Apache Flink 是一个开源的流处理框架,用于处理有界和无界的数据流。Flink 设计用于运行在所有常见的集群环境中,并且能够以高性能和可扩展的方式进行实时数据处理和分析。下面将详细介绍 Flink 的基础架构组件和其工作原理。
1. Flink 架构概览
Flink 的架构主要包括以下几个核心组件:
- JobManager (Master Node)
- TaskManager (Worker Nodes)
- Dispatcher and Resource Manager
- Client
JobManager
JobManager 是 Flink 集群的核心节点,负责整个数据处理流程的管理和协调。JobManager 的主要职责包括:
-
作业调度:负责
接受作业提交,解析和优化执行计划,然后将作业分解为任务并分配给 TaskManagers。 -
资源管理:决定作业的任务如何在 TaskManagers 上
分配执行。 -
故障恢复:管理检查点(Checkpoints),在
任务执行失败时恢复作业状态。 -
任务协调:协调
TaskManagers之间的通信,如数据分发和任务同步。
TaskManager
TaskManager 是执行具体任务的节点,一个 Flink 集群可以有多个 TaskManager 节点。TaskManager 的主要功能是:
-
任务执行:每个 TaskManager 可以
并行执行多个任务,具体数量取决于其配置的 slot 数量。 -
状态管理:管理本地的
数据缓存和任务的状态,参与状态的快照以实现故障恢复。 -
数据交换:处理
节点间的数据传输。
Dispatcher
Dispatcher 组件负责接收客户端的作业提交请求,并启动一个新的 JobMaster 实例来负责作业的执行。Dispatcher 提供了一个 REST 接口用于作业提交和状态查询。
Resource Manager
Resource Manager 负责管理 TaskManagers 的资源,例如分配和回收。在 Flink 集群运行于容器化环境(如 Kubernetes)时,Resource Manager 也会与外部的资源管理系统交互,进行资源的动态调整。
Client
Client 是用户与 Flink 集群交互的界面,用于提交作业、查询作业状态等。客户端通过向 Dispatcher 或 JobManager 提交作业描述(如 JAR 文件),启动作业的执行。
2. 数据处理流程
在 Flink 中,数据处理的流程通常包括以下几个步骤:
-
作业提交:用户通过
Client提交作业到Dispatcher,Dispatcher 创建作业的JobGraph,并将其提交到JobManager。 -
作业调度:JobManager 将
JobGraph转换为一个可执行的物理计划——ExecutionGraph,并决定如何在TaskManagers上分布这些任务。 -
任务执行:JobManager 将具体的任务分配给 TaskManager 的
空闲 slots,TaskManagers 根据指令执行任务。 -
状态管理与故障恢复:在执行过程中,TaskManagers
定期向 JobManager报告状态,JobManager 根据需要进行任务的重启或状态回滚。 -
结果输出:处理结果可以
输出到外部系统,如数据库、文件系统或其他存储系统。
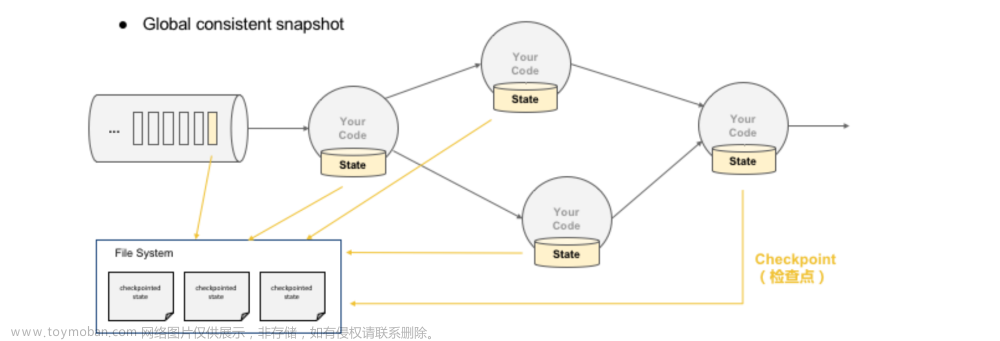
3. 容错机制
Flink 的容错机制基于状态的一致性快照(checkpointing)。通过定期创建全局一致性的状态快照,当某个部分发生故障时,Flink 可以从最近的快照恢复整个作业的状态,继续执行,确保数据处理的精确一致性。文章来源:https://www.toymoban.com/news/detail-856135.html
总结
Flink 的基础架构设计使其能够高效处理大规模数据流,支持复杂的数据处理任务和流式计算,同时提供高度的可扩展性和可靠性。通过其强大的容错机制,Flink 能够保证在发生故障时数据不丢失,处理不中断。这些特点使得 Flink 成为处理实时数据流的理想选择。文章来源地址https://www.toymoban.com/news/detail-856135.html
到了这里,关于大数据:【学习笔记系列】Flink基础架构的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!