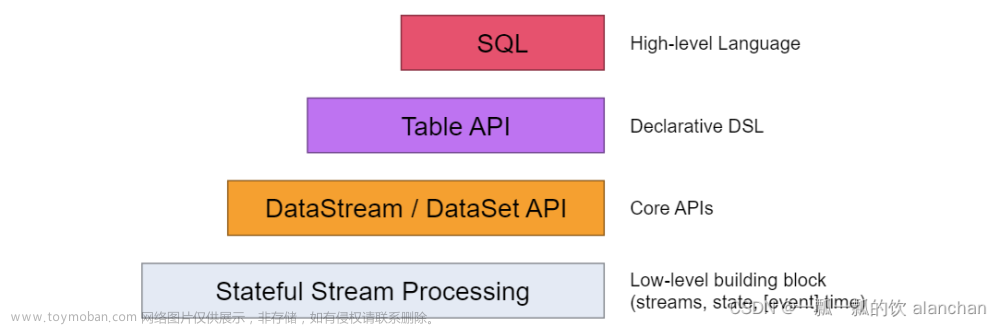
Flink是一种一站式处理的框架,既可以进行批处理(DataSet),也可以进行流处理(DataStream)
将Flink的算子分为两大类:DataSet 和 DataStream
DataSet
1. Source源算子
1.1 fromCollection
从本地集合读取数据
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("1,张三", "2,李四", "3,王五", "4,赵六")
)1.2 readTextFile
从文件中读取
val textDataSet: DataSet[String] = env.readTextFile("/data/a.txt")1.3 readTextFile 遍历目录
对一个文件目录内的所有文件,包括所有子目录中的所有文件的遍历访问方式
val parameters = new Configuration
// recursive.file.enumeration 开启递归
parameters.setBoolean("recursive.file.enumeration", true)
val file = env.readTextFile("/data").withParameters(parameters)1.4 readTextFile 读取压缩文件
对于以下压缩类型,不需要指定任何额外的inputformat方法,flink可以自动识别并且解压。但是,压缩文件可能不会并行读取,可能是顺序读取的,这样可能会影响作业的可伸缩性
val file = env.readTextFile("/data/file.gz")2.Transform转换算子
因为Transform算子基于Source算子操作,所以首先构建Flink执行环境及Source算子
val env = ExecutionEnvironment.getExecutionEnvironment
val textDataSet: DataSet[String] = env.fromCollection(
List("张三,1", "李四,2", "王五,3", "张三,4")
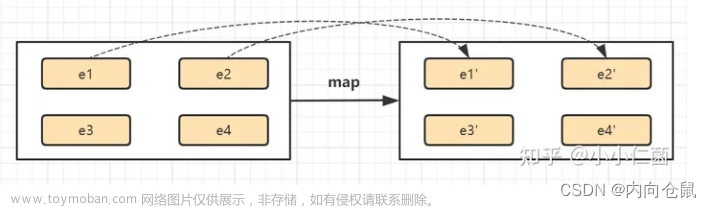
)2.1 map
将DataSet中的每一个元素转换为另一个元素
- 底层为MapFunction算子。通过调用map函数,对每个元素执行操作。
- 常用于数据清洗、计算和转换等。
// 使用map将List转换为一个Scala的样例类
case class User(name: String, id: String)
val userDataSet: DataSet[User] = textDataSet.map {
text =>
val fieldArr = text.split(",")
User(fieldArr(0), fieldArr(1))
}
userDataSet.print()2.2 flatmap
将DataSet中的每一个元素转换为n个元素

// 使用flatMap操作,将集合中的数据:
// 根据第一个元素,进行分组
// 根据第二个元素,进行聚合求值
val result = textDataSet.flatMap(line => line)
.groupBy(0) // 根据第一个元素,进行分组
.sum(1) // 根据第二个元素,进行聚合求值
result.print()2.3 mapPartition
将一个分区中的元素转换为另一个元素

// 使用mapPartition操作,将List转换为一个scala的样例类
case class User(name: String, id: String)
val result: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
result.print()2.4 filter
过滤出来一些符合条件的数据
val source: DataSet[String] = env.fromElements("java", "scala", "java")
val filter:DataSet[String] = source.filter(line => line.contains("java"))//过滤出带java的数据
filter.print()2.5 keyBy算子
根据指定key对DataStream数据集分区
相同key值的数据归并到同一分区

val inputStream = env.fromElements(
("aa", 11), ("aa", 22), ("bb", 33)
)
// 根据第一个字段作为key分区
// 转换为KeyedStream[(String, String), Tuple]
val keyedStream: inputStream.keyBy(0)2.6 reduce
将一个DataSet或者一个group来进行聚合计算,最终聚合成一个元素
- 根据key分区聚合形成KeyedStream
- 支持运算符和自定义reduceFunc函数

// 使用 fromElements 构建数据源
val source = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 使用map转换成DataSet元组
val mapData: DataSet[(String, Int)] = source.map(line => line)
// 根据首个元素分组
val groupData = mapData.groupBy(_._1)
// 使用reduce聚合
val reduceData = groupData.reduce((x, y) => (x._1, x._2 + y._2))
// 打印测试
reduceData.print()自定义Reduce函数,需要实现匿名类。
val reduceDataStream = keyedStream.reeduce(
new ReduceFunction[(String, Int)] {
override def reduce(t1: (String,Int),
t2: (String, Int)): (String, Int) = {
(t1._1, t1._2 + t2._2)
}
}
)5.7 reduceGroup
将一个DataSet或者一个group聚合成一个或多个元素
// 使用 fromElements 构建数据源
val source: DataSet[(String, Int)] = env.fromElements(("java", 1), ("scala", 1), ("java", 1))
// 根据首个元素分组
val groupData = source.groupBy(_._1)
// 使用reduceGroup聚合
val result: DataSet[(String, Int)] = groupData.reduceGroup {
(in: Iterator[(String, Int)], out: Collector[(String, Int)]) =>
val tuple = in.reduce((x, y) => (x._1, x._2 + y._2))
out.collect(tuple)
}
// 打印测试5.8 minBy和maxBy
选择有最大或最小值的元素
// 使用minBy操作,求List中每个人的最小值
// List("张三,1", "李四,2", "王五,3", "张三,4")
case class User(name: String, id: String)
// 将List转换为一个scala的样例类
val text: DataSet[User] = textDataSet.mapPartition(line => {
line.map(index => User(index._1, index._2))
})
val result = text
.groupBy(0) // 按照姓名分组
.minBy(1) // 每个人的最小值5.9 Aggregate
在数据集上进行聚合求最值(最大 最小)
val data = new mutable.MutableList[(Int, String, Double)]
data.+=((1, "yuwen", 89.0))
data.+=((2, "shuxue", 92.2))
data.+=((3, "yuwen", 89.99))
// 使用 fromElements 构建数据源
val input: DataSet[(Int, String, Double)] = env.fromCollection(data)
// 使用group执行分组操作
val value = input.groupBy(1)
// 使用aggregate求最大值元素
.aggregate(Aggregations.MAX, 2)
// 打印测试
value.print() 只能用在元组上
注意:
要使用aggregate,只能使用字段索引名或索引名称来进行分组groupBy(0),否则会报一下错误:
Exception in thread "main" java.lang.UnsupportedOperationException: Aggregate does not support grouping with KeySelector functions, yet.
5.10 distinct
去除重复数据
// 数据源使用上一题的
// 使用distinct操作,根据科目去除集合中重复的元组数据
val value: DataSet[(Int, String, Double)] = input.distinct(1)
value.print()5.11 join
将两个DataSet以一定的条件连接到一起,形成新的DataSet
// s1 和 s2 数据集格式如下:
// DataSet[(Int, String,String, Double)]
val joinData = s1.join(s2) // s1数据集 join s2数据集
.where(0).equalTo(0) { // join的条件
(s1, s2) => (s1._1, s1._2, s2._2, s1._3)
}5.12 leftOuterJoin
左外连接,左边的Dataset中的每一个元素,去连接右边的元素
此外还有:
rightOuterJoin:右外连接,左边的Dataset中的每一个元素,去连接左边的元素
fullOuterJoin:全外连接,左右两边的元素,全部连接
下面以 leftOuterJoin 进行示例:
val data1 = ListBuffer[Tuple2[Int,String]]()
data1.append((1,"zhangsan"))
data1.append((2,"lisi"))
data1.append((3,"wangwu"))
data1.append((4,"zhaoliu"))
val data2 = ListBuffer[Tuple2[Int,String]]()
data2.append((1,"beijing"))
data2.append((2,"shanghai"))
data2.append((4,"guangzhou"))
val text1 = env.fromCollection(data1)
val text2 = env.fromCollection(data2)
text1.leftOuterJoin(text2).where(0).equalTo(0).apply((first,second)=>{
if(second==null){
(first._1,first._2,"null")
}else{
(first._1,first._2,second._2)
}
}).print()5.13 cross
交叉操作,通过形成这个数据集和其他数据集的笛卡尔积,创建一个新的数据集
val cross = input1.cross(input2){
(input1 , input2) => (input1._1,input1._2,input1._3,input2._2)
}
cross.print()5.14 union
将两个数据集合并,但不去重
val unionData: DataSet[String] = elements1.union(elements2).union(elements3)
// 去除重复数据
val value = unionData.distinct(line => line)5.15 rebalance
解决数据倾斜,保证每个机器完成计算的时间相近
将数据均匀分配到每个机器上执行
// 使用rebalance操作,避免数据倾斜
val rebalance = filterData.rebalance()5.16 partitionByHash
按指定的key进行hash分区
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
val collection = env.fromCollection(data)
val unique = collection.partitionByHash(1).mapPartition{
line =>
line.map(x => (x._1 , x._2 , x._3))
}
unique.writeAsText("hashPartition", WriteMode.NO_OVERWRITE)
env.execute()5.17partitionByRange
根据指定的key对数据集进行范围分区
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val collection = env.fromCollection(data)
val unique = collection.partitionByRange(x => x._1).mapPartition(line => line.map{
x=>
(x._1 , x._2 , x._3)
})
unique.writeAsText("rangePartition", WriteMode.OVERWRITE)
env.execute()5.18 sortPatition
根据指定的字段值进行分区的排序
val data = new mutable.MutableList[(Int, Long, String)]
data.+=((1, 1L, "Hi"))
data.+=((2, 2L, "Hello"))
data.+=((3, 2L, "Hello world"))
data.+=((4, 3L, "Hello world, how are you?"))
val ds = env.fromCollection(data)
val result = ds
.map { x => x }.setParallelism(2)
.sortPartition(1, Order.DESCENDING)//第一个参数代表按照哪个字段进行分区
.mapPartition(line => line)
.collect()
println(result)3.Sink输出算子
3.1 collect
将数据输出到本地集合
result.collect()3.2 writeAsText
将数据输出到文件
Flink支持多种存储设备上的文件,包括本地文件,hdfs文件等文章来源:https://www.toymoban.com/news/detail-855981.html
Flink支持多种文件的存储格式,包括text文件,CSV文件等文章来源地址https://www.toymoban.com/news/detail-855981.html
// 将数据写入本地文件
result.writeAsText("/data/a", WriteMode.OVERWRITE)
// 将数据写入HDFS
result.writeAsText("hdfs://node01:9000/data/a", WriteMode.OVERWRITE)到了这里,关于Flink源算子、转换算子和输出算子(DataSet)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[flink 实时流基础]源算子和转换算子](https://imgs.yssmx.com/Uploads/2024/04/847286-1.png)