前言
思维链,是一系列中间推理步骤,可以显著提高大语言模型执行复杂推理的能力。一、思维链介绍
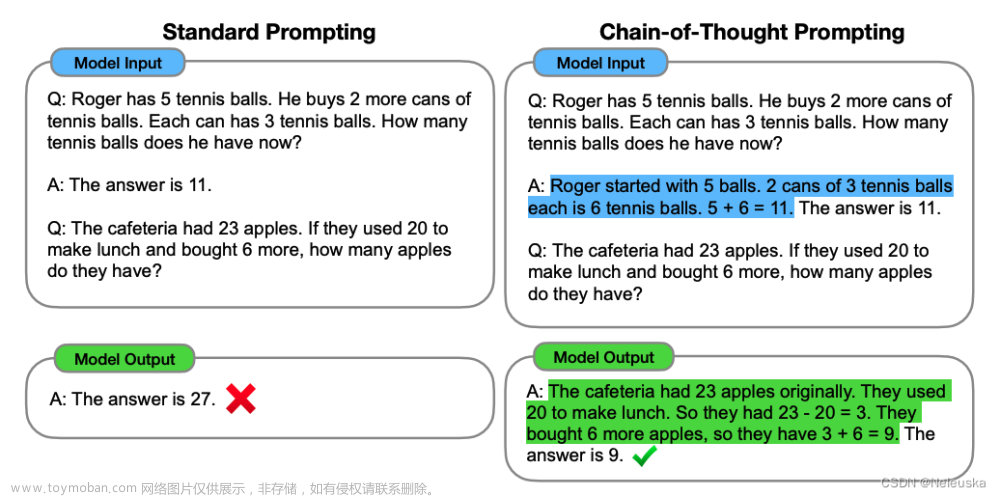
思维链:一种简单的提示方法,通过一系列的中间推理步骤,可以大大提高大语言模型执行复杂推理的能力。下图为使用标准提示词和使用思维链提示词的输出的区别:

与传统Prompt的区别: 传统Prompt的流程是直接从输入到输出的映射,而Cot则是输入——思维链——输出。
一个完整的包含Cot的Prompt往往由指令、逻辑依据、示例三部分组成。一般来说,指令用于描述问题并且告知大模型的输出格式;逻辑依据指的是Cot的推理过程(一般包含问题的解决方案、中间推理步骤以及外部知识);示例指的是以少样本的方式为大模型提供输入输出对的基本格式,每一个示例都包含:问题、推理过程与答案。以下为更详细的介绍。
下图为COT实例:《输入——思维链——输出》
1-1、指令
指令 (Instruction)
- 作用:明确告知模型需要解决的问题或执行的任务,以及期望的输出格式。
- 重要性:指令帮助模型理解任务的具体需求,确保输出的相关性和准确性。
示例:
问题:解释什么是光合作用?
指令:简要描述光合作用的过程,并列出它的主要作用。
1-2、逻辑依据
逻辑依据 (Rationale)
- 作用:包括解决问题的中间步骤、相关知识的引入或理由的阐述。
- 重要性:逻辑依据帮助模型展现推理过程,使答案更具解释性和可靠性。
示例:
问题:解释什么是光合作用?
逻辑依据:光合作用是植物、藻类和某些细菌使用阳光将二氧化碳和水转化为氧气和葡萄糖的过程。这是一个复杂的多步骤过程,涉及到光反应和暗反应等阶段,主要作用是产生氧气和为生物提供能量。
1-3、示例
示例 (Exemplars)
作用:提供具体的问题、推理过程和答案实例,作为模型处理类似问题的参考。
重要性:示例可以帮助模型学习如何格式化其回答,理解问题的深层含义,以及如何引入适当的推理来支持其结论。
示例:
问题:解释什么是蒸馏?
推理过程:蒸馏是一种分离混合物的技术,常用于分离液体或提纯物质。在这个过程中,混合物加热至沸点,使最易挥发的组分蒸发,然后通过冷凝再将其分离出来。
答案:蒸馏是利用物质之间沸点的差异来分离它们的过程。
二、Cot一般分类
以是否包含示例为区分,可以将Cot分为Zero-Shot-CoT 与 Few-Shot-CoT。如下图所示:

2-1、Zero-Shot-CoT
Zero-Shot-CoT (零样本CoT)
- 定义:在这种模式下,没有提供具体的示例来引导模型的行为。指令通常包括“Let’s think step by step”这样的语句来激励模型展开逐步推理。(进阶:Let’s first understand the problem and devise a plan to solve the problem. Then, let’s carry out the plan and solve the problem step by step)
- 应用:Zero-Shot-CoT适用于那些模型已经有足够知识理解和解答的情况,不需要通过额外的示例来学习如何回答。
- 优点:能够快速部署,无需额外准备示例,节省时间。
- 局限:可能不如Few-Shot-CoT准确,特别是在处理非常复杂或专业性强的问题时。
案例如下所示:
2-2、Few-Shot-CoT
Few-Shot-CoT (少样本CoT)
- 定义:在指令中添加具体的示例(案例),这些示例显示了问题、推理过程和答案。这样做可以让模型模仿这些示例来提高解决问题的能力。
- 应用:Few-Shot-CoT适用于需要模型理解特定格式或复杂问题的场景,特别是在模型原本不太可能准确回答的领域。
- 优点:通过提供具体示例,模型可以学习特定的回答风格和推理方法,通常能够产生更准确和相关的输出。
- 局限:需要花费更多的时间来准备有效的示例,且依赖于这些示例的质量。
案例如下所示:

三、Cot的好处&缺陷&适用
3-1、Cot的好处
Cot的具体优点如下:
- 增强大模型的推理能力: 通过将复杂问题分为多个子问题,显著提高了模型的推理能力。
- 增强了大模型的可解释性: 相比于没有使用思维链,Cot可以向我们展示过程,让我们可以知道大模型的执行流程到底是怎样的,增加了可解释性。
- 增强了大模型的可控性: 通过让大模型一步一步输出步骤,我们通过这些步骤的呈现可以对大模型问题求解的过程施加更大的影响,避免大模型成为无法控制的“完全黑盒”;
3-2、Cot的缺陷
Cot的缺陷如下:
- 模型的规模太小会导致Cot失效
- 只有对复杂任务才是有用的。
- 示例不正确会带偏大模型。
如下图所示(使用Cot的PaLM 540B模型在GSM8K基准上表现出极高的性能):
3-3、Cot的适用
Cot的适用场景如下:
- 需要使用大模型,规模太小的不适用(20B以下)
- 复杂任务场景,如编程
- 增加模型参数无法使模型性能得到提升。
- 模型的训练数据针对于任务问题有较强的关联性。
四、变体
4-1、自我验证(self-consistency checking)
自我验证(self-consistency checking)是Chain of Thought (CoT) 推理中的一个重要概念。这种方法不仅在推理过程中寻找问题的答案,而且还要检查和验证这些推理过程的逻辑一致性和正确性。自我验证的目的是提高答案的可靠性和准确性,确保模型在解答复杂问题时能够自我纠正潜在的错误或不一致之处。
如何实施自我验证
在CoT框架中,自我验证通常涉及以下几个步骤:
- 推理生成:首先,生成一个详细的推理过程,这通常包括对问题的分析、相关信息的整合以及逐步推导出答案的逻辑链。
- 验证步骤:在得到初步答案之后,模型会重新审视整个推理过程,检查是否存在逻辑断裂、信息错误或不一致的地方。
- 调整和改进:基于自我验证的结果,模型可能需要调整其推理链。这可以涉及修正错误的事实信息、重新评估逻辑关系或添加缺失的逻辑步骤。
- 最终输出:完成自我验证和必要的调整后,模型输出最终的、经过验证的答案。
应用场景
- 自我验证特别适用于需要高度准确性的应用场景,如医学诊断、法律推理、科技问题解答等领域。在这些领域,错误的信息或推理可能导致严重的后果。通过自我验证,模型能够提供更加可靠和精确的答案。
self-consistency checking 案例如下图所示:

参考文章:
Chain-of-Thought Prompting Elicits Reasoning
in Large Language Models论文地址.
一文读懂:大模型思维链 CoT(Chain of Thought)文章来源:https://www.toymoban.com/news/detail-855813.html
总结
那女孩对我说,说我保护她的梦💤文章来源地址https://www.toymoban.com/news/detail-855813.html
到了这里,关于《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》【大模型思维链】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!