cluster":设置集群名称
●-e "http.host=0.0.0.0":监听的地址,可以外网访问
●-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小,不能低于512
●-e "discovery.type=single-node":运行模式,例如非集群模式
●-v es-data:/usr/share/elasticsearch/data:挂载数据卷,绑定es的数据目录
●-v es-logs:/usr/share/elasticsearch/logs:挂载数据卷,绑定es的日志目录
●-v es-plugins:/usr/share/elasticsearch/plugins:挂载数据卷,绑定es的插件目录
●--privileged:授予数据卷访问权
●--network es-net :加入一个名为es-net的网络中
●-p 9200:9200:端口映射配置,向外暴露的http请求端口,用于用户访问
●-p 9300:9300:端口映射配置,是es容器各个节点之间互相访问的端口,由于我们是单节点部署,所以用不到
●elasticsearch:7.12.1: 镜像名称,要把哪个镜像创建为容器,注意带版本号

然后,在浏览器中输入:http://你的ip地址:9200 即可看到elasticsearch的响应结果
http://192.168.200.231:9200/
5. 安装kibana
注意,是跟上一节的 '4. 安装elasticsearch' 一起操作,也就是说同一个实验。注意elasticsearch、kibana、IK分词器,这三者通常是一起使用的
kibana (读 kī bā nǎ)的作用: 让我们非常方便的去编写elasticsearch中的DSL语句,从而去操作elasticsearch(读 yī læ sī tǐ kě sè chǐ)
第一步: 确保docker是启动的
# 启动docker服务
systemctl start docker
第二步: 加载kibana镜像。这个镜像体积有1.04G,所以需要在Windows上下载链接安装包,下载下来是一个es的镜像tar包,然后传到CentOS7的/root目录
es镜像: https://cowtransfer.com/s/1c16f55edf2341
第三步: 把在CentOS7的/root目录的kibana镜像,导入到docker
docker load -i kibana.tar
第四步: 创建并运行kibana容器,容器名称就叫kibana。在docker(也叫Docker大容器、Docker主机、宿主机),根据kibana镜像来创建kibana容器
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.1
# --name: 指定容器的名字,例如kibana
# --network es-net: 加入一个名为es-net的网络中,与elasticsearch在同一个网络中
# -e ELASTICSEARCH_HOSTS: 由于kibana和es会被我们设置在同一个网络,所以这里的kibana可以通过容器名直接访问es,es的容器名我们在上一节设置的是es
# -e ELASTICSEARCH_HOSTS: 设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch
# -p 5601:5601: 端口映射配置,向外暴露的http请求端口,用于用户访问

第五步: kibana启动一般比较慢,需要多等待一会,可以通过命令
docker logs -f kibana#查看运行日志,当查看到下面的日志,说明成功

第六步: 测试。在浏览器中输入:http://你的ip地址:5601 即可看到elasticsearch的响应结果






注意,我们在浏览器写DSL语句的时候,是带有提示功能的,非常好用
6. 安装IK分词器

IK分词器官网: https://github.com/medcl/elasticsearch-analysis-ik。注意elasticsearch、kibana、IK分词器,这三者通常是一起使用的
es在创建倒排索引时,需要对文档进行分词。在搜索时,需要对用户输入的内容进行分词。但默认的分词规则不支持中文处理,默认是只支持对英文进行分词,但是在正常业务中,我们需要处理的文档大多是中文,所以我们需要对中文进行分词,所以就需要安装IK分词器
为了直观的体现,es的分词规则不支持英文,我们可以做下面的小演示如下
#测试分词器
POST /_analyze
{
"text": "我正在学习安装IK分词器",
"analyzer": "english"
}
上图,就算分词器名称改成chinese或standard,对于中文的分词也是一字一分。解决: IK分词器。下面开始具体的安装IK分词器的操作
第一步: 我们在 '4. 安装elasticsearch' 创建elasticsearch容器时,指定了数据卷目录,其中有个数据卷指定了自定义名称为es-plugins,表示存放插件的数据卷
我们使用inspect命令把es-plugins数据卷的路径信息查询出来
docker volume inspect es-plugins
第二步: 下载ik.zip压缩包到Windows,下载后解压出来是ik文件夹
根据上面查询出来的es-plugins数据卷的路径,把ik文件夹上传到CentOS7的 /var/lib/docker/volumes/es-plugins/_data 目录
cd /var/lib/docker/volumes/es-plugins/_data
第三步: 重启elasticsearch容器,我们在 '4. 安装elasticsearch' 创建elasticsearch容器时,指定了自定义容器名称为es
# 重启elasticsearch容器
docker restart es
第四步: 查看elasticsearch容器的启动日志
docker logs -f es
第五步: 确保elasticsearch、kibana已正常运行
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器
第五步: 测试。在浏览器中输入:http://你的ip地址:5601 即可看到elasticsearch的响应结果
IK分词器包含两种模式:
- ●ik_smart:最少切分,根据语义分词,正常分词
- ●ik_max_word:最细切分,也是根据语义分词,分的词语更多,更细



7. IK分词器的词典扩展和停用
Ik分词器的分词,底层是一个字典,在字典里面会有各种各样的词语,当ik分词器需要对分词文本进行分词时,ik分词器就会拿着这个文本(乱拆成多个词或词语),一个个去字典里面匹配,如果能匹配到,证明某个词(乱拆成多个词或词语)是词,就把这个证明后的词分出来,作为一个词
第一个问题: 字典的分词效果是有限的,只能对日常生活中常见的语义相关的词,进行分词,由于字典的词汇量少,所以我们需要对字典进行扩展。
第二个问题: 字典的分词效果往往存在违禁词,我们不希望IK分词器能匹配并成功把词典里的违禁词作为分词,解决: 禁用某些敏感词条
解决:
1、要拓展或禁用ik分词器的词库,只需要修改一个分词器目录中的config目录中的IKAnalyzer.cfg.xml文件,如下
cd /var/lib/docker/volumes/es-plugins/_data/ik/config
vi IKAnalyzer.cfg.xml<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典-->
<entry key="ext_dict">ext.dic</entry>
<!--用户可以在这里配置自己的扩展停止词字典 *** 添加停用词词典-->
<entry key="ext_stopwords">stopword.dic</entry>
</properties>

2、在config目录新建myext.dic文件,写入自己想要的特定词,也就是扩展词。新建mystopword.dic文件,写入自己想要禁用的特定词,也就是不参与分词的词
cd /var/lib/docker/volumes/es-plugins/_data/ik/configtouch myext.dic
vi myext.dictouch mystopword.dic
vi mystopword.dic
3、重新启动elasticsearch、kibana
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器4、测试。在浏览器中输入:http://你的ip地址:5601 即可看到elasticsearch的响应结果
http://192.168.200.231:5601IK分词器包含两种模式:
- ●ik_smart:最少切分,根据语义分词,正常分词
- ●ik_max_word:最细切分,也是根据语义分词,分的词语更多,更细

根据上图,确实可以根据我们指定的扩展词进行分析,违禁词也确实被禁用没有被分词
实用篇-ES-DSL操作文档
1. mapping属性
mapping属性的官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/index.html

下面的表格是介绍elasticsearch中的各个概念以及含义,看的时候重点看第二、三列,第一列是为了让你更理解第二列的意思,所以在第一列拿MySQL的概念来做匹配。例如elasticsearch的Index表示索引也就是文档的集合,就相当于MySQL的Table(也就是表)
| MySQL |
Elasticsearch |
说明 |
| Table |
Index |
索引(index),就是文档的集合,类似数据库的表(table) |
| Row |
Document |
文档(Document),就是一条条的数据,类似数据库中的行(Row)。这里的文档都是JSON格式 |
| Column |
Field |
字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema |
Mapping |
Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL |
DSL |
DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |

mapping是对索引库中文档(es中的文档是json风格)的约束,常见的mapping属性包括如下
●type: 字段数据类型
○字符串(分两种): text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址等不可分词的词语)
○数值: long、integer、short、byte、double、float
○布尔: boolean
○日期: date
○对象:object
●index: 是否创建倒排索引,默认为true(也就是可参与分词搜索),改成false的话,别人就搜索不到你
●analyzer: 分词器,当字段类型是text时必须指定分词器。如果字段类型是keyword,那么不需要指定分词器
●properties: 子字段,也就是属性和子属性
2. 创建索引库
ES中通过Restful请求操作索引库、文档。请求内容用DSL语句来表示。创建索引库和mapping的DSL语法如下

PUT /索引库名称
{
"mappings": {//映射
"properties": {//字段
"字段名":{
"type": "text",
"analyzer": "ik_smart"
},
"字段名2":{
"type": "keyword",
"index": false //false表示这个字段不参与搜索,该字段不会创建为倒排索引,false不加双引号
},
"字段名3":{
"properties": {//这个就是子字段
"子字段": {
"type": "keyword"
}
}
},
// ...略
}
}
}
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器
第一步: 浏览器访问 http://你的ip地址:5601 。输入如下,注意把注释删掉
http://192.168.200.231:5601# 创建索引库,名字自定义,例如huanfqc
PUT /huanfqc
{
"mappings": {
"properties": {
"xxinfo": {
"type": "text", //文本类型,可以被分词器分词
"analyzer": "ik_smart" //必须指定分词器
},
"xxemail": {
"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的
"index": false //不参与搜索,用户不能通过搜索搜到xxemail字段
},
"name": {
"type": "object", //对象类型
"properties": { //父字段
"firstName": { //子字段
"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的
"index": true //参与搜索,用户通过可搜索到firstName字段
},
"lastName": { //子字段
"type": "keyword", //精确值类型,不可被分词器分词,本身就是最简的
"index": true //参与搜索,用户通过可搜索到lastName字段
}
}
}
}
}
}# 创建索引库,名字自定义,例如huanfqc
PUT /huanfqc
{
"mappings": {
"properties": {
"xxinfo": {
"type": "text",
"analyzer": "ik_smart"
},
"xxemail": {
"type": "keyword",
"index": false
},
"name": {
"type": "object",
"properties": {
"firstName": {
"type": "keyword",
"index": true
},
"lastName": {
"type": "keyword",
"index": true
}
}
}
}
}
}
3. 查询、修改、删除索引库
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器

1、查询索引库语法
GET /索引库名
2、往索引库添加新字段,注意: 索引库是无法被修改的,但是可以添加新字段(不能和已有的重复,否则报错)
PUT /索引库名/_mapping
{
"properties": {
"新字段名":{
"type": "integer"
}
}
}
//例如如下
PUT /huanfqc/_mapping
{
"properties": {
"age": {
"type": "integer"
}
}
}
3、删除索引库语法
DELETE /索引库名
4. 新增、查询、删除文档
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作。并且已经创建了名为huanfqc的索引库
1、新增文档的DSL语法,其实就是告诉kibana,我们要把文档添加到es的哪个索引库,如果省略文档id的话,es会默认随机生成一个,建议自己指定文档id
POST /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
"字段3": {
"子属性1": "值3",
"子属性2": "值4"
},
// ...
}#创建文档
POST /huanfqc/_doc/1
{
"xxinfo":"焕发@青春-学Java",
"email": "123@huanfqc.cn",
"name":{
"firstName":"张",
"lastName":"三"
}
}
2、查询文档。语法: GET /索引库名/_doc/文档id 。例如如下
#查询文档
GET /huanfqc/_doc/1
3、删除文档。语法: DELETE/索引库名/_doc/文档id 。例如如下
#删除文档
DELETE /huanfqc/_doc/1
5. 修改文档
具体操作: 首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作。并且已经创建了名为huanfqc的索引库、文档id为1的文档
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器
方式一: 全量修改,会删除旧文档,添加新文档。修改文档的DSL语法,如下
注意: 这种操作是直接用新值覆盖掉旧的,如果只put一个字段那么其它字段就没了,所以,你不想修改的字段也要原样写出来,不然就没了
注意: 如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
#修改文档
PUT /索引库名/_doc/文档id
{
"字段1": "值1",
"字段2": "值2",
// ... 略
}#修改文档
PUT /huanfqc/_doc/1
{
"xxinfo":"修改你了-焕发@青春-学Java",
"email": "123@huanfqc.cn",
"name":{
"firstName":"修改你了-张",
"lastName":"三",
"xxupdate":"我还加了一个"
}
}

方式二: 增量修改。修改指定字段的值
注意: 如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
#修改文档
POST /索引库名/_update/文档id
{
"doc": {
"要修改的字段名": "新的值",
}
}#修改文档
POST /huanfqc/_update/1
{
"doc": {
"firstName": "修改-法外狂徒张三"
}
}


实用篇-ES-RestClient操作文档
下面的全部内容都是连续的,请不要跳过某一小节
1. RestClient案例准备
对es概念不熟悉的话,先去看上面的 '实用篇-ES-索引库和文档',不建议基础不牢就直接往下学
ES官方提供了各种不同语言的客户端,用来操作ES。这些客户端的本质就是组装DSL语句,通过http请求来发送给ES。
官方文档地址: https://www.elastic.co/guide/en/elasticsearch/client/index.html

下面就使用java程序进行操作es,不再像上面那样使用浏览器页面进行操作es
在下面会逐步完成一个案例: 下载提供的hotel-demo.zip压缩包,解压后是hotel-demo文件夹,是一个java项目工程文件,按照条件创建索引库,索引库名为hotel,mapping属性根据数据库结构定义。还要下载一个tb_hotel.sql文件,作为数据库数据
hotel-demo.zip下载:https://cowtransfer.com/s/36ac0a9f9d9043tb_hotel.sql下载: https://cowtransfer.com/s/716f049850a849
第一步: 打开database软件,把tb_hotel.sql文件导入进你的数据库
create database if not exists elasticsearch;
use elasticsearch;


第二步: 把下载好的hotel-demo.zip压缩包解压,得到hotel-demo文件夹,在idea打开hotel-demo



第三步: 修改application.yml文件,配置正确的数据库信息

2. hotel数据结构分析
在es中,mapping要考虑的问题: 字段名、数据类型、是否参与搜索、是否分词、如果分词那么分词器是什么。
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
我们刚刚在mysql导入了tb_hotel.sql,里面有很多数据,我们需要基于这些数据结构,去分析并尝试编写对应的es的mapping映射
先看mysql中的数据类型(已有),如下
CREATE TABLE `tb_hotel` (
`id` bigint(20) NOT NULL COMMENT '酒店id',
`name` varchar(255) NOT NULL COMMENT '酒店名称;例:7天酒店',
`address` varchar(255) NOT NULL COMMENT '酒店地址;例:航头路',
`price` int(10) NOT NULL COMMENT '酒店价格;例:329',
`score` int(2) NOT NULL COMMENT '酒店评分;例:45,就是4.5分',
`brand` varchar(32) NOT NULL COMMENT '酒店品牌;例:如家',
`city` varchar(32) NOT NULL COMMENT '所在城市;例:上海',
`star_name` varchar(16) DEFAULT NULL COMMENT '酒店星级,从低到高分别是:1星到5星,1钻到5钻',
`business` varchar(255) DEFAULT NULL COMMENT '商圈;例:虹桥',
`latitude` varchar(32) NOT NULL COMMENT '纬度;例:31.2497',
`longitude` varchar(32) NOT NULL COMMENT '经度;例:120.3925',
`pic` varchar(255) DEFAULT NULL COMMENT '酒店图片;例:/img/1.jpg',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
根据mysql的数据类型等信息,编写es(没有,自己对着上面的sql写的)。注意经纬度在es里面是geo_point类型,且经纬度是写在一起的
# 酒店的mapping
PUT /hotel
{
"mappings": {
"properties": {
"id":{
"type": "keyword",
"index": true
},
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "float",
"index": true
},
"score":{
"type": "float",
"index": true
},
"brand":{
"type": "keyword",
"index": true
},
"city":{
"type": "keyword",
"index": true
},
"business":{
"type": "keyword",
"index": true
},
"xxlocation":{
"type": "geo_point",
"index": true
},
"pic":{
"type": "keyword",
"index": false
}
}
}
}
3. 初始化RestClient
操作主要是在idea的hotel-demo项目进行,hotel-demo项目(不是springcloud项目,只是springboot项目)是前面 '1. RestClient案例准备',跳过的可回去补
第一步: 在hotel-demo项目的pom.xml添加如下
<elasticsearch.version>7.12.1</elasticsearch.version>
<!--引入es的RestHighLevelClient,版本要跟你Centos7里面部署的es版本一致-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>
第二步: 在hotel-demo项目的src/test/java/cn.itcast.hotel目录新建HotelIndexTest类,写入如下
package cn.itcast.hotel;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class HotelIndexTest {
private RestHighLevelClient xxclient;
@BeforeEach
//该注解表示一开始就完成RestHighLevelClient对象的初始化
void setUp() {
this.xxclient = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.200.231:9200")
));
}
@AfterEach
//该注解表示销毁,当对象运行完之后,就销毁这个对象
void tearDown() throws IOException {
this.xxclient.close();
}
@Test
//现在才是测试代码,对象已经在上面初始化并且有销毁的步骤了,下面直接打印
void yytestInit() {
System.out.println(xxclient);
}
}
第三步: 确保下面的服务你都在Centos7里面启动了
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
第四步: 运行HotelIndexTest类yytestInit方法

4. 创建索引库

不是通过kibana的浏览器控制台,通过DSL语句来进行操作es,在es里面创建索引库
而是通过上一节初始化的RestClient对象,在Java里面去操作es,创建es的索引库。根本不需要kibana做中间者
第一步: 在src/main/java/cn.itcast.hotel目录新建constants.HotelConstants类,里面写DSL语句,如下
其中长长的字符串就是我们在前面 '2. hotel数据结构分析' 里面写的。忘了怎么写出来的,可以回去看看
package cn.itcast.hotel.constants;
public class HotelConstants {
public static final String xxMappingTemplate = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"float\",\n" +
" \"index\": true\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"float\",\n" +
" \"index\": true\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true,\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true,\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"location\":{\n" +
" \"type\": \"geo_point\",\n" +
" \"index\": true\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
第二步: 在hotel-demo项目的HotelIndexTest类,添加如下
//使用xxclient对象,向es创建索引库
@Test
void xxcreateHotelIndex() throws IOException {
//创建Request对象,自定义索引库名称为gghotel
CreateIndexRequest request = new CreateIndexRequest("gghotel");
//准备请求的参数: DSL语句
request.source(xxMappingTemplate, XContentType.JSON);//注意xxMappingTemplate是第一步定义的的静态常量,导包别导错了
//发送请求
xxclient.indices().create(request, RequestOptions.DEFAULT);
}
第三步: 确保下面的服务你都在Centos7里面启动了
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
第四步: 验证。运行HotelIndexTest类的xxcreateHotelIndex测试方法

第五步: 如何更直观地验证,es里面确实有刚刚创建的索引库(刚刚创建的索引库是叫gghotel)
那就不得不运行kibana了,这样才能打开web浏览器页面,进行查询
docker restart kibana #启动kibana容器
浏览器访问 http://你的ip地址:5601

5. 删除和判断索引库
首先保证你已经做好了 '实用篇-ES-环境搭建' ,然后开始下面的操作。不需要浏览器操作es,所以不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
1、删除索引库。在hotel-demo项目的HotelIndexTest类,添加如下。然后运行xxtestDeleteHotelIndex方法
//删除索引库
@Test
void xxtestDeleteHotelIndex() throws IOException {
//创建Request对象,指定要删除哪个索引库
DeleteIndexRequest request = new DeleteIndexRequest("gghotel");
//发送请求
xxclient.indices().delete(request, RequestOptions.DEFAULT);
}
2、判断索引库是否存在。在hotel-demo项目的HotelIndexTest类,添加如下。然后运行xxtestDeleteHotelIndex方法
//判断索引库是否存在
@Test
void xxtestExistsHotelIndex() throws IOException {
//创建Request对象,判断哪个索引库是否存在在es
GetIndexRequest request = new GetIndexRequest("gghotel");
//发送请求
boolean ffexists = xxclient.indices().exists(request, RequestOptions.DEFAULT);
//输出一下,看是否存在
System.out.println(ffexists ? "索引库已经存在" : "索引库不存在");
}

6. 新增文档
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
案例: 去数据库查询酒店数据,把查询到的结果导入到hotel索引库(上一节我们已经创建一个名为gghotel的索引库),实现酒店数据的增删改查
简单说就是先去数据查酒店数据,把结果转换成索引库所需要的格式(新增文档的DSL语法)然后写到索引库,然后在索引库对这些酒店数据进行增删改查
【必备操作】
你们拿到代码的时候,这些操作已经做好,不需要再去做,我只是写出来方便后续复习
(1)、在pojo目录里面有一个Hotel类,作用是指定根数据库交互的字段,写入了如下
package cn.itcast.hotel.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}
(2)、在pojo目录里面有一个HotelDoc类,作用是跟es的索引库交互的字段,也就是跟我们索引库里面的字段类型联调,写入了如下
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String xxlocation;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.xxlocation = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
(3)、在service新建了IHotelService接口,作用是写mybatis-plus向数据库发送请求用于查询数据库的数据
package cn.itcast.hotel.service;
import cn.itcast.hotel.pojo.Hotel;
import com.baomidou.mybatisplus.extension.service.IService;
public interface IHotelService extends IService<Hotel> {
}
(4)、在service新建了impl目录,在impl目录里面有一个HotelService类,是IHotelService接口的实现类
package cn.itcast.hotel.service.impl;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.service.IHotelService;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.springframework.stereotype.Service;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
}
【具体操作】
第一步: 在hotel-demo项目的src/test/java/cn.itcast.hotel目录新建HotelDocumentTest类,写入如下
package cn.itcast.hotel;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import static cn.itcast.hotel.constants.HotelConstants.xxMappingTemplate;
/**
* @author 35238
* @date 2023/6/9 0009 8:51
*/
@SpringBootTest
public class HotelDocumentTest {
private RestHighLevelClient xxclient;
@BeforeEach
//该注解表示一开始就完成RestHighLevelClient对象的初始化
void setUp() {
this.xxclient = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.127.180:9200")
));
}
@AfterEach
//该注解表示销毁,当对象运行完之后,就销毁这个对象
void tearDown() throws IOException {
this.xxclient.close();
}
//-----------------------------上面是初始化,下面是操作文档的测试-------------------------------------------
@Autowired
//注入写好的IHotelService接口,用于去数据库查询数据
private IHotelService xxhotelService;
@Test
//新增文档到gghotel索引库,请保证你的es里面已经存在gghotel索引库
void testAddDocument() throws IOException {
//去数据库查询数据,我们简单查询一下id为61083的数据。由于在实体类里面定义的id是Long类型,所以要加L表示该数字是Long类型
Hotel xxdataExample = xxhotelService.getById(61083L);
//把上一行数据库查询出来的字段类型转为es的索引库的文档类型,才能往索引库里面新增文档
HotelDoc xxhotelDoc = new HotelDoc(xxdataExample);
//准备Request对象,往哪个索引库添加文档,文档的id需要自定义,xxdataExample.getId().toString()表示文档id跟数据库的id一致
IndexRequest xxrequest = new IndexRequest("gghotel").id(xxdataExample.getId().toString());
//准备JSON文档.JSON.toJSONString()是com.alibaba.fastjson提供的API,用于把JSON转为String
xxrequest.source(JSON.toJSONString(xxhotelDoc),XContentType.JSON);
//发送请求
xxclient.index(xxrequest,RequestOptions.DEFAULT);
}
}
第二步: 验证。运行HotelDocumentTest类的testAddDocument方法

第三步: 如何更直观地验证,es里面的gghotel索引库里面有刚刚我们新增的文档,文档id就是数据里面的字段id
那就不得不运行kibana了,这样才能打开web浏览器页面,进行查询
docker restart kibana #启动kibana容器
浏览器访问 http://你的ip地址:5601

7. 查询文档
我们在刚刚,为了直观地验证是否成功新增文档,需要启动kibana,然后去浏览器页面进行查询,非常的麻烦,下面就来学习通过Java代码,进行查询文档
难点: 根据id查询到的文档数据类型是json,需要反序列化为java对象
第一步: 在HotelDocumentTest类,添加如下
@Test
void xxtestGetDocumentById() throws IOException {
//准备Request对象,要查询哪个索引库,要查询的文档i,我们上面指定的文档id是跟数据库字段的id一致,上面新增的那条文档的id是61083
GetRequest yyrequest = new GetRequest("gghotel", "61083");
//发送请求,获取响应结果
GetResponse yyresponse = xxclient.get(yyrequest, RequestOptions.DEFAULT);
//解析响应结果。getSourceAsString方法的作用是把得到的JSON结果转为String
String yyjson = yyresponse.getSourceAsString();
//JSON.parseObject()是com.alibaba.fastjson提供的API,作用是对上面那行的yyjson进行反序列化
//第一个参数是你要对谁进行反序列化,第二个参数是你想要的数据类型
HotelDoc yyhotelDoc = JSON.parseObject(yyjson, HotelDoc.class);
//输出一下查询结果
System.out.println(yyhotelDoc);
}
第二步: 运行HotelDocumentTest类的xxtestGetDocumentById方法

8. 修改文档
根据id修改酒店数据。修改es的索引库的文档的数据,有两种方式,前面在学kibana操作文档的时候学过,可前去 '实用篇-ES-索引库和文档' 进行复习
1、全量修改,会删除旧文档,添加新文档。注意: 这种操作是直接用新值覆盖掉旧的,如果只put一个字段那么其它字段就没了,所以,你不想修改的字段也要原样写出来,不然就没了。如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
2、增量修改(我们学习这种)。修改指定字段的值。如果你写的文档id或字段不存在的话,本来是修改操作,结果就变成新增操作
首先保证你已经做好了 '实用篇-ES-环境搭建' ,以及上面的五小节,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
第一步: 在HotelDocumentTest类,添加如下
@Test
void xxtestUpdateDocument() throws IOException {
//准备Request对象,要修改哪个索引库,要修改的文档id
UpdateRequest zzrequest = new UpdateRequest("gghotel", "61083");
//准备请求参数,要修改哪些字段,修改成什么
zzrequest.doc(
"name","我修改了你3个文档字段",
"price","999",
"city","北京"
);
//发送请求,获取响应结果
xxclient.update(zzrequest,RequestOptions.DEFAULT);
}
第二步: 先查一下原来的id为61083的文档(es中的文档就相当于mysql的一行)的数据。运行HotelDocumentTest类的xxtestGetDocumentById方法

第三步: 运行HotelDocumentTest类的xxtestUpdateDocument方法,作用是修改数据,也就是我们第一步写的代码

第四步: 在去查一下文档的数据,验证第三步是否修改成功。运行HotelDocumentTest类的xxtestGetDocumentById方法

9. 删除文档
首先保证你已经做好了 '实用篇-ES-环境搭建' ,以及上面的五小节,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器第一步: 在HotelDocumentTest类,添加如下
@Test
void wwtestDeleteDocument() throws IOException {
//准备Request对象,要删除哪个索引库,要删除的文档id
DeleteRequest wwrequest = new DeleteRequest("gghotel", "61083");
//发送请求
xxclient.delete(wwrequest,RequestOptions.DEFAULT);
}
第二步: 先查一下原来的id为61083的文档(es中的文档就相当于mysql的一行)能不能查询到。运行HotelDocumentTest类的xxtestGetDocumentById方法

第三步: 删除id为61083的文档(相当于删除mysql中id为某个数的那一行)。运行HotelDocumentTest类的wwtestDeleteDocument方法

第四步: 验证。再次执行第二步,也就是运行HotelDocumentTest类的xxtestGetDocumentById方法

10. 批量导入文档
建议去前面的 '6. 新增文档' 复习一下,在索引库里面新增一条文档,是怎么实现的
在上面的6、7、8、9节中,我们一直都是操作一条id为61083的文档(相当于数据库表的某一行)。我们如何把mysql的更多数据导入进es的索引库(相当于mysql的表)呢,下面就来学习批量把文档导入进索引库
思路:
1、利用mybatis-plus把MySQL中的酒店数据查询出来
2、将查询到的酒店数据转换为文档类型的数据
3、利用RestClient中bulk批处理方法,实现批量新增文档
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
第一步: 在HotelDocumentTest类,添加如下
@Test
void testBulkRequest() throws IOException {
//向数据库批量查询酒店数据,list方法表示查询数据库的所有数据
List<Hotel> kkhotels = xxhotelService.list();
//创建Request
BulkRequest vvrequest = new BulkRequest();
//准备参数,实际上就是添加多个新增的Request
for (Hotel kkhotel : kkhotels) {
//把遍历拿到的每个kkhotels转换为文档类型的数据
HotelDoc ffhotelDoc = new HotelDoc(kkhotel);//HotelDoc是我们写的一个实体类
//往哪个索引库批量新增文档、新增后的文档id是什么,文档类型是JSON
vvrequest.add(new IndexRequest("gghotel")
.id(ffhotelDoc.getId().toString())
//JSON.parseObject()是com.alibaba.fastjson提供的API,作用是对ffhotelDoc进行反序列化准换为json类型
.source(JSON.toJSONString(ffhotelDoc),XContentType.JSON));
}
//发送请求
xxclient.bulk(vvrequest,RequestOptions.DEFAULT);
}
第二步: 运行HotelDocumentTest类的testBulkRequest方法

\
第三步: 如何更直观地验证,es里面的gghotel索引库里面有刚刚我们新增的文档。那就不得不运行kibana了,这样才能打开web浏览器页面,进行查询
docker restart kibana #启动kibana容器浏览器访问 http://你的ip地址:5601
输入如下DSL语句,表示查询某个索引库的所有文档
GET /gghotel/_search
上面我们导入了很多文档(相当于数据库的行,很多行),下面我们将着重学习使用DSL对这些文档数据,进行查询
实用篇-ES-DSL查询文档
官方文档: https://elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html#query-dsl。DSL是用来查询文档的
Elasticsearch提供了基于JSON的DSL来定义查询,简单说就是用json来描述查询条件,然后发送给es服务,最后es服务基于查询条件,把结果返回给我们
常见的查询类型包括如下:
1、查询所有: 查询出所有数据,一般在测试的时候使用
match_all
2、全文检索查询: 利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配
match_querymulti_match_query
3、精确查询: 根据精确的词条值去查找数据,一般是查找keyword、数值、日期、boolean等类型的字段。这些字段是不需要分词的,但是依旧会建立倒排索引,把字段的整体内容作为一个词条,并存入倒排索引。在查找的时候,也就不需要分词,直接把搜索的内容去跟倒排索引匹配即可
ids,表示根据id,进行精确匹配range,表示根据数值范围,进行精确匹配term,表示根据数据的值,进行精确匹配
4、地理查询: 根据经纬度查询
geo_distancegeo_bounding_box
5、复合查询: 复合查询可将上述各种查询条件组合一起,合并查询条件
bool,利用逻辑运算把其它查询条件组合起来function_score,用于控制相关度算分,算分会影响性能下面会一个个学
1. DSL基本语法
查询的基本语法

#查询所有
GET /hotel/_search
{
"query":{
"match_all": {
}
}
}
【具体操作】
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
浏览器访问 http://你的ip地址:5601
输入如下

存在一个问题,我们明明查询的是所有文档,查询结果也显示查询出所有的文档了,为什么上图右侧,鼠标往下拉,最多才只有10条文档数据呢
原因: 受默认的分页条件限制,后面学习的时候,会进行解决
2. 全文检索查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
全文检索查询,分为下面两种,会对用户输入内容进行分词之后,再进行匹配。也就是利用分词器对用户输入内容进行分词,然后去倒排索引库中匹配。
【第一种全文检索查询】
GET /索引库名/_search
{
"query": {
"match": {
"字段名": "TEXT"
}
}
}
match查询(也就是match_query查询): 全文检索查询的一种,会对用户输入的内容进行分词,然后去倒排索引库检索
具体操作如下,为了让大家知道gghotel索引库有哪些字段,我把当初建立gghotel索引库的类先放出来
注意: 我要解释一下,上面有个字段叫xxALL,那个字段是当时自定义的,不清楚的话可回去看 '实用篇-ES-RestClient操作' 的 '2. hotel数据结构分析'。
xxALL的作用如下图,相当于一个大的字段,里面存放了几个小字段,优点是我们可以在这个大的字段里面搜索到多个小字段的信息

然后,我们就正式开始全文检索查询,输入如下。注意xxALL换成其它字段也没事,例如换成name字段。正常来说,我们检索name字段,就只在那么字段检索匹配的分词文档,但是在XXALL字段里面检索时,也会检索到name、brand、business字段,原因如上面那个图的copy_to属性
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查询某个索引库的所有文档

【第二种全文检索查询】
GET /索引库名/_search
{
"query": {
"multi_match": {
"query": "TEXT",
"字段名": ["FIELD1", " FIELD12"]
}
}
}
multi_match(也就是multi_match_query查询): 与match查询类似,只不过允许同时查询多个字段
例如,输入如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查询查询business、brand、name字段中包含'如家'的文档,满足一个字段即可

3. 精确查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。精确查询常见的有两种:
term: 根据词条的精确值查询,强调精确匹配range: 根据值的范围查询,例如金额、时间
【第一种精确查询 term】
具体操作如下
GET /索引库名/_search
{
"query": {
"term": {
"字段名": {
"value": "VALUE"
}
}
}
}
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查询city字段为 '上海' 的文档,必须是 '上海' 才能被匹配,不对'上海'进行分词,也就是不会拆成'上'和'海'

【第一种精确查询 range】
具体操作如下
GET /索引库名/_search
{
"query": {
"range": {
"字段名": {
"gte": 10,
"lte": 20
}
}
}
}
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示查找price字段满足200~300数值的文档,注意字段类型不能是binary,也就是price字段的类型不能是binary
gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
# 第一种精确查询 term。
GET /gghotel/_search
{
"query":{
"term": {
"city": {
"value": "上海"
}
}
}
}
4. 地理查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
根据经纬度查询。常见的使用场景包括: 查询附近酒店、附近出租车、搜索附近的人。使用方式有很多种,介绍如下

geo_bounding_box: 查询geo_point值落在某个矩形范围的所有文档,用两个点来围成的矩形范围geo_distance: 查询到指定中心点,且小于某个距离值的所有文档,圆心到圆边的范围
【第一种地理查询 geo_bounding_box 不演示这种,不常用】
GET /索引库名/_search
{
"query": {
"geo_bounding_box": {
"字段名": {
"top_left": {
"lat": 31.1,
"lon": 121.5
},
"bottom_right": {
"lat": 30.9,
"lon": 121.7
}
}
}
}
}
【第一种地理查询 geo_distance 下面演示这种】
GET /索引库名/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"字段名": "31.21,121.5"
}
}
}
具体操作如下,但是,为了让大家知道gghotel索引库有哪些字段,我把当初建立gghotel索引库的类先放出来
上面的xxlocation字段类型必须是geo_point,否则该字段不能用于地理查询
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句。表示查找xxlocation字段在(31.25±15km,121.5±15km)范围内的文档

5. 相关性算分
上面学的全文检索查询、精确查询、地理查询,这三种查询在es当中都称为简单查询,下面我们将学习复合查询。复合查询可以其它简单查询组合起来,实现更复杂的搜索逻辑,其中就有 '算分函数查询' 如下
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
算分函数查询(function score): 可以控制文档相关性算分、控制文档排名。例如搜索'外滩' 和 '如家' 词条时,某个文档要是都能匹配这两个词条,那么在所有被搜索出来的文档当中,这个文档的位置就最靠前,简单说就是越匹配就排名越靠前


GET /索引库名/_search
{
"query": {
"match": {
"字段名": {
"query": "词条"
}
}
}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示在name字段,哪个文档的匹配度高,排名就靠前
GET /gghotel/_search
{
"query": {
"match": {
"name": {
"query": "7天连锁酒店"
}
}
}
}
6. 函数算分查询
这是第一种复合查询
上面只是简单演了相关性打分中的函数算分查询,文档与搜索关键字的相关度越高,打分就越高,排名就越靠前。不过,有的时候,我们希望人为地去控制控制文档的排名,例如某些文档我们就希望排名靠前一点,算分高一点,此时就需要使用函数算分查询,下面就来学习 '函数算分查询'
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
使用 ’函数算分查询(function score query)’,可以在原始的相关性算分的基础上加以修改,得到一个想要的算分,从而去影响文档的排名,语法如下
GET /索引库名/_search
{
"query": {
"function_score": {
"query": { "match": {"字段": "词条"} },
"functions": [
{
"filter": {"term": {"指定字段": "值"}},
"算分函数": 函数结果
}
],
"boost_mode": "加权模式"
}
}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示在 '如家' 这个品牌中,字段为'北京'的酒店排名靠前一些
GET /gghotel/_search
{
"query": {
"function_score": {
"query": {"match": {
"brand": "如家"
}},
"functions": [
{
"filter": {
"term": {
"city": "北京"
}
},
"weight": 2
}
],
"boost_mode": "sum"
}
}
}
7. 布尔查询
这是第二种复合查询
布尔查询不会去修改算分,而是把多个查询语句组合成一起,形成新查询,这些被组合的查询语句,被称为子查询。子查询的组合方式有如下四种
1、must:必须匹配每个子查询,类似"与"
2、should:选择性匹配子查询,类似"或"
3、must_not:必须不匹配,不参与算分,类似"非"
4、filter:必须匹配,不参与算分

systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
GET /索引库名/_search
{
"query": {
"bool": {
"must": [
{"term": {"字段名": "字段值" }}
],
"should": [
{"term": {"字段名": "字段值" }},
{"term": {"字段名": "字段值" }}
],
"must_not": [
{ "range": { "字段名": { "lte": 最小字段值 } }}
],
"filter": [
{ "range": {"字段名": { "gte": 最大字段值 } }}
]
}
}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示搜索名字包含'如家',价格不高于400,在坐标31.21,121.5周围10km范围内的文档
must表示匹配条件(注意写在must里面就会参与算分,也就是查询出来的score值会更高),must_not表示取反,filter表示过滤
GET /gghotel/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "如家"
}
}
],
"must_not": [
{
"range": {
"price": {
"gt": 400
}
}
}
],
"filter": [
{
"geo_distance": {
"distance": "10km",
"xxlocation": {
"lat": 31.21,
"lon": 121.5
}
}
}
]
}
}
}
8. 搜索结果处理-排序
elasticsearch(称为es)支持对搜索的结果,进行排序,默认是根据 '相关度' 算分,也就是score值,根据score值进行排序。
可以排序的字段类型有: keyword类型、数值类型、地理坐标类型、日期类型
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #由于DSL语句是需要kibana服务,然后在浏览器进行,所以这里要开启kibana容器
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
sort里面可以指定多个排序字段,用花括号隔开。排序方式: ASC(升序)、DESC(降序)
GET /索引库名/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"需要排序的字段名": "排序方式"
}
]
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
【案例一】
第二步: 输入如下DSL语句,表示对所有的文档,根据评分(score)进行降序排序,如果评分相同就根据价格(price)升序排序
GET /gghotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": "desc"
},
{
"price": "asc"
}
]
}
上图的_score算分为null,是因为我们如果做了排序,那么打分就没有意义了,所以es就会放弃打分不再做相关性算分,提高效率
【案例二】
获取国内任意位置的经纬度的网站: 获取鼠标点击经纬度-地图属性-示例中心-JS API 2.0 示例 | 高德地图API
longitude 经度 latitude 纬度 (经度,纬度): 这是我们描述经纬度的写法,先经度再纬度,但是在下面写的时候
第三步: 输入如下DSL语句,表示找到(121.66053,28.28811)周围的文档,并按照距离进行升序排序
下面两种写法都是一样的,注意第二种写法前面写的是纬度,后面写的是经度
第一种写法
GET /gghotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"xxlocation": {
"lat": 28.28811,
"lon": 121.66053
},
"order": "asc"
}
}
]
}
第二种写法
GET /gghotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance": {
"xxlocation": "28.28811,121.66053",
"order": "asc"
}
}
]
}
上图右侧的sort表示距离 '28.28811,121.66053' 有多少公里,例如281547.94km。
上图的_score算分为null,是因为我们如果做了排序,那么打分就没有意义了,所以es就会放弃打分不再做相关性算分,提高效率
9. 搜索结果处理-分页
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
elasticsearch(称为es)默认情况下只返回前10 条数据。而如果要查询更多数据就需要修改分页参数,分页参数包括from和size,语法如下
GET /索引库名/_search
{
"query": {
"要查询的字段": {}
},
"from": 要查第几页, // 分页开始的位置,默认为0
"size": 每页显示多少条文档, // 期望获取的文档总数
"sort": [ //表示排序
{"price": "排序方式"}
]
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示对所有的文档,根据价格(price)进行升序排序,每次分页显示20条数据,看的是第六页
size默认是10,表示一页显示多少条文档。from默认是0,表示你要看的是第一页
GET /gghotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "asc"
}
}
],
"from": 0,
"size": 20
}
上面是基础的分页用法,下面来详细了解es的分页。es的底层使用的是倒排索引,是不利于做分页的,es采用的是逻辑上的分页,就会导致当是分布式的时候,就会产生下面的问题,因此es限制结果集最多为10000
ES是分布式的,所以会面临深度分页的问题。例如按price排序后,获取from=990,size=10的数据,如下图

深度分页查询的演示,输入如下DSL语句,表示
GET /gghotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"price": {
"order": "asc"
}
}
],
"from": 9991,
"size": 10
}

百度在这方面,最多能查76页,每页显示十条。京东在这方面,最多能查第100页,所以深度分页我们不需要担心,10000的限制足够了。但是,如果说一定要去解决深度分页问题的话,ES提供了两种解决方案(两种分页方式),如下
官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/paginate-search-results.html
1、search after: 分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。缺点: 只能向后翻页,不能向前翻页
场景: 没有随机翻页需求的搜索,例如手机向下滚动翻页。虽然没有查询上限,但是size不能超过10000
2、scroll: 原理将排序数据形成快照,保存在内存。官方已经不推荐使用。缺点: 由于是快照,所以不能查到实时数据,由于是保存在内存,所以消耗内存
场景: 海量数据的获取和迁移。从es7.1开始不推荐
我们上面用的分页方式是 'from+size' 。优点: 支持随机翻页。缺点: 存在深度分页问题。场景: 百度、京东、谷歌、淘宝
10. 搜索结果处理-高亮
高亮: 就是在搜索结果中把搜索关键字突出显示。高亮显示的原理如下
1、将搜索结果中的关键字用标签标记出来
2、在页面中给标签添加css样式

首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,导入了批量文档。然后开始下面的操作
语法
GET /索引库名/_search
{
"query": {
"match": { //match表示带关键字的查询
"字段": "TEXT"
}
},
"highlight": {
"fields": {
"字段名": {
"require_field_match": "false",//默认是true,表示 '字段' 要和 '字段名' 要一致。如果我们写的是不一致的话,就需要修改为false
"pre_tags": "<em>", // 用来标记高亮字段的前置标签,es会帮我们把标签加在关键字上。默认是<em>
"post_tags": "</em>" // 用来标记高亮字段的后置标签,es会帮我们把标签加在关键字上。默认是</em>
}
}
}
}
具体操作如下
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,表示
GET /gghotel/_search
{
"query": {
"match": {
"xxALL": "北京"
}
},
"highlight": {
"fields": {
"name": {
"require_field_match": "false",
"pre_tags": "<em>",
"post_tags": "</em>"
}
}
}
}


11. 搜索结果处理-总结
搜索结果处理的整体语法
GET /索引库名/_search
{
"query": {
"match": {
"字段名": "如家"
}
},
"from": 0, // 分页开始的位置
"size": 20, // 期望获取的文档总数
"sort": [
{ "price": "asc" }, // 普通排序
{
"_geo_distance" : { // 距离排序
"location" : "31.040699,121.618075",
"order" : "asc",
"unit" : "km"
}
}
],
"highlight": {
"fields": { // 高亮字段
"字段名": {
"pre_tags": "<em>", // 用来标记高亮字段的前置标签
"post_tags": "</em>" // 用来标记高亮字段的后置标签
}
}
}
}实用篇-ES-RestClient查询文档
1. 快速入门
上面的查询文档都是依赖kibana,在浏览器页面使用DSL语句去查询es,如何用java去查询es里面的文档(数据)呢

我们通过match_all查询来演示基本的API,注意下面演示的是 'match_all查询,也叫基础查询'
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
在进行下面的操作之前,确保你已经看了前面 '实用篇-ES-RestClient操作文档' 学的 '1. RestClient案例准备',然后在进行下面的操作
第一步: 在src/test/java/cn.itcast.hotel目录新建HotelSearchTest类,写入如下
package cn.itcast.hotel;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class HotelSearchTest {
private RestHighLevelClient xxclient;
@BeforeEach
//该注解表示一开始就完成RestHighLevelClient对象的初始化
void setUp() {
this.xxclient = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.127.180:9200")
));
}
@AfterEach
//该注解表示销毁,当对象运行完之后,就销毁这个对象
void tearDown() throws IOException {
this.xxclient.close();
}
//-----------------------------上面是初始化,下面是查询文档-快速入门的测试-------------------------------------------
@Test
void xxtestMatchAll() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型
xxrequest.source().query(QueryBuilders.matchAllQuery());
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//在控制台输出结果
System.out.println(xxresponse);
}
}
上面java代码以及对应的DSL语句如下图

第二步: 把控制台里面我们需要的数据解析出来。返回的数据很多,我们主要是解析hits里面的数据就行了
把HotelSearchTest类修改为如下,主要的修改是sout之前做了一次解析,拿到我们想要的数据
package cn.itcast.hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
public class HotelSearchTest {
private RestHighLevelClient xxclient;
@BeforeEach
//该注解表示一开始就完成RestHighLevelClient对象的初始化
void setUp() {
this.xxclient = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.127.180:9200")
));
}
@AfterEach
//该注解表示销毁,当对象运行完之后,就销毁这个对象
void tearDown() throws IOException {
this.xxclient.close();
}
//-----------------------------上面是初始化,下面是查询文档-快速入门的测试-------------------------------------------
@Test
void xxtestMatchAll() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型
xxrequest.source().query(QueryBuilders.matchAllQuery());
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
}
上面java代码以及对应的DSL语句如下图

2. match的三种查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器

全文检索的 match 和 multi_match 查询与 match_all 的API基本一致。差别是查询条件,也就是query的部分,如下图

我们刚刚在第一节演示的是 match_all(也叫基本查询) 查询,下面将演示 match(也叫单字段查询) 和 multi_match(也叫多字段查询) 查询
【matc_all查询,也叫基本查询,我们在 '快速入门' 已经演示过】
在HotelSearchTest类添加如下(已做可跳过)
@Test
void xxtestMatchAll() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型
xxrequest.source().query(QueryBuilders.matchAllQuery());
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
【match 查询,也叫单字段查询】
在HotelSearchTest类添加如下
@Test
void xxtestMatch() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型
xxrequest.source().query(QueryBuilders.matchQuery("name","如家"));
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
【multi_match 查询,也叫多字段查询】
在HotelSearchTest类添加如下
@Test
void xxtestMutilMatch() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型
xxrequest.source().query(QueryBuilders.multiMatchQuery("如家","name","business"));
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
3. 解析代码的抽取
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
我们发现对于 match、multi_match、match_all 查询,的解析部分的代码都是相同的,所以我们可以对解析部分的代码进行抽取(ctrl+alt+m),如下
//这个方法就是我们抽取出来的,负责解析的
private void handleResponse(SearchResponse xxresponse) {
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
4. term、range精确查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。精确查询常见的有两种:
term: 根据词条的精确值查询,强调精确匹配range: 根据值的范围查询,例如金额、时间
java代码和DSL语句的对应关系如下图。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于

【term查询】在HotelSearchTest类添加如下
@Test
void xxtestTerm() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型
xxrequest.source().query(QueryBuilders.termQuery("city","上海"));
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
【range查询】在HotelSearchTest类添加如下
@Test
void xxtestTerm() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//准备DSL语句,source方法可以调用很多API。QueryBuilders是RestClient提供的工具,可以调用很多查询类型
xxrequest.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(150));
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
5. bool复合查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
java代码和DSL语句的对应关系如下图

【bool查询】在HotelSearchTest类添加如下
@Test
void xxtestBool() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//创建布尔查询
BoolQueryBuilder xxboolQuery = QueryBuilders.boolQuery();
//添加must条件
xxboolQuery.must(QueryBuilders.termQuery("city","上海"));
//添加filter条件
xxboolQuery.filter(QueryBuilders.rangeQuery("price").lte(200));
//把上面的布尔对象传进来,就可以生效了
xxrequest.source().query(xxboolQuery);
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
6. geo_distance地理查询
首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
【geo_distance查询】在HotelSearchTest类添加如下
@Test
void xxtestGeoDistance() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//创建一个地理位置查询构造器,指定了要查询字段的是xxlocation
GeoDistanceQueryBuilder xxgeoQuery = QueryBuilders.geoDistanceQuery("xxlocation");
xxgeoQuery.point(31.25, 121.5);//设置查询的中心点坐标,这里的经度和纬度分别为 31.25 和 121.5
xxgeoQuery.distance(5, DistanceUnit.KILOMETERS);//设置查询的半径距离和单位,这里的 5 即表示 5 公里
// 创建一个查询构造器
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 将查询条件添加到查询构造器对象
searchSourceBuilder.query(xxgeoQuery);
// 将查询构造器的对象,添加到查询请求对象xxrequest中,就可以生效了
xxrequest.source(searchSourceBuilder);
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
总结: 要构建查询条件,只要记住一个QueryBuilders类即可
7. 排序和分页
上面是各种查询的学习,当我们把文档查询出来的时候,接下来就是对文档的处理,也就是你要把查询结果怎么展示出来。API以及对应的DSL语句如下图

首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
【排序、分页】在HotelSearchTest类添加如下
@Test
void xxtestPageAndSort() throws IOException {
//页面、每页大小。如果你要翻第二页,就把下面的xxpage改成2
int xxpage = 1, xxsize = 5;
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//查询全部
xxrequest.source().query(QueryBuilders.matchAllQuery());
//sort排序,asc升序,desc降序
xxrequest.source().sort("price", SortOrder.ASC);
//from、size分页。例如查第一页,每页显示5条文档(数据)。from表示当前页,我们使用公式动态设定
xxrequest.source().from((xxpage-1)*xxsize).size(5);
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
8. 高亮显示
高亮API包括请求DSL构建和结果解析两部分,API和对应的DSL语句如下图,下图只是构建,再下面还有解析,高亮必须由构建+解析才能实现

解析,如下图

首先保证你已经做好了 '实用篇-ES-环境搭建' ,创建了名为gghotel的索引库,然后开始下面的操作。如果需要浏览器操作es,那就不需要启动kibana容器
【高亮显示-】在HotelSearchTest类添加如下
@Test
void xxtestHightlight() throws IOException {
//准备Request对象,要查询哪个索引库,
SearchRequest xxrequest = new SearchRequest("gghotel");
//【构建】
//查询name字段的文档
xxrequest.source().query(QueryBuilders.matchQuery("name","上海"));
//对查询出来的文档,的特定字段进行高亮显示
xxrequest.source().highlighter(new HighlightBuilder().field("name").requireFieldMatch(true).preTags("<em>").postTags("</em>"));
//发送请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析获取到杂乱JSON数据
SearchHits xxsearchHits = xxresponse.getHits();
//获取总条数
long xxtotal = xxsearchHits.getTotalHits().value;
System.out.println("共搜索到"+xxtotal+"条文档(数据)");
//获取hits数组
SearchHit[] xxhits = xxsearchHits.getHits();
//遍历数组,把hits数组的每个source取出来
for (SearchHit xxhit : xxhits) {
String xxjson = xxhit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc xxhotelDoc = JSON.parseObject(xxjson, HotelDoc.class);
//【解析】获取高亮结果
Map<String, HighlightField> xxhighlightFields = xxhit.getHighlightFields();
//使用CollectionUtils工具类,进行判空,避免空指针
if (!CollectionUtils.isEmpty(xxhighlightFields)){
//根据字段名获取高亮结果
HighlightField xxhighlightField = xxhighlightFields.get("name");
//判断name不为空
if (xxhighlightField != null) {
//获取高亮值
String xxname = xxhighlightField.getFragments()[0].string();
//覆盖非高亮结果
xxhotelDoc.setName(xxname);
}
}
//最终输出
System.out.println("每个HotelDoc对象 = " + xxhotelDoc);
}
}
实用篇-ES-黑马旅游案例
这个案例我做了两遍才做出来了,第一遍排了一上午的错,所以很有必要进行环境准备,下面我将带领你对一下我的环境,全网最详细的自创笔记
1. 环境准备-docker
企业部署一般都是采用Linux操作系统,而其中又数CentOS发行版占比最多,因此我们接下来会在CentOS下安装Docker
CentOS7镜像快速下载,我正在用的
https://cowtransfer.com/s/56423adc78374f远程软件FinalShell快速下载,我正在用的
https://cowtransfer.com/s/b4c8fcb5c15244
idea+jdk下载
https://cowtransfer.com/s/7dcb0c66154d45
mysql下载
https://cowtransfer.com/s/567413055c9a4f
第一步: 在VMware虚拟机安装CentOS7系统,安装完成之后,使用finalshell远程软件进行远程连接,然后安装yum工具,执行如下
yum install -y yum-utils \
device-mapper-persistent-data \
lvm2 --skip-broken
第二步: 更新本地镜像源,执行如下
# 设置docker镜像源
yum-config-manager \
--add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sed -i 's/download.docker.com/mirrors.aliyun.com\/docker-ce/g' /etc/yum.repos.d/docker-ce.repo
yum makecache fast
第三步: 执行如下安装docker,稍等片刻,docker即可安装成功。docker-ce为社区免费版本
yum install -y docker-ce
第四步: 由于Docker应用需要用到各种端口,逐一去修改防火墙设置,会非常麻烦,所以学习期间直接关闭防火墙即可
# 关闭
systemctl stop firewalld
# 禁止开机启动防火墙
systemctl disable firewalld
第五步: 通过命令启动docker
systemctl start docker # 启动docker服务
systemctl stop docker # 停止docker服务
systemctl restart docker # 重启docker服务
systemctl status docker # 查看docker的启动状态
docker -v # 查看docker版本
第六步: 配置docker镜像仓库,设置为国内的镜像仓库,以后在docker里面下载东西的时候速度会更快。分别执行如下命令
sudo mkdir -p /etc/docker # 创建文件夹sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://93we6x1g.mirror.aliyuncs.com"]
}
EOF # 在刚刚创建的文件夹里面新建daemon.json文件,并写入花括号里面的数据sudo systemctl daemon-reload # 重新加载daemon.json文件sudo systemctl restart docker # 重启docker
2. 环境准备-elasticsearch
第一步: 创建网络
systemctl start docker # 启动docker服务
docker network create es-net #创建一个网络,名字是es-net
第二步: 加载es镜像。采用elasticsearch的7.12.1版本的镜像,这个镜像体积有800多MB,所以需要在Windows上下载链接安装包,下载下来是一个es的镜像tar包,然后传到CentOS7的/root目录
es.tar下载: https://cowtransfer.com/s/c84ac851b9ba44kibana.tar下载: https://cowtransfer.com/s/a76d8339d7ba4d
第三步: 把在CentOS7的/root目录的es镜像,导入到docker
docker load -i es.tar

第四步: 创建并运行es容器,容器名称就叫es。在docker(也叫Docker大容器、Docker主机、宿主机),根据es镜像来创建es容器
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
然后,在浏览器中输入:http://你的ip地址:9200 即可看到elasticsearch的响应结果

3. 环境准备-mysql
第一步: 打开database软件,把tb_hotel.sql文件导入进你的数据库
tb_hotel.sql下载: https://cowtransfer.com/s/68c94a66d17248create database if not exists elasticsearch;
use elasticsearch;


4. 环境准备-项目导入
第一步: 把下载好的hotel-demo.zip压缩包解压,得到hotel-demo文件夹,在idea打开hotel-demo
hotel-demo.zip下载:https://cowtransfer.com/s/36ac0a9f9d9043

第二步: 修改application.yml文件,配置正确的数据库信息

第三步: 把pom.xml修改为如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.3.10.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>cn.itcast.demo</groupId>
<artifactId>hotel-demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>hotel-demo</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
<elasticsearch.version>7.12.1</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--引入es的RestHighLevelClient,版本要跟你Centos7里面部署的es版本一致-->
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.12.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
<!--FastJson-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.71</version>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-lang3</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>5. 环境准备-同步数据
把mysql的数据导入进es,我们需要使用前面学的es提供的RestClient,就可以通过java代码创建索引库,并往这个索引库导入文档(文档就是数据的意思)
第一步: 在hotel-demo项目的 src/test/java/cn.itcast.hotel 目录新建 HotelIndexTest 类,用于在es中创建名为hotel的索引库,写入如下
写完就运行xxcreateHotelIndex方法,把索引库创建出来
package cn.itcast.hotel;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.io.IOException;
import static cn.itcast.hotel.constants.HotelConstants.xxMappingTemplate;
public class HotelIndexTest {
private RestHighLevelClient xxclient;
@BeforeEach
//该注解表示一开始就完成RestHighLevelClient对象的初始化
void setUp() {
this.xxclient = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.127.180:9200")
));
}
@AfterEach
//该注解表示销毁,当对象运行完之后,就销毁这个对象
void tearDown() throws IOException {
this.xxclient.close();
}
//删除索引库(如果下面创建hotel索引库的时候,出现已存在,那么就执行这里的删除操作,把hotel索引库删掉,再创建)
@Test
void xxtestDeleteHotelIndex() throws IOException {
//创建Request对象,指定要删除哪个索引库
DeleteIndexRequest gghotel = new DeleteIndexRequest("hotel");
//发送请求
xxclient.indices().delete(gghotel, RequestOptions.DEFAULT);
}
//使用xxclient对象,向es创建索引库
@Test
void xxcreateHotelIndex() throws IOException {
//创建Request对象,自定义索引库名称为hotel
CreateIndexRequest gghotel = new CreateIndexRequest("hotel");
//准备请求的参数: DSL语句
gghotel.source(xxMappingTemplate, XContentType.JSON);
//发送请求
xxclient.indices().create(gghotel, RequestOptions.DEFAULT);
}
}
第二步: 在hotel-demo项目的 src/main/java/cn.itcast.hotel 目录新建 constants.HotelConstants类,为es准备数据,写入如下
package cn.itcast.hotel.constants;
public class HotelConstants {
public static final String xxMappingTemplate = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\",\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"address\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\",\n" +
" \"index\": true\n" +
" },\n" +
" \"score\":{\n" +
" \"type\": \"integer\",\n" +
" \"index\": true\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true,\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"city\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true\n" +
" },\n" +
" \"business\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true,\n" +
" \"copy_to\": \"all\"\n" +
" },\n" +
" \"location\":{\n" +
" \"type\": \"geo_point\",\n" +
" \"index\": true\n" +
" },\n" +
" \"starName\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": true\n" +
" },\n" +
" \"pic\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"all\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
}
第三步(这一步好像项目本身做好了,已做可跳过): 在hotel-demo项目的 src/main/java/cn.itcast.hotel/pojo 目录新建Hotel、HotelDoc类,写入如下
package cn.itcast.hotel.pojo;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
@TableName("tb_hotel")
public class Hotel {
@TableId(type = IdType.INPUT)
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String longitude;
private String latitude;
private String pic;
}package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
第四步: 在hotel-demo项目的 src/test/java/cn.itcast.hotel 目录新建 HotelDocumentTest类,用于把mysql的数据批量导入进es,写入如下
写完就运行testBulkRequest方法,把数据往索引库里面批量导入
package cn.itcast.hotel;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import org.apache.http.HttpHost;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.xcontent.XContentType;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.List;
@SpringBootTest
public class HotelDocumentTest {
private RestHighLevelClient xxclient;
@BeforeEach
//该注解表示一开始就完成RestHighLevelClient对象的初始化
void setUp() {
this.xxclient = new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.127.180:9200")
));
}
@AfterEach
//该注解表示销毁,当对象运行完之后,就销毁这个对象
void tearDown() throws IOException {
this.xxclient.close();
}
@Autowired
//注入写好的IHotelService接口,用于去数据库查询数据
private IHotelService xxhotelService;
@Test
void testBulkRequest() throws IOException {
//向数据库批量查询酒店数据,list方法表示查询数据库的所有数据
List<Hotel> kkhotels = xxhotelService.list();
//创建Request
BulkRequest vvrequest = new BulkRequest();
//准备参数,实际上就是添加多个新增的Request
for (Hotel kkhotel : kkhotels) {
//把遍历拿到的每个kkhotels转换为文档类型的数据
HotelDoc ffhotelDoc = new HotelDoc(kkhotel);//HotelDoc是我们写的一个实体类
//往哪个索引库批量新增文档、新增后的文档id是什么,文档类型是JSON
vvrequest.add(new IndexRequest("hotel")
.id(ffhotelDoc.getId().toString())
//JSON.parseObject()是com.alibaba.fastjson提供的API,作用是对ffhotelDoc进行反序列化准换为json类型
.source(JSON.toJSONString(ffhotelDoc),XContentType.JSON));
}
//发送请求
xxclient.bulk(vvrequest,RequestOptions.DEFAULT);
}
}6. 搜索、分页
【请保证网络正常,否则页面的静态资源部分加载不了】
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
#docker restart kibana #启动kibana容器
实现步骤如下
一、根据前端的请求,定义实体类来接收前端的请求

(1)在pojo目录新建RequestParams类,写入如下
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
//搜索关键字
private String key;
//当前页码
private Integer page;
//每页大小
private Integer size;
//将来的排序字段
private String sortBy;
}二、定义controller接口,接收页面请求,调用IHotelService的search方法

(1)在pojo目录新建PageResult类,写入如下
package cn.itcast.hotel.pojo;
import lombok.Data;
import java.util.List;
@Data
public class PageResult {
//总条数
private Long total;
//类型
private List<HotelDoc> hotels;
//不带参构造函数
public PageResult() {
}
//带参构造函数
public PageResult(Long total, List<HotelDoc> hotels) {
this.total = total;
this.hotels = hotels;
}
}(2)、把IHotelService接口,修改为如下
package cn.itcast.hotel.service;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import com.baomidou.mybatisplus.extension.service.IService;
public interface IHotelService extends IService<Hotel> {
PageResult search(RequestParams params);
}
(3)、把HotelDemoApplication启动类,修改为如下
package cn.itcast.hotel;
import com.baomidou.mybatisplus.annotation.DbType;
import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
@MapperScan("cn.itcast.hotel.mapper")
@SpringBootApplication
public class HotelDemoApplication {
public static void main(String[] args) {
SpringApplication.run(HotelDemoApplication.class, args);
}
@Bean
//注入es提供的RestHighLevelClient类
public RestHighLevelClient client(){
return new RestHighLevelClient(RestClient.builder(
//指定你Centos7部署的es的主机地址
HttpHost.create("http://192.168.127.180:9200")
));
}
}
(4)、在src/main/java/cn.itcast.hotel目录新建web.HotelController类,写入如下
package cn.itcast.hotel.web;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
@RequestMapping("/hotel")
public class HotelController {
//注入项目准备好的IHotelService接口
@Autowired
private IHotelService hotelService;
@PostMapping("/list")
//使用@RequestBody注解,接收前端的请求。PageResult、RequestParams是我们刚刚定义的实体类
public PageResult search(@RequestBody RequestParams params){
return hotelService.search(params);
}
}
三、定义IHotelService中的search方法,利用match查询实现根据关键字搜索酒店信息
(4)、把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
//注入在引导类声明好的@Bean
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
//准备Request对象,要查询哪个索引库,
SearchRequest request = new SearchRequest("hotel");
//【关键字搜索功能】
String key = params.getKey();//前端传过来的搜索关键字
//判断前端传的key是否为空,避免空指针
if (key == null || "".equals(key)) {
//matchAllQuery方法表示查es的全部文档,不需要条件
request.source().query(QueryBuilders.matchAllQuery());
} else {
//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空
request.source().query(QueryBuilders.matchQuery("all", key));
}
//【分页功能】
int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类
int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型
request.source().from((page - 1) * size).size(size);
//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//这个方法就是我们抽取出来的,负责解析的
private PageResult handleResponse(SearchResponse response) {
//解析获取到杂乱JSON数据
SearchHits searchHits = response.getHits();
//获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条文档(数据)");
//获取hits数组
SearchHit[] hits = searchHits.getHits();
//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
hotels.add(hotelDoc);
}
//封装返回
return new PageResult(total,hotels);
}
}
四、运行HotelDemoApplication引导类,浏览器访问 http://localhost:8089/

7. 条件过滤
先看需求。添加品牌、城市、星级、价格等条件过滤功能

分析:
1、修改RequestParams类,添加brand、city、startName、minPrice、maxPrice等参数
2、修改HotelService类的search方法的实现,在关键字搜索时,如果brand等参数存在,就需要对其做过滤
3、注意多个条件之间是AND关系,组合多条件用BooleanQuery
4、参数存在才需要过滤,做好非空判断
5、city精确匹配,brand精确匹配,startName精确匹配,price范围过滤
第一步: 把RequestParams类,修改为如下
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
//搜索关键字
private String key;
//当前页码
private Integer page;
//每页大小
private Integer size;
//将来的排序字段
private String sortBy;
//城市
private String city;
//品牌
private String brand;
//星级
private String starName;
//价格最小值
private Integer minPrice;
//价格最大值
private Integer maxPrice;
}
第二步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
//注入在引导类声明好的@Bean
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
//准备Request对象,要查询哪个索引库,
SearchRequest request = new SearchRequest("hotel");
//【构建BooleanQuery】
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//【关键字搜索】
//判断前端传的key是否为空,避免空指针
String key = params.getKey();//前端传过来的搜索关键字
//用的是must精确查找
if (key == null || "".equals(key)) {
//matchAllQuery方法表示查es的全部文档,不需要条件
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
//【条件过滤】
//城市,term精确查找,注意判空
if(params.getCity() != null && !params.getCity().equals("")){
boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));
}
//品牌,term精确查找,注意判空
if(params.getBrand() != null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));
}
//星级,term精确查找,注意判空
if(params.getStarName() != null && !params.getStarName().equals("")){
//注意下面那行的是starName,不要写成startName
boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));
}
//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
if(params.getMinPrice() != null && params.getMaxPrice() != null){
boolQuery.filter(QueryBuilders
.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//这一步必须有
request.source().query(boolQuery);
//【分页功能】
int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类
int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型
request.source().from((page - 1) * size).size(size);
//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//这个方法就是我们抽取出来的,负责解析的
private PageResult handleResponse(SearchResponse response) {
//解析获取到杂乱JSON数据
SearchHits searchHits = response.getHits();
//获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条文档(数据)");
//获取hits数组
SearchHit[] hits = searchHits.getHits();
//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
hotels.add(hotelDoc);
}
//封装返回
return new PageResult(total,hotels);
}
}
第三步: 运行HotelDemoApplication引导类,浏览器访问 http://localhost:8089/

第四步: 解决"四星","五星" 无法作为条件进行查询的问题

8. 我附近的酒店
需求: 实现前端页面点击定位后,会将你所在的位置发送给后台,前端的请求信息如下,会向后端发送location参数。
如果谷歌浏览器发送不了位置请求的话,建议临时换成火狐浏览器

分析:
1、修改RequestParams参数,接收来自前端的location字段
2、修改HotelService类的search方法的业务逻辑,如果location有值,就添加根据geo_distance排序的功能
java代码实现距离排序,对应的DSL语句如下

第一步: 把RequestParams类,修改为如下
package cn.itcast.hotel.pojo;
import lombok.Data;
@Data
public class RequestParams {
//搜索关键字
private String key;
//当前页码
private Integer page;
//每页大小
private Integer size;
//将来的排序字段
private String sortBy;
//城市
private String city;
//品牌
private String brand;
//星级
private String starName;
//价格最小值
private Integer minPrice;
//价格最大值
private Integer maxPrice;
//地理位置查询的字段,前端会把location传给我们
private String location;
}
第二步: 把HotelDoc类,修改为如下
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
//地理位置查询相关的字段。distance字段用于保存解析后的距离值
private Object distance;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
第三步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
//注入在引导类声明好的@Bean
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
//准备Request对象,要查询哪个索引库,
SearchRequest request = new SearchRequest("hotel");
//【构建BooleanQuery】
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//【关键字搜索】
//判断前端传的key是否为空,避免空指针
String key = params.getKey();//前端传过来的搜索关键字
//用的是must精确查找
if (key == null || "".equals(key)) {
//matchAllQuery方法表示查es的全部文档,不需要条件
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
//【条件过滤】
//城市,term精确查找,注意判空
if(params.getCity() != null && !params.getCity().equals("")){
boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));
}
//品牌,term精确查找,注意判空
if(params.getBrand() != null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));
}
//星级,term精确查找,注意判空
if(params.getStarName() != null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));
}
//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
if(params.getMinPrice() != null && params.getMaxPrice() != null){
boolQuery.filter(QueryBuilders
.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//这一步必须有
request.source().query(boolQuery);
//【分页功能】
int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类
int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型
request.source().from((page - 1) * size).size(size);
//【地理排序功能】
String location = params.getLocation();
//对前端传的location进行判断是否为空
if (location != null && !location.equals("")){
//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)
request.source().sort(SortBuilders
.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.ASC) //升序排序
.unit(DistanceUnit.KILOMETERS) //地理坐标的单位
);
}
//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//这个方法就是我们抽取出来的,负责解析的
private PageResult handleResponse(SearchResponse response) {
//解析获取到杂乱JSON数据
SearchHits searchHits = response.getHits();
//获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条文档(数据)");
//获取hits数组
SearchHit[] hits = searchHits.getHits();
//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值
Object[] sortValues = hit.getSortValues();
//判断是否为空
if (sortValues.length>0){
Object sortValue = sortValues[0];
//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDoc
hotelDoc.setDistance(sortValue);
}
hotels.add(hotelDoc);
}
//封装返回
return new PageResult(total,hotels);
}
}第四步: 重启HotelDemoApplication引导类,浏览器访问http://localhost:8089/。点击定位按钮,查看是否能查询出距离自己最近的酒店并显示米数

9. 广告置顶
需求: 让指定的酒店在搜索结果中排名置顶。我们给需要置顶的酒店文档添加一个标记。然后利用function score给带有标记的文档增加权重
分析:
1、给HotelDoc类添加isAD字段,Boolean类型
2、挑选几个你喜欢的酒店,给它的文档数据添加isAD字段,值为true
3、修改HotelService类的search方法,添加function score功能,给isAD值为true的酒店增加权重
Function Score查询可以控制文档的相关性算分,java代码以及对应DSL语句如下图

第一步: 把HotelDoc类,修改为如下
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
//地理位置查询相关的字段。distance字段用于保存解析后的距离值
private Object distance;
//用于广告置顶的字段
private Boolean isAD;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
}
}
第二步: 使用DSL语句为索引库增加字段,由于使用DSL语句需要在浏览器使用kibana,所以我们把docker里面的kibana容器运行一下
docker restart kibana #启动kibana容器
第三步: 启动kibana之后,浏览器访问 http://你的ip地址:5601
第四步: DSL语句,表示给某个id文档添加新字段。id不一定要跟我一样,随便去mysql数据库找几个id就行
POST /hotel/_update/1557997004
{
"doc":{
"isAD": true
}
}
POST /hotel/_update/1406627919
{
"doc":{
"isAD": true
}
}
第五步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
//注入在引导类声明好的@Bean
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
//准备Request对象,要查询哪个索引库,
SearchRequest request = new SearchRequest("hotel");
//【构建BooleanQuery,下面那行的boolQuery是原始查询】
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//【关键字搜索】
//判断前端传的key是否为空,避免空指针
String key = params.getKey();//前端传过来的搜索关键字
//用的是must精确查找
if (key == null || "".equals(key)) {
//matchAllQuery方法表示查es的全部文档,不需要条件
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
//【条件过滤】
//城市,term精确查找,注意判空
if(params.getCity() != null && !params.getCity().equals("")){
boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));
}
//品牌,term精确查找,注意判空
if(params.getBrand() != null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));
}
//星级,term精确查找,注意判空
if(params.getStarName() != null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));
}
//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
if(params.getMinPrice() != null && params.getMaxPrice() != null){
boolQuery.filter(QueryBuilders
.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//【构建functionScoreQuery,实现算分查询。对应的是广告置顶功能】
FunctionScoreQueryBuilder functionScoreQuery =
//原始查询,需要进行相关性算分的查询
QueryBuilders.functionScoreQuery(boolQuery,
//function score的数组,里面有很多function score
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
//一个具体的function score
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
//过滤,简单说就是满足isAD字段为true的文档就会参与算分
QueryBuilders.termQuery("isAD",true),
//要使用什么算分函数,下面那行使用的是weightFactorFunction加权算分,最终score分数越大,排名就越前
ScoreFunctionBuilders.weightFactorFunction(10)//算出来的最终score就会被乘10
)
});
//这一步必须有
request.source().query(functionScoreQuery);
//【分页功能】
int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类
int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型
request.source().from((page - 1) * size).size(size);
//【地理排序功能】
String location = params.getLocation();
//对前端传的location进行判断是否为空
if (location != null && !location.equals("")){
//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)
request.source().sort(SortBuilders
.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.ASC) //升序排序
.unit(DistanceUnit.KILOMETERS) //地理坐标的单位
);
}
//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//这个方法就是我们抽取出来的,负责解析的
private PageResult handleResponse(SearchResponse response) {
//解析获取到杂乱JSON数据
SearchHits searchHits = response.getHits();
//获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条文档(数据)");
//获取hits数组
SearchHit[] hits = searchHits.getHits();
//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值
Object[] sortValues = hit.getSortValues();
//判断是否为空
if (sortValues.length>0){
Object sortValue = sortValues[0];
//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDoc
hotelDoc.setDistance(sortValue);
}
hotels.add(hotelDoc);
}
//封装返回
return new PageResult(total,hotels);
}
}
第六步: 重启HotelDemoApplication引导类,浏览器访问http://localhost:8089/。查看我们指定的那两个酒店是否置顶

10. 高亮显示
高亮API包括请求DSL构建和结果解析两部分,API和对应的DSL语句如下图,下图只是构建,再下面还有解析,高亮必须由构建+解析才能实现

解析,如下图

第一步: 把HotelService类,修改为如下
package cn.itcast.hotel.service.impl;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.toolkit.CollectionUtils;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
//注入在引导类声明好的@Bean
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
//准备Request对象,要查询哪个索引库,
SearchRequest request = new SearchRequest("hotel");
//【构建BooleanQuery,下面那行的boolQuery是原始查询】
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//【关键字搜索】
//判断前端传的key是否为空,避免空指针
String key = params.getKey();//前端传过来的搜索关键字
//用的是must精确查找
if (key == null || "".equals(key)) {
//matchAllQuery方法表示查es的全部文档,不需要条件
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
//【条件过滤】
//城市,term精确查找,注意判空
if(params.getCity() != null && !params.getCity().equals("")){
boolQuery.filter(QueryBuilders.termQuery("city",params.getCity()));
}
//品牌,term精确查找,注意判空
if(params.getBrand() != null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand",params.getBrand()));
}
//星级,term精确查找,注意判空
if(params.getStarName() != null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName",params.getStarName()));
}
//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
if(params.getMinPrice() != null && params.getMaxPrice() != null){
boolQuery.filter(QueryBuilders
.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//【构建functionScoreQuery,实现算分查询。对应的是广告置顶功能】
FunctionScoreQueryBuilder functionScoreQuery =
//原始查询,需要进行相关性算分的查询
QueryBuilders.functionScoreQuery(boolQuery,
//function score的数组,里面有很多function score
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
//一个具体的function score
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
//过滤,简单说就是满足isAD字段为true的文档就会参与算分
QueryBuilders.termQuery("isAD",true),
//要使用什么算分函数,下面那行使用的是weightFactorFunction加权算分,最终score分数越大,排名就越前
ScoreFunctionBuilders.weightFactorFunction(10)//算出来的最终score就会被乘10
)
});
//【高亮显示】对查询出来的文档,的特定字段进行高亮显示
request.source().highlighter(new HighlightBuilder().field("all").requireFieldMatch(true).preTags("<em>").postTags("</em>"));
//这一步必须有
request.source().query(functionScoreQuery);
//【分页功能】
int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类
int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型
request.source().from((page - 1) * size).size(size);
//【地理排序功能】
String location = params.getLocation();
//对前端传的location进行判断是否为空
if (location != null && !location.equals("")){
//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)
request.source().sort(SortBuilders
.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.ASC) //升序排序
.unit(DistanceUnit.KILOMETERS) //地理坐标的单位
);
}
//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
//这个方法就是我们抽取出来的,负责解析的
private PageResult handleResponse(SearchResponse response) {
//解析获取到杂乱JSON数据
SearchHits searchHits = response.getHits();
//获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条文档(数据)");
//获取hits数组
SearchHit[] hits = searchHits.getHits();
//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值
Object[] sortValues = hit.getSortValues();
//判断是否为空
if (sortValues.length>0){
Object sortValue = sortValues[0];
//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDoc
hotelDoc.setDistance(sortValue);
}
//【解析】获取高亮结果
Map<String, HighlightField> xxhighlightFields = hit.getHighlightFields();
//使用CollectionUtils工具类,进行判空,避免空指针
if (!CollectionUtils.isEmpty(xxhighlightFields)){
//根据字段名获取高亮结果
HighlightField xxhighlightField = xxhighlightFields.get("all");
//判断name不为空
if (xxhighlightField != null) {
//获取高亮值
String xxname = xxhighlightField.getFragments()[0].string();
//覆盖非高亮结果
hotelDoc.setName(xxname);
}
}
hotels.add(hotelDoc);
}
//封装返回
return new PageResult(total,hotels);
}
}第二步: 重启HotelDemoApplication引导类,浏览器访问http://localhost:8089/。查看是否能将搜索词高亮显示

写好的项目: 文件下载-奶牛快传 Download |CowTransfer
实用篇-ES-数据聚合
官方文档: https://www.elastic.co/guide/en/elasticsearch/reference/current/search-aggregations.html
1. 聚合的分类
聚合: 可以实现对文档数据的统计、分析、运算。聚合常见的有如下三类。注意,聚合的字段必然是不分词的,原因: 聚合不能是text类型
●桶 (Bucket) 聚合: 用来对文档做分组
- ○Term Aggregation聚合: 按照文档字段值分组。(我们下面会演示这个,按照品牌进行分桶)
- ○Date Histogram聚合: 按照日期阶梯分组,例如一周为一组,或者一月为一组
●度量 (Metric) 聚合: 用以计算一些值,比如最大值、最小值、平均值
- ○avg: 求平均值
- ○max: 求最大值
- ○min: 求最小值
- ○stats: 同时求max、min、avg、sum。(我们下面会演示这个,按照品牌进行求评分最值和平均值)
●管道 (Pipeline) 聚合: 其它聚合的结果为基础做聚合。这种用的不多
2. DSL实现Bucket聚合
Bucket聚合,也就是桶聚合
现在,我们要统计所有数据中的酒店品牌有多少种,此时我们可以根据酒店品牌的名称做聚合,由于品牌是字段,也就是要对字段值做分组,采用的是TermAggregation聚合,类型为term类型,DSL示例如下
确保你的环境正常启动
浏览器访问 http://你的ip地址:5601
然后我们使用的索引库是hotel,没有这个索引库的话,可以去前面 '实用篇-ES-黑马旅游案例' 的 '5. 环境准备-同步数据' 进行索引库的创建和添加数据
第一步: 具体操作,浏览器输入如下,表示对不同的品牌进行聚合,也就是不同的品牌为不同的桶,相同的品牌放进一个桶里面


第二步: 如何修改默认的排序规则,我们不希望是按照找出来的文档总条数降序排序。默认情况下,Bucket会统计Bucket内的文档数量,记为_count,并且按照count降序排序。我们如果要修改结果排序方式的话,只需要加一个order属性,如下


第三步: 我们上面是对整个索引库的数据做聚合搜索,如果索引库本身有庞大数据的话,对整个索引库的聚合搜索是对内存消耗非常大,我们希望自定义聚合的搜索范围,也就是限定要聚合的文档范围,只需要添加query条件即可,如下
gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于


3. DSL实现Metrics聚合
Metrics聚合,也就是度量聚合。例如,我们要求获取每个品牌的用户评分的min最小值、max最大值、avg平均值。注意不是整个索引库的所有酒店(文档)进行求值,所以要结合上一节的Bucket聚合一起使用
确保你的环境正常启动
浏览器访问 http://你的ip地址:5601
第一步: 具体操作,浏览器输入如下,表示对品牌(父聚合)的评分(子聚合)进行求值

第二步: 如果我们还需要对结果按照评分的平均值,再去做个排序,看一下哪个酒店评价最高,注意我们是在同里面做排序,也就是排序要写在terms里面

4. RestClient实现聚合
确保你的环境正常启动
如何在java代码使用RestClient来实现聚合。java代码以及对应的DSL语句如下图
请求,得到的是json数据

解析,对聚合结果的json数据进行解析

具体操作: 是基于之前的hotel-demo项目上继续编写,前面学的 '实用篇-ES-RestClient查询文档' 的基础上进行编写
第一步: 在HotelSearchTest类,添加如下
@Test
void testAggregation() throws IOException {
//准备Request对象
SearchRequest xxrequest = new SearchRequest("hotel");
//准备DSL。设置size
xxrequest.source().size(0);
//准备DSL。聚合语句
xxrequest.source().aggregation(AggregationBuilders
.terms("BrandAggMyName") //自定义聚合名称为BrandAggMyName
.field("brand")
.size(10)
);
//发出请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//【解析】
//解析聚合结果
Aggregations xxaggregations = xxresponse.getAggregations();
//根据聚合名称获取聚合结果
Terms xxbrandTerms = xxaggregations.get("BrandAggMyName");
//获取桶(buckets),获取的是一个集合
List<? extends Terms.Bucket> xxbuckets = xxbrandTerms.getBuckets();
//遍历集合,取出每一个bucket
for (Terms.Bucket xxbucket : xxbuckets) {
//获取key。这个key就是品牌信息
String key = xxbucket.getKeyAsString();
System.out.println(key);
}
}
第二步: 运行testAggregation方法

5. 多条件聚合
案例: 在前面的 '黑马路由案例' 中,搜索页面的品牌、城市等信息不应该是在页面写死,而是通过聚合索引库中的酒店数据得来的

确保你的环境正常启动
第一步: 在IHotelService接口添加如下
/**
* 查询城市、星级、品牌的聚合结果
* @return 聚合结果,格式:{"城市": ["上海", "北京"], "品牌": ["如家", "希尔顿"]}
*/
//在给出来的案例图中,左侧加深的字是key,右侧浅灰的字是value,并且右侧的value有多个值。所以我们使用Map集合,并且value是list集合
Map<String, List<String>> xxfilters();
第二步: 在HotelService实现类添加如下
@Override
public Map<String, List<String>> xxfilters() {
try {
//准备Request对象
SearchRequest xxrequest = new SearchRequest("hotel");
//准备DSL。设置size
xxrequest.source().size(0);
//准备DSL。聚合语句。对多个字段进行聚合
buildAggregation(xxrequest);
//发出请求
SearchResponse xxresponse = client.search(xxrequest, RequestOptions.DEFAULT);
//【解析】
//解析聚合结果
Map<String, List<String>> yyresult = new HashMap<>();
Aggregations xxaggregations = xxresponse.getAggregations();
//1、根据名称获取品牌的结果
List<String> xxbrandList = getAggByName(xxaggregations,"BrandAggMyName");
//把品牌的结果信息放入map
yyresult.put("品牌",xxbrandList);
//2、根据名称获取城市的结果
List<String> xxcityList = getAggByName(xxaggregations,"cityAggMyName");
//把城市的结果信息放入map
yyresult.put("城市",xxcityList);
//3、根据名称获取星级的结果
List<String> xxstarList = getAggByName(xxaggregations,"starAggMyName");
//把星级的结果信息放入map
yyresult.put("星级",xxstarList);
//返回yyresult
return yyresult;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List<String> getAggByName(Aggregations xxaggregations,String kkaggName) {
//根据聚合名称获取聚合结果
Terms xxbrandTerms = xxaggregations.get(kkaggName);
//获取桶(buckets),获取的是一个集合
List<? extends Terms.Bucket> xxbuckets = xxbrandTerms.getBuckets();
//遍历xxbuckets集合,取出每一个key。把取到的key放到xxbrandList集合
List<String> xxbrandList = new ArrayList<>();
for (Terms.Bucket xxbucket : xxbuckets) {
//获取key。这个key就是品牌信息
String xxkey = xxbucket.getKeyAsString();
xxbrandList.add(xxkey);
}
return xxbrandList;
}
//把聚合的代码抽取出来
private void buildAggregation(SearchRequest xxrequest) {
xxrequest.source().aggregation(AggregationBuilders
.terms("BrandAggMyName") //自定义聚合名称为BrandAggMyName
.field("brand")
.size(100)//聚合结果限制
);
xxrequest.source().aggregation(AggregationBuilders
.terms("cityAggMyName")
.field("city")
.size(100)
);
xxrequest.source().aggregation(AggregationBuilders
.terms("starAggMyName")
.field("starName")
.size(100)
);
}
抽取代码成为方法

第三步: 在HotelDemoApplicationTests添加如下。并运行contextLoads方法
@Autowired
private IHotelService hotelService;
@Test
void contextLoads() {
Map<String, List<String>> filters = hotelService.xxfilters();
System.out.println(filters);
}
6. hm-带过滤条件的聚合
对接前端接口,也就是把上面 '5. 多条件聚合' 实现的功能返回到前端页面,达到最终效果
前端页面会向服务端发起请求,查询品牌、城市、星级字段的聚合结果
确保你的环境正常启动
首先,保证你已经学完前面的 '实用篇-ES-黑马旅游案例' 并且在浏览器能打开前端页面

点击页面的搜索,打开浏览器控制台看一下前端向后端请求的参数

分析:
1、可以看到请求参数与之前search时的RequestParam完全一致,这是在限定聚合时的文档范围。用户搜索“外滩”,价格在300~600,那聚合必须是在这个搜索条件基础上完成
2、编写controller接口,接收该请求
3、修改IUserService#getFilters()方法,添加RequestParam参数
3、修改getFilters方法的业务,聚合时添加query条件
具体操作如下
第一步: 把HotelDemoApplicationTests类注释掉
第二步: 把IHotelService接口修改为如下,原本xxfilters方法是没有参数的,现在我们要给xxfilters方法添加参数
package cn.itcast.hotel.service;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import com.baomidou.mybatisplus.extension.service.IService;
import java.util.List;
import java.util.Map;
public interface IHotelService extends IService<Hotel> {
PageResult search(RequestParams params);
/**
* 查询城市、星级、品牌的聚合结果
* @return 聚合结果,格式:{"城市": ["上海", "北京"], "品牌": ["如家", "希尔顿"]}
*/
//在给出来的案例图中,左侧加深的字是key,右侧浅灰的字是value,并且右侧的value有多个值。所以我们使用Map集合,并且value是list集合
Map<String, List<String>> xxfilters(RequestParams params);
}
第三步: 把HotelService实现类修改为如下
package cn.itcast.hotel.service.impl;
import cn.itcast.hotel.mapper.HotelMapper;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.HotelDoc;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.pojo.RequestParams;
import cn.itcast.hotel.service.IHotelService;
import com.alibaba.fastjson.JSON;
import com.baomidou.mybatisplus.core.toolkit.CollectionUtils;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.geo.GeoPoint;
import org.elasticsearch.common.unit.DistanceUnit;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.functionscore.FunctionScoreQueryBuilder;
import org.elasticsearch.index.query.functionscore.ScoreFunctionBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.aggregations.AggregationBuilders;
import org.elasticsearch.search.aggregations.Aggregations;
import org.elasticsearch.search.aggregations.bucket.terms.Terms;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
@Service
public class HotelService extends ServiceImpl<HotelMapper, Hotel> implements IHotelService {
@Autowired
//注入在引导类声明好的@Bean
private RestHighLevelClient client;
@Override
public PageResult search(RequestParams params) {
try {
//准备Request对象,要查询哪个索引库,
SearchRequest request = new SearchRequest("hotel");
buildBasicQuery(params, request);
//【分页功能】
int page = params.getPage();//前端传过来的当前页面值,注意为了参与运算,我们将原来的Integer类型拆箱为int类型,不用包装类
int size = params.getSize();//前端传过来的每页大小。其实拆箱就是把默认的包装类类型,改成基本类型
request.source().from((page - 1) * size).size(size);
//【地理排序功能】
String location = params.getLocation();
//对前端传的location进行判断是否为空
if (location != null && !location.equals("")){
//sort排序,指定是geoDistanceSort地理坐标排序,要排序的字段是location,中心点是new GeoPoint(location)
request.source().sort(SortBuilders
.geoDistanceSort("location",new GeoPoint(location))
.order(SortOrder.ASC) //升序排序
.unit(DistanceUnit.KILOMETERS) //地理坐标的单位
);
}
//发送请求。下面那行的search报红线,我们不能抛出,要捕获一下
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//调用下面抽取后的方法,我们是把解析的代码抽取出去了。并把解析作为结果返回
return handleResponse(response);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private SearchRequest buildBasicQuery(RequestParams params,SearchRequest request) {
//【构建BooleanQuery,下面那行的boolQuery是原始查询】
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();
//【关键字搜索】
//判断前端传的key是否为空,避免空指针
String key = params.getKey();//前端传过来的搜索关键字
//用的是must精确查找
if (key == null || "".equals(key)) {
//matchAllQuery方法表示查es的全部文档,不需要条件
boolQuery.must(QueryBuilders.matchAllQuery());
} else {
//matchQuery表示按照分词查询es的文档,需要条件,这个条件我们进行了判空
boolQuery.must(QueryBuilders.matchQuery("all", key));
}
//【条件过滤】
//城市,term精确查找,注意判空
if(params.getCity() != null && !params.getCity().equals("")){
boolQuery.filter(QueryBuilders.termQuery("city", params.getCity()));
}
//品牌,term精确查找,注意判空
if(params.getBrand() != null && !params.getBrand().equals("")){
boolQuery.filter(QueryBuilders.termQuery("brand", params.getBrand()));
}
//星级,term精确查找,注意判空
if(params.getStarName() != null && !params.getStarName().equals("")){
boolQuery.filter(QueryBuilders.termQuery("starName", params.getStarName()));
}
//价格,range范围过滤,注意判空。gt表示大于,gte表示大于等于,lt表示小于,lte表示小于等于
if(params.getMinPrice() != null && params.getMaxPrice() != null){
boolQuery.filter(QueryBuilders
.rangeQuery("price").gte(params.getMinPrice()).lte(params.getMaxPrice()));
}
//【构建functionScoreQuery,实现算分查询。对应的是广告置顶功能】
FunctionScoreQueryBuilder functionScoreQuery =
//原始查询,需要进行相关性算分的查询
QueryBuilders.functionScoreQuery(boolQuery,
//function score的数组,里面有很多function score
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
//一个具体的function score
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
//过滤,简单说就是满足isAD字段为true的文档就会参与算分
QueryBuilders.termQuery("isAD",true),
//要使用什么算分函数,下面那行使用的是weightFactorFunction加权算分,最终score分数越大,排名就越前
ScoreFunctionBuilders.weightFactorFunction(10)//算出来的最终score就会被乘10
)
});
//【高亮显示】对查询出来的文档,的特定字段进行高亮显示
request.source().highlighter(new HighlightBuilder().field("all").requireFieldMatch(true).preTags("<em>").postTags("</em>"));
//这一步必须有
request.source().query(functionScoreQuery);
return request;
}
//这个方法就是我们抽取出来的,负责解析的
private PageResult handleResponse(SearchResponse response) {
//解析获取到杂乱JSON数据
SearchHits searchHits = response.getHits();
//获取总条数
long total = searchHits.getTotalHits().value;
System.out.println("共搜索到"+total+"条文档(数据)");
//获取hits数组
SearchHit[] hits = searchHits.getHits();
//遍历数组,把hits数组的每个source取出来,把遍历到的每条数据添加到lisi集合
List<HotelDoc> hotels = new ArrayList<>();
for (SearchHit hit : hits) {
String json = hit.getSourceAsString();
//此时可以直接打印,也可以使用fastjson工具类进行反序列化,从而转为HotelDoc类型,HotelDoc类是我们写的实体类
HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);
//【地理坐标查询的解析】,通过getSortValues方法来获取排序值,得到的是多个值也就是数组,我们只需要一个值
Object[] sortValues = hit.getSortValues();
//判断是否为空
if (sortValues.length>0){
Object sortValue = sortValues[0];
//把拿到的sortValue返回到页面,也就是需要把sortValue值放到HoteDoc
hotelDoc.setDistance(sortValue);
}
//【解析】获取高亮结果
Map<String, HighlightField> xxhighlightFields = hit.getHighlightFields();
//使用CollectionUtils工具类,进行判空,避免空指针
if (!CollectionUtils.isEmpty(xxhighlightFields)){
//根据字段名获取高亮结果
HighlightField xxhighlightField = xxhighlightFields.get("all");
//判断name不为空
if (xxhighlightField != null) {
//获取高亮值
String xxname = xxhighlightField.getFragments()[0].string();
//覆盖非高亮结果
hotelDoc.setName(xxname);
}
}
hotels.add(hotelDoc);
}
//封装返回
return new PageResult(total,hotels);
}
//--------------------------------------------下面是多条件聚合-----------------------------------------
@Override
public Map<String, List<String>> xxfilters(RequestParams params) {
try {
//准备Request对象
SearchRequest xxrequest = new SearchRequest("hotel");
//添加query查询信息,也就是限定聚合的范围
buildBasicQuery(params, xxrequest);
//准备DSL。设置size
xxrequest.source().size(0);
//准备DSL。聚合语句。对多个字段进行聚合
buildAggregation(xxrequest);
//发出请求
SearchResponse xxresponse = client.search(xxrequest, RequestOptions.DEFAULT);
//【解析】
//解析聚合结果
Map<String, List<String>> yyresult = new HashMap<>();
Aggregations xxaggregations = xxresponse.getAggregations();
//1、根据名称获取品牌的结果
List<String> xxbrandList = getAggByName(xxaggregations,"BrandAggMyName");
//把品牌的结果信息放入map
yyresult.put("brand",xxbrandList);
//2、根据名称获取城市的结果
List<String> xxcityList = getAggByName(xxaggregations,"cityAggMyName");
//把城市的结果信息放入map
yyresult.put("city",xxcityList);
//3、根据名称获取星级的结果
List<String> xxstarList = getAggByName(xxaggregations,"starAggMyName");
//把星级的结果信息放入map
yyresult.put("starName",xxstarList);
//返回yyresult
return yyresult;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
private List<String> getAggByName(Aggregations xxaggregations,String kkaggName) {
//根据聚合名称获取聚合结果
Terms xxbrandTerms = xxaggregations.get(kkaggName);
//获取桶(buckets),获取的是一个集合
List<? extends Terms.Bucket> xxbuckets = xxbrandTerms.getBuckets();
//遍历xxbuckets集合,取出每一个key。把取到的key放到xxbrandList集合
List<String> xxbrandList = new ArrayList<>();
for (Terms.Bucket xxbucket : xxbuckets) {
//获取key。这个key就是品牌信息
String xxkey = xxbucket.getKeyAsString();
xxbrandList.add(xxkey);
}
return xxbrandList;
}
//把聚合的代码抽取出来
private void buildAggregation(SearchRequest xxrequest) {
xxrequest.source().aggregation(AggregationBuilders
.terms("BrandAggMyName") //自定义聚合名称为BrandAggMyName
.field("brand")
.size(100)//聚合结果限制
);
xxrequest.source().aggregation(AggregationBuilders
.terms("cityAggMyName")
.field("city")
.size(100)
);
xxrequest.source().aggregation(AggregationBuilders
.terms("starAggMyName")
.field("starName")
.size(100)
);
}
//--------------------------------------------上面是多条件聚合-----------------------------------------
}
第四步: 重新运行HotelDemoApplication引导类,浏览器查看是否功能正常

实用篇-ES-自动补全
1. 安装拼音分词器
elasticsearch的拼音分词插件的官方地址: GitHub - infinilabs/analysis-pinyin: 🛵 This Pinyin Analysis plugin is used to do conversion between Chinese characters and Pinyin.
拼音分词插件下载: 文件下载-奶牛快传 Download |CowTransfer
第一步: 下载下来是py.zip压缩包,解压之后得到一个py文件夹,把这个文件夹上传到你CentOS7的 /var/lib/docker/volumes/es-plugins/_data 目录

第二步: 重启es。注意我们的拼音分词器的版本是跟es版本一致的
第三步: 验证拼音分词器是否生效
docker restart kibana #启动kibana容器。由于在网页使用DSL去操作es,所以就需要kibana
浏览器访问 http://你的ip地址:5601
输入如下DSL语句,会把文本的每个中文分成对应的拼音,也会把整段文本的拼音首字母拼在一起
POST /_analyze
{
"text": ["如家酒店"],
"analyzer": "pinyin"
}
2. 自定义分词器
刚才我们看到了拼音分词器的效果,但是并不能用于生产环境,还存在一些问题

Elasticsearch中的分词器(analyzer)的组成包含三部分
●character filters: 在tokenizer之前对文本进行处理。例如删除字符、替换字符
●tokenizer: 将文本按照一定的规则切割成词条 (term)。例如keyword, 就是不分词; 还有ik_smart。这部分是真正的分词器
●tokenizer filter: 将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
我们可以按照下图的作用顺序解决拼音分词器的不足: 拼音分词器不会分词,那么就先用ik分词器,分好词后再交给拼音分词器

解决如下,注意必须在创建索引库的时候做,例如创建一个名为test的索引库
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py" //过滤器名称
}
},
"filter": { // 自定义tokenizer filter
"py": { // 自定义过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false, //不允许单个字来分拼音
"keep_joined_full_pinyin": true, //全拼,给什么字或词就把什么写成拼音
"keep_original": true, //保留中文,解决了拼音分词器分词后全是拼音的问题
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}
具体操作如下,注意自定义分词器只对当前索引库有效,因为我们是写在settings属性里面
确保你的环境正常启动
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器,因为我们需要在浏览器执行DSL语句去操作es
第一步: 浏览器访问 http://你的ip地址:5601
输入如下DSL语句,表示创建名为test的索引库,实现自定义分词器,也就是对分词器做一些限制、开放一些限制
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
第二步: 测试自定义分词器(也就是ik分词器+拼音分词器)。第一种测试方法
POST /test/_analyze
{
"text": ["如家酒店"],
"analyzer": "my_analyzer"
}
第三步: 测试自定义分词器(也就是ik分词器+拼音分词器)。第二种测试方法,通过往test库插入文档、然后查询插入的文档的方式来测试
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}
第四步: 其实还是有个问题,如下图,在搜索中文时,却搜索出了同音字,我们不想搜索出同音字,解决在下一节会学

3. 解决自定义分词器的问题
拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用
因此,字段在创建倒排索引时应该用自定义分词器(my_analyzer); 字段在搜索时应该使用is_smart分词器。对应的DSL语句如下
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word", "filter": "py"
}
},
"filter": {
"py": { ... }
}
}
},
"mappings": { //在mappings里面指定两个分词器
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer", //analyzer表示创建索引时使用这个my_analyzer分词器
"search_analyzer": "ik_smart" //search_analyzer表示在搜索时使用这个search_analyzer分词器
}
}
}
}
具体操作如下
确保你的环境正常启动
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器,因为我们需要在浏览器执行DSL语句去操作es
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,先删除刚刚上面创建的test索引库
DELETE /test
第三步: 输入如下DSL语句,重新创建test索引库,这次我们在mappings属性里面多添加了一个分词器"search_analyzer": "ik_smart"
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
第四步: 测试。同样是往test库创建两个文档,然后使用中文去匹配,如果不出现同音字就表示验证通过
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "狮子"
}
}
}

4. DSL实现自动补全查询
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
es在实现自动补全功能时,对查询的字段有以下两个要求
1、参与补全查询的字段必须是completion类型
2、字段的内容一般是用来补全的多个词条形成的数组

查询语法如下
// 自动补全查询
GET /test/_search
{
"suggest": { //不是query,而是suggest,表示自动补全
"title_suggest": { //自定义自动补全查询的名字
"text": "s", // 关键字,例如用户输入s,就会触发
"completion": { //自动补全的类型
"field": "title", // 要自动补全查询的字段,注意该字段必须是completion类型
"skip_duplicates": true, // 跳过重复的
"size": 10 // 获取前10条结果
}
}
}
}
具体操作如下,注意自定义分词器只对当前索引库有效,因为我们是写在settings属性里面
确保你的环境正常启动
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart kibana #启动kibana容器,因为我们需要在浏览器执行DSL语句去操作es
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,先删除刚刚上面创建的test索引库
DELETE /test
第三步: 输入如下DSL语句,表示重新创建test索引库,并为索引库添加3条文档数据
PUT test
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
POST test/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test/_doc
{
"title": ["Nintendo", "switch"]
}
第四步: 测试。自动补全查询。输入如下DSL语句
GET /test/_search
{
"suggest": {
"zidingyichaxunmingcheng": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}
5. hm-修改酒店索引库数据结构
请把前面的 '1. 安装拼音分词器' 和 '2. 自定义分词器' 和 '3. 解决自定义分词器的问题' 做完才能进行下面的操作
我们接下来要把自动补全功能应用在前面学习的黑马旅游案例中,这节我们就先学习如下几点
1、修改hotel索引库结构,设置自定义拼音分词器
2、修改索引库的name、all字段,使用自定义分词器
3、索引库添加一个新字段suggestion,类型为completion类型,使用自定义的分词器
确保你的环境正常启动
第一步: 浏览器访问 http://你的ip地址:5601
第二步: 输入如下DSL语句,先删除已有的hotel索引库
DELETE /hotel
第三步: 输入如下DSL语句。重新创建一个hotel索引库,只是创建一个空的hotel索引库
PUT /hotel
{
"settings": {
"analysis": {
"analyzer": {
"text_anlyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
},
"completion_analyzer": {
"tokenizer": "keyword",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"id":{
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart",
"copy_to": "all"
},
"address":{
"type": "keyword",
"index": false
},
"price":{
"type": "integer"
},
"score":{
"type": "integer"
},
"brand":{
"type": "keyword",
"copy_to": "all"
},
"city":{
"type": "keyword"
},
"starName":{
"type": "keyword"
},
"business":{
"type": "keyword",
"copy_to": "all"
},
"location":{
"type": "geo_point"
},
"pic":{
"type": "keyword",
"index": false
},
"all":{
"type": "text",
"analyzer": "text_anlyzer",
"search_analyzer": "ik_smart"
},
"suggestion":{
"type": "completion",
"analyzer": "completion_analyzer"
}
}
}
}
第四步: 由于某个文档(酒店)可能包括多个商圈,如下图,所以在下一步我们会在HotelDoc类进行切割后存入suggestion

第五步: 在上面的DSL语句中,我们还多创建了一个suggestion字段,所以对应的我们需要在黑马旅游案例的java代码中修改实体类
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
//地理位置查询相关的字段。distance字段用于保存解析后的距离值
private Object distance;
//用于广告置顶的字段
private Boolean isAD;
//用于自动补全的类型,该类型在es中必须是completion类型,该类型在java中就要写成数组(我们写成集合)
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
if(this.business.contains("/")){//如果同一文档的business商圈有多个,为了自动补全的分词效果更明显,我们需要分割一下
String[] arr = this.business.split("/");
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
//Collections是工具类,可以把数组数据逐个放进suggestion集合
Collections.addAll(this.suggestion,arr);
}else{
//自动补全我们可以让'品牌+商圈'来做自动补全,用户触发自动补全时,补全到的就是'品牌+商圈'字段的文档
this.suggestion = Arrays.asList(this.brand,this.business);
}
}
}
打开hotel-demo项目(继续做前面学的黑马旅游案例),把HotelDoc类修改为如下
package cn.itcast.hotel.pojo;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;
@Data
@NoArgsConstructor
public class HotelDoc {
private Long id;
private String name;
private String address;
private Integer price;
private Integer score;
private String brand;
private String city;
private String starName;
private String business;
private String location;
private String pic;
//地理位置查询相关的字段。distance字段用于保存解析后的距离值
private Object distance;
//用于广告置顶的字段
private Boolean isAD;
//用于自动补全的类型,该类型在es中必须是completion类型,该类型在java中就要写成数组(我们写成集合)
private List<String> suggestion;
public HotelDoc(Hotel hotel) {
this.id = hotel.getId();
this.name = hotel.getName();
this.address = hotel.getAddress();
this.price = hotel.getPrice();
this.score = hotel.getScore();
this.brand = hotel.getBrand();
this.city = hotel.getCity();
this.starName = hotel.getStarName();
this.business = hotel.getBusiness();
this.location = hotel.getLatitude() + ", " + hotel.getLongitude();
this.pic = hotel.getPic();
if(this.business.contains("/")){//如果同一文档的business商圈有多个,为了自动补全的分词效果更明显,我们需要分割一下
String[] arr = this.business.split("/");
this.suggestion = new ArrayList<>();
this.suggestion.add(this.brand);
//Collections是工具类,可以把数组数据逐个放进suggestion集合
Collections.addAll(this.suggestion,arr);
}else{
//自动补全我们可以让'品牌+商圈'来做自动补全,用户触发自动补全时,补全到的就是'品牌+商圈'字段的文档
this.suggestion = Arrays.asList(this.brand,this.business);
}
}
}
第六步: 运行HotelDocumentTest类的testBulkRequest方法,重新把mysql的数据导入到es的hotel索引库

第七步: 验证。自动补全功能



6. RestAPI实现自动补全查询
查询API和对应的DSL关系如下图

解析API和对应的DSL关系如下图

确保你的环境正常启动
具体操作如下
第一步: 在HotelSearchTest类添加如下,并运行xxtestSuggest方法
@Test
void xxtestSuggest() throws IOException {
//准备Request,查的是哪个索引库
SearchRequest xxrequest = new SearchRequest("hotel");
//准备DSL,自动补全查询也就是suggestion查询
xxrequest.source().suggest(new SuggestBuilder().addSuggestion(
"zidingyizidongbuquanmingzi",
//要自动补全哪个字段
SuggestBuilders.completionSuggestion("suggestion")
//模拟用户在搜索框输入查找
.prefix("h")
//跳过重复,不把重复的结果展示
.skipDuplicates(true)
//查多少条数据
.size(10)
));
//发起请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析结果
System.out.println(xxresponse);
}

第二步: 结果解析。把HotelSearchTest类的xxtestSuggest方法修改为如下,并运行xxtestSuggest方法
@Test
void xxtestSuggest() throws IOException {
//准备Request,查的是哪个索引库
SearchRequest xxrequest = new SearchRequest("hotel");
//准备DSL,自动补全查询也就是suggestion查询
xxrequest.source().suggest(new SuggestBuilder().addSuggestion(
"zidingyizidongbuquanmingzi", //为这个自定义补全查询起一个名字
//要自动补全哪个字段
SuggestBuilders.completionSuggestion("suggestion")
//模拟用户在搜索框输入查找
.prefix("h")
//跳过重复,不把重复的结果展示
.skipDuplicates(true)
//查多少条数据
.size(10)
));
//发起请求
SearchResponse xxresponse = xxclient.search(xxrequest, RequestOptions.DEFAULT);
//解析结果
Suggest xxsuggest = xxresponse.getSuggest();
//根据'补全查询名称',获取补全结果
CompletionSuggestion xxsuggestions = xxsuggest.getSuggestion("zidingyizidongbuquanmingzi");
//获取xxsuggestions
List<CompletionSuggestion.Entry.Option> xxoptions = xxsuggestions.getOptions();
//遍历
for (CompletionSuggestion.Entry.Option xxoption : xxoptions) {
String text = xxoption.getText().toString();
System.out.println(text);
}
}
7. hm-搜索框自动补全查询
确保你的环境正常启动
我们刚刚使用RestAPI实现了自动补全查询,现在我们要把这个功能应用在 '黑马旅游案例' 的搜索框,首先来看一下前端给我们传来的参数,如下图
我们需要编写接口,接收该请求,返回补全结果的集合,类型为List

具体操作如下
第一步: 在IHotelService接口添加如下
List<String> xxgetSuggestions(String xxprefix);
第二步: 在HotelService类添加如下
@Override
public List<String> xxgetSuggestions(String xxprefix) {
try {
//准备Request,查的是哪个索引库
SearchRequest xxrequest = new SearchRequest("hotel");
//准备DSL,自动补全查询也就是suggestion查询
xxrequest.source().suggest(new SuggestBuilder().addSuggestion(
"zidingyizidongbuquanmingzi", //为这个自定义补全查询起一个名字
//要自动补全哪个字段
SuggestBuilders.completionSuggestion("suggestion")
//模拟用户在搜索框输入查找
.prefix(xxprefix)
//跳过重复,不把重复的结果展示
.skipDuplicates(true)
//查多少条数据
.size(10)
));
//发起请求
SearchResponse xxresponse = client.search(xxrequest, RequestOptions.DEFAULT);
//解析结果
Suggest xxsuggest = xxresponse.getSuggest();
//根据'补全查询名称',获取补全结果
CompletionSuggestion xxsuggestions = xxsuggest.getSuggestion("zidingyizidongbuquanmingzi");
//获取xxsuggestions
List<CompletionSuggestion.Entry.Option> xxoptions = xxsuggestions.getOptions();
//准备好一个集合,当自动补全时,相关词就会在这个集合并返回给前端
List<String> xxlist = new ArrayList<>(xxoptions.size());
//遍历
for (CompletionSuggestion.Entry.Option xxoption : xxoptions) {
String text = xxoption.getText().toString();
//把自动补全时,查到的相关词放到我们准备好的集合里面
xxlist.add(text);
}
return xxlist;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
第三步: 在HotelController类添加如下
@GetMapping("suggestion")
public List<String> xxgetSuggestions(@RequestParam("key") String xxprefix){
return hotelService.xxgetSuggestions(xxprefix);
}第四步: 重新启动HotelDemoApplication引导类

第四步: 测试。查看自动补全查询是否在搜索框生效,,访问http://localhost:8089/

实用篇-ES-数据同步
1. 同步方案分析
elasticsearch中的酒店数据来自于mysql数据库,因此mysql数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与mysql之间的数据同步
在微服务中,负责酒店管理(操作mysql )的业务与负责酒店搜索(操作elasticsearch )的业务可能在两个不同的微服务上,数据同步该如何实现呢?
有如下三种解决方案
第一种解决方案: 同步调用。优点: 实现起来简单,粗暴。缺点: 业务耦合度高

第二种解决方案: 异步通知、优点: 低耦合,实现起来难度一般。缺点: 依赖mq的可靠性

第三种解决方案: 监听binlog。优点: 完全解除服务间耦合。开启binlog增加数据库负担、实现复杂度高

2. hm-导入酒店管理项目

上面学的所有es相关的案例,都是在hotel-demo项目中进行的,也就是黑马旅游项目,现在我们要增加一个新的项目叫hotel-admin,用于对mysql中的酒店数据增、删、改、查,然后es中的数据也要跟随改变,并且在hotel-demo项目中验证es的数据是否随mysql中的数据而改变
第一步: 下载hotel-admin项目。链接如下,下载下来是hotel-admin.zip压缩包,解压后是hotel-admin文件夹,用idea打开hotel-admin文件夹即可
https://cowtransfer.com/s/9ad22042a3cc48
第二步: 修改hotel-admin项目的application.yml文件,把数据库信息修改为自己的。运行HotelAdminApplication类,浏览器访问http://localhost:8099/

3. hm-声明队列和交换机
确保你的环境正常启动。注意,如果没有rabbitmq容器的话,需要去前面 '实用篇-RabbitMQ消息队列' 的 '1. 下载安装启动' 进行学习,才能做这节的操作
systemctl start docker # 启动docker服务
docker restart es #启动elasticsearch容器
docker restart mq #启动rabbitmq容器
#docker restart kibana #启动kibana容器,由于不需要在浏览器操作es,所以不需要启动kibana
测试rabbitmq是否正常,浏览器访问 http://你的ip:15672。例如如下

账号密码是你创建mq容器时设置的,如果你是跟着我笔记的话,那么账号是admain,密码是123456
增、改:对于es来说,都是往索引库里面插入数据,可以用同一种消息
删: 对于es来说,这也是一种消息
因此,这个案例的消息类型有两种,一类是增或改的消息,另一类是删除的消息,那么队列也就有两种,我们归纳为下面这个图

具体操作如下
第一步: 交换机和队列,一般都是在消费者项目做的,所以我们需要打开hotel-demo项目,在hotel-demo的pom.xml文件添加如下
<!--amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
第二步: 在hotel-demo项目的application.yml修改为如下
rabbitmq:
host: 192.168.200.231
port: 5672
username: admain
password: 123456
virtual-host: /
第三步: 在hotel-demo项目的constants目录新建MqConstants类,写入如下
package cn.itcast.hotel.constants;
/**
* @Author:豆浆
* @name :MqConstants
* @Date:2024/4/16 21:08
*/
public class MqConstants {
/*
* 交换机
* */
public final static String HOTEL_EXCHANGE="hotel.topic";
/*
* 监听新增和修改的队列
*
* */
public final static String HOTEL_INSERT_QUEUE="hotel.insertqueue";
/*
* 监听删除的队列
* */
public final static String HOTEL_DELETE_QUEUE="hotel.delete.queue";
/*
* 新增和修改的RoutingKey
* */
public final static String HOTEL_INSERT_KEY="hotel.insert.key";
/*
* 新增和修改的RoutingKey
* */
public final static String HOTEL_DELETE_KEY="hotel.delete.key";
}
第四步: 定义交换机、队列、RoutingKey的绑定关系,实现方式有两种(前面学AMQP时都学过),分别是'基于注解'和'基于bean',这里学'基于bean'的方式
在hotel-demo项目的cn.itcast.hotel目录新建config.MqConfig类,写入如下
package cn.itcast.hotel.config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.TreeMap;
/**
* @Author:豆浆
* @name :MqConfig
* @Date:2024/4/16 21:16
*/
@Configuration
public class MqConfig {
/*
* 交换机
* */
@Bean
public TopicExchange topicExchange(){
return new TopicExchange(MqConstants.HOTEL_EXCHANGE,true,false);
}
/*
* 队列
* */
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);
}
/*
* 队列
* */
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);
}
/*
* 绑定
* */
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
/*
* 绑定
* */
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
4. hm-消息发送
在完成上面那些操作之后,才可以接着下面的操作
第一步: 在hotel-admin项目的cn.itcast.hotel目录新建constants.MqConstants类(这个类跟hotel-demo项目的MqConstants类是一样的),写入如下
package cn.itcast.hotel.constants;
/**
* @Author:豆浆
* @name :MqConstants
* @Date:2024/4/16 21:08
*/
public class MqConstants {
/*
* 交换机
* */
public final static String HOTEL_EXCHANGE="hotel.topic";
/*
* 监听新增和修改的队列
*
* */
public final static String HOTEL_INSERT_QUEUE="hotel.insertqueue";
/*
* 监听删除的队列
* */
public final static String HOTEL_DELETE_QUEUE="hotel.delete.queue";
/*
* 新增和修改的RoutingKey
* */
public final static String HOTEL_INSERT_KEY="hotel.insert.key";
/*
* 新增和修改的RoutingKey
* */
public final static String HOTEL_DELETE_KEY="hotel.delete.key";
}
第二步: 在hotel-admin项目的pom.xml添加如下
<!--amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>第三步: 把hotel-admin项目的application.yml修改为如下
rabbitmq:
host: 192.168.200.231
port: 5672
username: admain
password: 123456
virtual-host: /第四步: 消息发送。把hotel-admin项目的HotelController类修改为如下。本身的代码是没有注释的,跟这节有关的代码才有注释
package cn.itcast.hotel.web;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.pojo.Hotel;
import cn.itcast.hotel.pojo.PageResult;
import cn.itcast.hotel.service.IHotelService;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
import java.security.InvalidParameterException;
@RestController
@RequestMapping("hotel")
public class HotelController {
@Autowired
private IHotelService hotelService;
@Autowired
private RabbitTemplate rabbitTemplate;
@GetMapping("/{id}")
public Hotel queryById(@PathVariable("id") Long id){
return hotelService.getById(id);
}
@GetMapping("/list")
public PageResult hotelList(
@RequestParam(value = "page", defaultValue = "1") Integer page,
@RequestParam(value = "size", defaultValue = "1") Integer size
){
Page<Hotel> result = hotelService.page(new Page<>(page, size));
return new PageResult(result.getTotal(), result.getRecords());
}
@PostMapping
public void saveHotel(@RequestBody Hotel hotel){
hotelService.save(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_INSERT_KEY,hotel.getId());
}
@PutMapping()
public void updateById(@RequestBody Hotel hotel){
if (hotel.getId() == null) {
throw new InvalidParameterException("id不能为空");
}
hotelService.updateById(hotel);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_INSERT_KEY,hotel.getId());
}
@DeleteMapping("/{id}")
public void deleteById(@PathVariable("id") Long id) {
hotelService.removeById(id);
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_DELETE_KEY,id);
}
}

5. hm-消息接收
紧接着来写消息接收的代码。hotel-demo是消费者,负责监听消息
第一步: 在hotel-demo项目的IHotelService接口添加如下
void kkdeleteById(Long id);
void kkinsertById(Long id);
第二步: 在hotel-demo项目的HotelService类添加如下
@Override
//根据id去es的索引库删除数据
public void kkdeleteById(Long id) {
try {
//准备Request对象,要删除哪个索引库,要删除的文档id
DeleteRequest wwrequest = new DeleteRequest("hotel", id.toString());
//发送请求
client.delete(wwrequest,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@Override
//根据id去es的索引库新增或修改数据
public void kkinsertById(Long id) {
try {
//先根据id查询酒店数据
Hotel hotel = getById(id);
//把上一行数据库查询出来的字段类型转为es的索引库的文档类型,才能往索引库里面新增文档
HotelDoc xxhotelDoc = new HotelDoc(hotel);
//准备Request对象,往哪个索引库添加文档,文档的id需要自定义
IndexRequest xxrequest = new IndexRequest("hotel").id(hotel.getId().toString());
//准备JSON文档.JSON.toJSONString()是com.alibaba.fastjson提供的API,用于把JSON转为String
xxrequest.source(JSON.toJSONString(xxhotelDoc), XContentType.JSON);
//发送请求
client.index(xxrequest,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
第三步: 在hotel-demo项目的cn.itcast.hotel目录新建mq.HotelListener类,写入如下
package cn.itcast.hotel.mq;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* @Author:豆浆
* @name :HotelListener
* @Date:2024/4/16 21:38
*/
@Component
public class HotelListener {
@Autowired
//注入写好的IHotelService接口
private IHotelService hotelService;
/**
* 监听数据库中的酒店的新增或修改
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_INSERT_QUEUE)
public void xxlistenHotelInsertOrUpdate(Long id){
//监听到数据库的数据被新增或修改时,就根据id去es的索引库也做一遍新增或修改
hotelService.kkinsertById(id);
}
/**
* 监听数据库中的酒店的删除
* @param id 酒店id
*/
@RabbitListener(queues = MqConstants.HOTEL_DELETE_QUEUE)
public void xxlistenHotelDelete(Long id){
//监听到数据库的数据被删除时,就根据id去es的索引库也做一遍删除
hotelService.kkdeleteById(id);
}
}
6. hm-测试数据同步功能
紧接着就来测试一下。hotel-admin生产者,hotel-demo消费者
第一步: 重启hotel-demo项目

第二步: 重启hotel-admin项目

第三步: 访问mq服务。



第四步: 找一条数据来验证

第五步: 去修改这条数据的价格

第六步: 看数据有没有同步更新

第七步: 删除数据库的某条数据,看看数据有没有同步更新。我们找一条数据来验证,然后从mysql删掉这条数据,再回来es看这条数据还在不在



实用篇-ES-es集群
1. 集群结构介绍

2. 搭建es集群
确保你的环境正常启动,docker里面暂时不要启动任何容器
systemctl start docker # 启动docker服务
第一步: 在Windows创建一个文件,叫docker-compose.yml,写入如下
version: '2.2'
services:
es01:
image: elasticsearch:7.12.1
container_name: es01
environment:
- node.name=es01
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es02,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data01:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- elastic
es02:
image: elasticsearch:7.12.1
container_name: es02
environment:
- node.name=es02
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es03
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data02:/usr/share/elasticsearch/data
ports:
- 9201:9200
networks:
- elastic
es03:
image: elasticsearch:7.12.1
container_name: es03
environment:
- node.name=es03
- cluster.name=es-docker-cluster
- discovery.seed_hosts=es01,es02
- cluster.initial_master_nodes=es01,es02,es03
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
volumes:
- data03:/usr/share/elasticsearch/data
networks:
- elastic
ports:
- 9202:9200
volumes:
data01:
driver: local
data02:
driver: local
data03:
driver: local
networks:
elastic:
driver: bridge
表示第一个es节点是9200,第二个节点是9201,第三个节点是9202,以端口号区分这三个节点

第二步: 把刚刚的docker-compose.yml文件上传到Centos7的 /root 目录下

第三步: 由于es运行需要修改一些linux系统权限,所以我们需要提前修改/etc/sysctl.conf文件
vi /etc/sysctl.conf
添加下面的内容:
vm.max_map_count=262144
然后执行命令,让配置生效:
sysctl -p
第四步: 正式搭建es集群。执行docker-compose命令,就会根据当前目录的docker-compose.yml文件自动创建和运行es集群,也就是创建出3个新的es容器
docker-compose up -d
3. 集群状态监控
kibana可以监控es集群,不过新版本需要依赖es的x-pack 功能,配置比较复杂。我们在下面使用的是 'cerebro'管理工具 来监控es集群状态
cerebro官方网址:https://github.com/lmenezes/cerebro
cerebro还有个优点,就是不需要kibana,就可以在cerebro可视化页面来操作DSL语句,例如创建索引库
cerebro下载链接:
https://cowtransfer.com/s/e812f5c0d8b743
下载下来是cerebro-0.9.4.zip压缩包,解压之后是cerebro-0.9.4文件夹,打开里面的bin目录,运行cerebro.bat文件即可


然后浏览器访问
http://192.168.200.231:9200/
其实就已经监控了我们的三个es节点,例如我们可以查看一下es01节点的监控信息

4. 创建索引库

2)在cerebro可视化监控页面进行创建索引库
我们要创建一个索引库,并把这个索引库分成三个片,放在es集群(es01、es02、es03)里面,然后每个片还要做一次备份(可以理解为复制),备份后形成的新片不能放在原来的节点上,提高数据安全



5. 集群职责及脑裂
elasticsearch中集群节点有不同的职责划分,如下表,在es中,节点的角色有四种。master中文意思是'主',eligible中文意思是'候选'
master eligible中文意思是候选主节点,master eligible在描述时说成eligible是可以的
| 节点类型 |
配置参数 |
默认值 |
节点职责 |
| master eligible |
node.master |
true |
备选主节点:主节点可以管理和记录集群状态、决定分片在哪个节点、处理创建和删除索引库的请求 |
| data |
node.data |
true |
数据节点:存储数据、搜索、聚合、CRUD |
| ingest |
node.ingest |
true |
数据存储之前的预处理 |
| coordinating |
上面3个参数都为false则为coordinating节点 |
无 |
路由请求到其它节点合并其它节点处理的结果,返回给用户 |

ES集群的脑裂
默认情况下,在ES集群中,每个节点都是master eligible节点,因此一旦master节点宕机,其它候选节点会选举一个成为主节点。
当主节点与其他节点网络故障时,可能发生脑裂问题

脑裂的解决
为了避免脑裂,需要要求选票大于等于 ( eligible节点数量 + 1 )/ 2 才能当选为主,因此eligible节点数量最好是奇数。对应配置项是discovery.zen.minimum_master_nodes,在es7.0以后,已经成为默认配置,因此一般不会发生脑裂问题
例如: 上面我们有三个eligible节点,那么其中某个节点要想成为主节点,就必须 ≥ 2票
缺陷: 当总节点是偶数时,仍然可能存在脑裂问题
6. 新增和查询文档
在ES集群的分布式存储中,当新增文档时,应该保存到不同分片,保证数据均衡,那么如何确定数据该存储到哪个分片呢。我们刚刚了解过ES集群的角色有 '主节点'、'数据节点'、'协调节点'。其中协调节点的作用是做请求路由,当增删改查节点到达 '请求节点' 时,'请求节点' 会把请求路由到 '数据节点'
确保你的环境正常启动
systemctl start docker # 启动docker服务
docker restart es01 #启动elasticsearch容器
docker restart es02
docker restart es03
打开集群状态监控的cerebro.bat,然后浏览器访问
http://localhost:9000
在Postman软件里面输入如下,注意9200是es01的端口,多插入几条数据
http://192.168.127.180:9200/huanfqc/_doc/1
{
"title":"我在索引库插入了一条id为1的数据"
}


查询,我们往9200端口,也就是es01插入了三条数据,现在来查一下
http://192.168.127.180:9200/huanfqc/_search


我们还可以查一下,文档在节点中的哪个分片
http://192.168.127.180:9202/huanfqc/_search
{
"explain":true,
"query": {
"match_all": {}
}
}
那么我们插入的文档在节点中的哪个分片,是什么决定的呢,由两个因素决定,文档id和分片数量,公式如下
文档在节点中的哪个分片 = hash(_routing) % number_of_shards
# hash(): 对括号内的值进行哈希运算
# _routing: 文档的id
# %: 取模
# number_of_shards: 分片数量,注意索引库一旦创建,分片数量不能修改
分片是我们在创建索引库时指定的,当时创建huanfqc索引库时,我指定的分片数量是3
新增文档的流程如下图

查询文档的流程如下图


总结: 我们往某索引库插入文档(也就是数据)后,每一个节点都会有这条文档,文档是在节点的分片上
7. 故障转移
这个是ES内部自己解决的,不是我们代码控制或者请求控制的,我们唯一能做的就是创建索引库时,指定分片数量、备份数量。所以下面学的是理论
集群的master节点会监控集群中的节点状态,如果发现有节点宕机,会立即将宕机节点的分片数据迁移到其它节点,确保数据安全
故障前,非常健康

故障时,第一个节点挂了

故障解决: 剩下两个节点竞选出主节点,例如node02成为了新的主节点。然后node02就会去看一下已经挂了的node01节点,看有什么分片就把什么分片拿过来,确保任何一个分片都至少有两份(深色的是主分片、浅色的是备份分片),把分片重新备份好后,集群状态就如下图

如果node01恢复了,那么node01就不是主节点了,主节点是node02。node02检测到node01恢复了,那么就会把属于node01的分片给回node01,如下图
 文章来源:https://www.toymoban.com/news/detail-855609.html
文章来源:https://www.toymoban.com/news/detail-855609.html
主节点会实时监控集群里面的分片、节点状态,将故障节点上的分片转移到正常节点上,确保数据安全
如果故障节点恢复了,主节点会把分片重新恢复成原来的节点位置文章来源地址https://www.toymoban.com/news/detail-855609.html
到了这里,关于Elasticsearch分布式搜索的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!