本文算是一个比较完整的关于在 C/C++ 中测量一个函数或者功能的总结,最后会演示三种方法的对比。
最常用的clock()
最常用的测量方法是使用clock()来记录两个 CPU 时间点clock_t,然后做差。这个方法的好处在于非常简单易写,如下(第一行是为说明需要导入哪个库):
#include <time.h>
.....
clock_t begin = clock();
...需要被测量的代码
clock_t end = clock();
int duration = (end - begin)/CLOCKS_PER_SEC;
需要注意 3 点:
-
CLOCKS_PER_SEC在 macOS 上是 1000000,也就是说(end - begin)的单位是微秒,所以要除以CLOCKS_PER_SEC。 - 不同平台的
clock_t类型是不一样的,有些平台是整数型,有些是使用浮点型。如果是浮点型的话,CLOCKS_PER_SEC或许可以不用写,还是要看time.h的相关内容。 - 这个方法中的“clock”一词表示的是时钟频率,而不是时间。早期的计算机是固定频率的(现在的一些计算器或者单片机其实也是固定频率的),这个方法就是诞生于那个时间的。
这种方法最大的弊端就是它测量是 CPU 运行时间,准确的说是该进程使用 CPU 的时间。这就导致了对于非 CPU 密集型程序来说,这个结果可能不是那么精确。当然导致的最大的问题是并行计算程序得到的时间完全不对,而且不能简单地使用核心数计算得到正确的时间。
因为这个方法是将多个 CPU 的运行时间加在一起了,串行计算的程序完全没有问题,但是并行计算的话,CPU 使用率一般不会达到或接近核心数*100%,因为计算机上还有其他任务也需要 CPU。比如说如果串行计算的程序使用率一般在 99% 左右,获取时间为 30 秒,但是对于 6 核的设备上运行的并行计算程序的话,CPU 使用率达到 570% 就很不错了,获取的时间可能为 27 秒,而实际上只用了 5 秒。
这是我在使用 ISPC 编写并行计算程序的时候发现的,所以我想寻找到新的方案,于是我发现了下一个方法。
timespec
timespec是一个简单的日历时间或者时间流逝。通过使用日历时间可以解决上一节中无法测量并行程序的实际运行时间的问题。但是“简单”这点的表现为整数时间,也就是说最小的时间精度是秒,而不是上一种方法中的微秒,不过这对于复杂函数或程序的测试来说没啥问题,毕竟 30 分钟和 31 分钟的性能差距不过 3.22%。
方法如下(第一行是为说明需要导入哪个库):
#include <time.h>
time_t begin = time(NULL);
...需要被测量的代码
time_t end = time(NULL);
int duration = (end - begin);
可以看到比上一种还要简单。
但是对于一些小型的测试来说,这个方法又不太行,因为整数带来的误差太大了,比如说 0.6 秒是 1.8 秒性能的三倍,但是在整数上只为 2 倍甚至是 1 倍(为什么有这个“甚至”等会演示可以看到),所以还是需要一个更精确时间测量方法,这个方法不光要适应并行计算,还要有一定的精度。
clock_gettime()
clock_gettime()可以完美的符合要求,但是使用上有点复杂。
2024年4月15更新
感谢评论提醒,我之前只实验了 Linux 和 Mac 这种类 Unix 系统,没考虑到 Windows。也就没主要到clock_gettime()再 Windows 上不可用,所以忙完之后又研究了一下:Windows的高精度时间测量请见:
《Windows上的类似clock_gettime(CLOCK_MONOTONIC)的高精度测量时间函数》
clock_gettime()是我从文档的下面发现的。一开始我找到的是gettimeofday(),然后我去看了一下 IEEE 标准的文档 https://pubs.opengroup.org/onlinepubs/9699919799/functions/gettimeofday.html,发现在“FUTURE DIRECTIONS(未来方向)”这一栏表示gettimeofday()可能未来会被废弃;在“APPLICATION USAGE(应用使用)”这一栏表示应用应该使用clock_gettime()而不是gettimeofday。这必须得使用clock_gettime()了。

clock_gettime()的复杂之处在于太精确了。先来看看使用方法(第一行是为说明需要导入哪个库):
#include <time.h>
struct timespec start;
clock_gettime(CLOCK_MONOTONIC, &start);
...需要被测量的代码
struct timespec end;
clock_gettime(CLOCK_MONOTONIC, &end);
double duration = (double)(end.tv_nsec-start.tv_nsec)/((double) 1e9) + (double)(end.tv_sec-start.tv_sec);
clock_gettime()的第一个参数有两种:
-
CLOCK_MONOTONIC,这个值是从系统启动开始一直运行的,一直连续的不跳跃的(除非手动改了),如果你要进行严肃的测量任务,那么请使用这个参数; -
CLOCK_REALTIME表示系统层面的实时时间,这个要比CLOCK_REALTIME精度小一些,所以更快一些,如果你只是进行简单的测量,那么使用这个参数就行。
你可能会好奇“一直连续的不跳跃的”是什么意思,这里解释一下:
长时间不用计算机联网的时候,主板电池没电了或者没有外置的计时器,那么开机之后时间不一样,这时候需要联网同步时间。这是一个很极端的情况,举这个例子是为了让你知道计算机是通过外置或内置的时钟计时的,如果断电那么就会停止计时,甚至归零,而且这个时钟精度也没有那么高。
当我们在实际使用的时候,由于精度问题,偶尔也会出现时间不准的情况(这个不准可能我们人感受不到,比如说就差几纳秒),这时候系统会自动更新时间,来保证时间是标准时间。但是这就导致一个问题:如果这时候我们刚好在测量程序运行的时间,系统自动更新了时间,那么可能就会导致运行时间为负数,这就搞笑了。这种情况下,时间就是不连续、跳跃的。
可以看到计算运行时间的代码,也就是时间差的表达式长了很多,是因为clock_gettime()获取的时间分为两部分:秒和纳秒(在某论坛上有人指出在曾经的 Mac OS X 上这里是微秒,不确定,不过现在也是纳秒了)。秒是int很简单的,但是纳秒用的是long int,这就涉及到转换的问题了。所以就需要分别计算两个部分,转换合成。
实际演示(三种方法的对比)
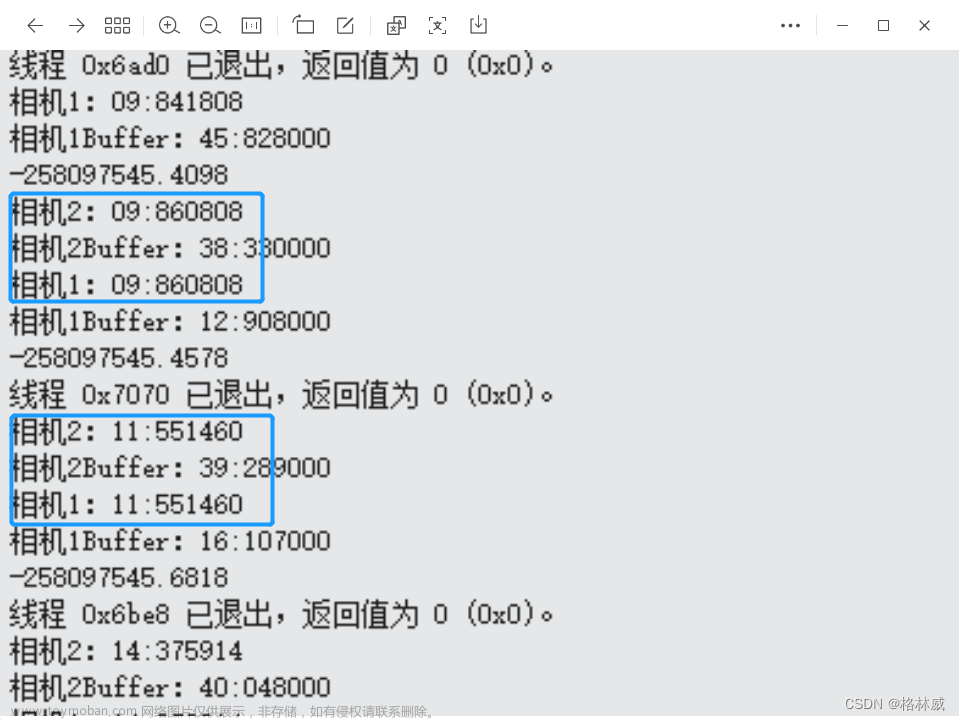
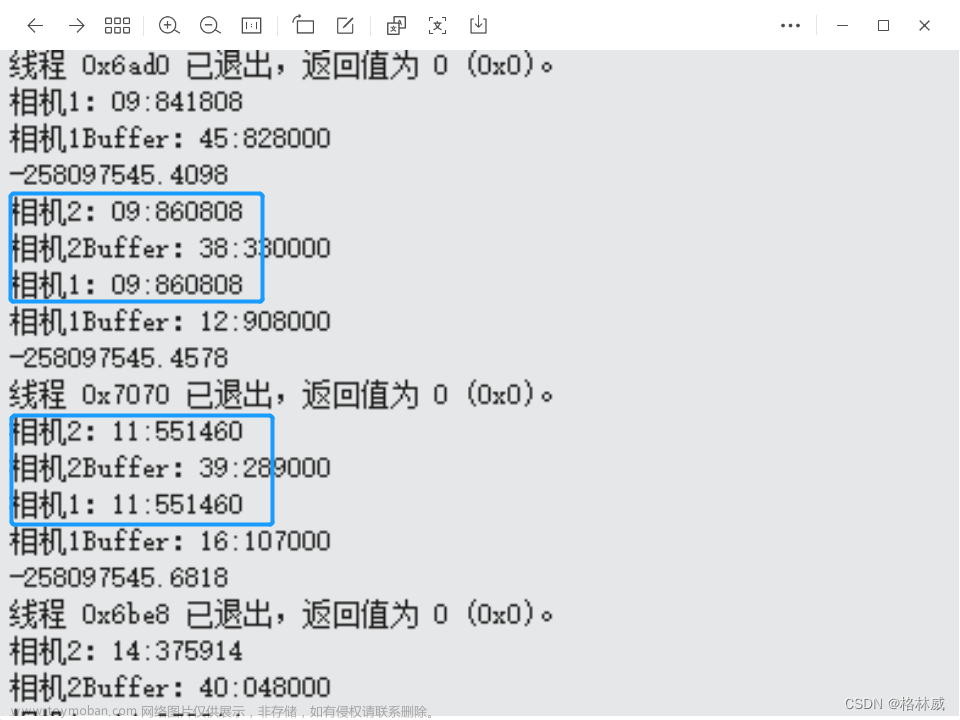
这里展示一段并行计算程序在三种测量时间方法下的对比,各位可以看看差别(可以推测出测试设备是 6C6T 的 CPU 哦):

可以看到有时差别还是挺大的。
参考
21.2 Time Types - GNU
21.4 Processor And CPU Time - GNU
clock_gettime(3) — Linux manual page
What is the proper way to use clock_gettime()? - stack overflow
clock_getres, clock_gettime, clock_settime - clock and timer functions - IEEE文章来源:https://www.toymoban.com/news/detail-856092.html
希望能帮到有需要的人~文章来源地址https://www.toymoban.com/news/detail-856092.html
到了这里,关于如何在C/C++中测量一个函数或者功能的运行时间(串行和并行,以及三种方法的实际情况对比)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!