@article{wang2022swinfuse,
title={SwinFuse: A residual swin transformer fusion network for infrared and visible images},
author={Wang, Zhishe and Chen, Yanlin and Shao, Wenyu and Li, Hui and Zhang, Lei},
journal={IEEE Transactions on Instrumentation and Measurement},
volume={71},
pages={1–12},
year={2022},
publisher={IEEE}
}
论文级别:SCI A2/Q1
影响因子:5.6
📖[论文下载地址]
💽[代码下载地址]
📖论文解读
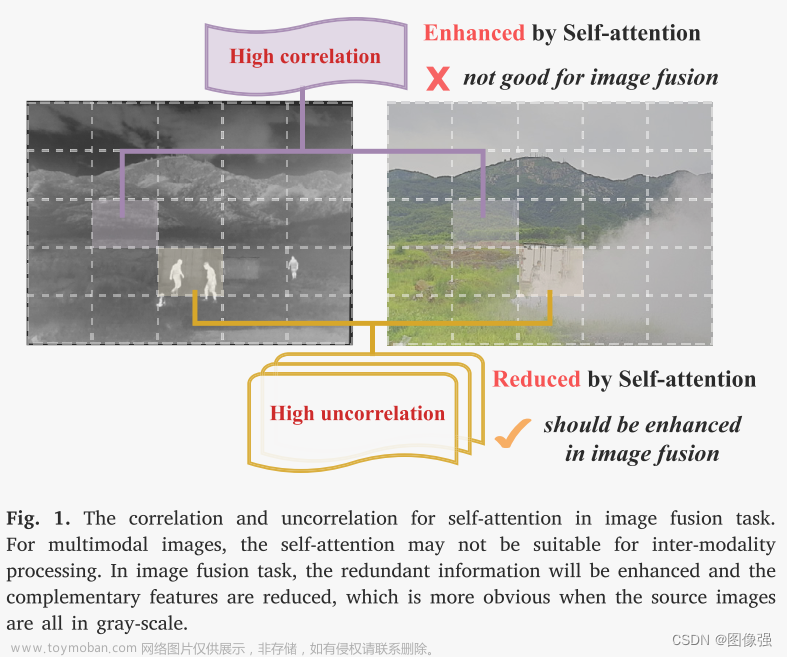
卷积运算是图像与卷积核之间内容无关的交互,可能会丢失上下文信息
因此作者提出了SwinFuse(Residual Swin Transformer Fusion Network),该模型包括三个部分:全局特征提取,融合层和特征重构。
- 使用纯Transformer构建了一个完全注意力编码骨干网络来建模远程依赖
- 设计了基于序列矩阵L1范数的特征融合策略
🔑关键词
image fusion, Swin Transformer, self-attention mechanism, feature normalization, deep learning
图像融合,Swin Transformer, 自注意力机制,特征归一化,深度学习
💭核心思想
使用Swin Transformer提取全局特征,并设计了基于行向量和列向量维度的融合策略
参考链接
[什么是图像融合?(一看就通,通俗易懂)]
🪢网络结构
作者提出的网络结构如下所示。SwinFuse主要由三部分组成:全局特征提取、融合层和特征重构。
🪢overview
给定输入
I
l
∈
R
H
×
W
×
C
i
n
{I^l} \in {R^{H \times W \times {C_{in}}}}
Il∈RH×W×Cin,HWC即高宽通道,
l
=
v
i
s
l = vis
l=vis和
l
=
i
r
l = ir
l=ir分别代表可见光图像和红外图像。
首先,使用1×1卷积核的卷积层进行位置编码,并将输入通道
C
i
n
C_{in}
Cin转换为
C
C
C。初始特征
Φ
l
{\Phi ^l}
Φl为:
Φ
l
=
H
p
o
s
(
I
l
)
{\Phi ^l} = {H_{pos}}({I^l})
Φl=Hpos(Il)中,
H
p
o
s
H_{pos}
Hpos代表位置编码,输出通道数C被设置为96.
然后,将初始特征
Φ
l
{\Phi ^l}
Φl转化为序列向量
Φ
S
V
l
∈
R
M
N
×
C
\Phi _{SV}^l \in {R^{MN{\rm{ \times C}}}}
ΦSVl∈RMN×C,并使用残差Swin Transformer块(residual Swin Transformer blocks,RSTBs)提取全局特征
Φ
G
F
l
∈
R
M
N
×
C
\Phi _{GF}^l \in {R^{MN{\rm{ \times C}}}}
ΦGFl∈RMN×C:
H
R
S
T
B
m
H_{RSTB_m}
HRSTBm代表第m个RSTB。
接下来,使用基于L1范式的融合层,从行、列向量维度获得融合全局特征
Φ
F
l
∈
R
M
N
×
C
\Phi _{F}^l \in {R^{MN{\rm{ \times C}}}}
ΦFl∈RMN×C:
H
N
o
r
m
H_{Norm}
HNorm代表融合操作。
最后,将融合全局特征的维度从
R
M
N
×
C
R^{MN×C}
RMN×C转换为
R
M
×
N
×
C
R^{M×N×C}
RM×N×C,并使用卷积层重构融合图像
I
F
I_F
IF:
H
C
o
n
v
H_{Conv}
HConv代表特征重构,该层使用了1×1卷积核,padding为0,还有一个tanh激活函数。
🪢RSTB
给定一个输入序列向量
Φ
m
,
0
l
{\Phi ^l_{m,0}}
Φm,0l,使用n个Swin Transformer提取中间全局特征
Φ
m
,
n
−
l
{\Phi ^l_{m,n-}}
Φm,n−l,RSTB最终的输出为:
H
S
T
L
m
,
n
H_{STL_{m,n}}
HSTLm,n代表第n个Swin Transformer层。
在STL中,首先使用N×N的滑动窗口,将输入划分为不重叠的
H
W
N
2
\frac{HW}{N^2}
N2HW局部窗口并计算其局部注意力。
对于局部窗口
Φ
z
\Phi_z
Φz,QKV计算如下:
W
Q
、
W
K
、
W
V
W_Q、W_K、W_V
WQ、WK、WV均为可学习参数,d使(Q, K)的维度。序列矩阵自注意力机制计算如下:
p是位置编码的可学习参数。
随后,Swin Transformer再次计算移动窗口的标准多头注意力(multi-head self-attention, MSA)。STL由W-MSA和SW-MSA构成,LayerNorm在每个MSA和MLP前面,并且使用了残差连接。
🪢融合策略
作者设计了一种基于L1范数的红外-可见光图像序列矩阵融合策略,从行和列向量维度测量活动水平。如下图所示。
对于两种源图像各自的全局特征
Φ
G
F
i
r
(
i
,
j
)
\Phi _{GF}^{ir}\left( {i,j} \right)
ΦGFir(i,j)和
Φ
G
F
v
i
s
(
i
,
j
)
\Phi _{GF}^{vis}\left( {i,j} \right)
ΦGFvis(i,j),首先使用L1范数测量其行向量权重,然后使用softmax获得活动水平
φ
r
o
w
i
r
(
i
)
\varphi _{row}^{ir}\left( i \right)
φrowir(i)和
φ
r
o
w
v
i
s
(
i
)
\varphi _{row}^{vis}\left( i \right)
φrowvis(i):

然后直接将活动水平与对应的全局特征相乘,从行向量维度得到融合全局特征
Φ
r
o
w
F
(
i
,
j
)
\Phi _{row}^{F}\left( i,j \right)
ΦrowF(i,j):
同理,计算列向量:

最后,使用逐元素相加得到最终的融合全局特征:
注意,融合层只在测试时被保留,在训练阶段被移除。
📉损失函数


🔢数据集
- 训练MS-COCO
- 测试 TNO Roadscene OTCBVS
图像融合数据集链接
[图像融合常用数据集整理]
🎢训练设置
🔬实验
📏评价指标
- SF, SD, MI, MS_SSIM, FMI_W and SCD
参考资料
✨✨✨强烈推荐必看博客 [图像融合定量指标分析]
🥅Baseline
- MDLatLRR、IFCNN、DenseFuse、RFN-Nest、fusongan、GANMcC、PMGI、SEDRFuse、Res2Fusion
参考资料
[图像融合论文baseline及其网络模型]
🔬实验结果






更多实验结果及分析可以查看原文:
📖[论文下载地址]
💽[代码下载地址]
🚀传送门
📑图像融合相关论文阅读笔记
📑[SwinFusion: Cross-domain Long-range Learning for General Image Fusion via Swin Transformer]
📑[(MFEIF)Learning a Deep Multi-Scale Feature Ensemble and an Edge-Attention Guidance for Image Fusion]
📑[DenseFuse: A fusion approach to infrared and visible images]
📑[DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pair]
📑[GANMcC: A Generative Adversarial Network With Multiclassification Constraints for IVIF]
📑[DIDFuse: Deep Image Decomposition for Infrared and Visible Image Fusion]
📑[IFCNN: A general image fusion framework based on convolutional neural network]
📑[(PMGI) Rethinking the image fusion: A fast unified image fusion network based on proportional maintenance of gradient and intensity]
📑[SDNet: A Versatile Squeeze-and-Decomposition Network for Real-Time Image Fusion]
📑[DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion]
📑[FusionGAN: A generative adversarial network for infrared and visible image fusion]
📑[PIAFusion: A progressive infrared and visible image fusion network based on illumination aw]
📑[CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition for Multi-Modality Image Fusion]
📑[U2Fusion: A Unified Unsupervised Image Fusion Network]
📑综述[Visible and Infrared Image Fusion Using Deep Learning]
📚图像融合论文baseline总结
📚[图像融合论文baseline及其网络模型]
📑其他论文
📑[3D目标检测综述:Multi-Modal 3D Object Detection in Autonomous Driving:A Survey]
🎈其他总结
🎈[CVPR2023、ICCV2023论文题目汇总及词频统计]
✨精品文章总结
✨[图像融合论文及代码整理最全大合集]
✨[图像融合常用数据集整理]文章来源:https://www.toymoban.com/news/detail-855849.html
如有疑问可联系:420269520@qq.com;
码字不易,【关注,收藏,点赞】一键三连是我持续更新的动力,祝各位早发paper,顺利毕业~文章来源地址https://www.toymoban.com/news/detail-855849.html
到了这里,关于图像融合论文阅读:SwinFuse: A Residual Swin Transformer Fusion Network for Infrared and Visible Images的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!