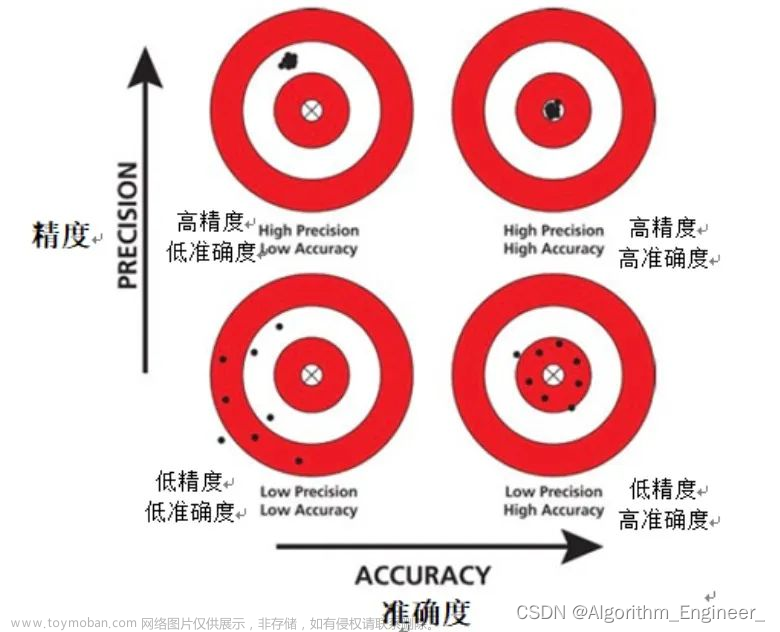
一、Accuracy 介绍
在机器学习和数据科学中,准确度(Accuracy)是衡量分类模型性能的一个基本且重要的指标。准确度表示模型正确分类的样本数占总样本数的比例。Python的sklearn库提供了简单而强大的工具来训练和评估分类模型,包括计算准确度。
准确度的计算方式相对直接且简单,下面将详细解释其计算过程。
首先,我们需要明确几个概念:
- 真正例(True Positive, TP):模型预测为正例,且实际也为正例的样本数。
- 真反例(True Negative, TN):模型预测为反例,且实际也为反例的样本数。
- 假正例(False Positive, FP):模型预测为正例,但实际为反例的样本数(即误报)。
- 假反例(False Negative, FN):模型预测为反例,但实际为正例的样本数(即漏报)。
基于上述概念,准确度的计算公式如下:
Accuracy = TP + TN TP + TN + FP + FN \text{Accuracy} = \frac{\text{TP} + \text{TN}}{\text{TP} + \text{TN} + \text{FP} + \text{FN}} Accuracy=TP+TN+FP+FNTP+TN
这个公式表示的是正确分类的样本数(真正例和真反例之和)除以总样本数(真正例、真反例、假正例和假反例之和)。换句话说,准确度就是模型预测正确的样本占总样本的比例。
在sklearn库中,计算准确度变得非常简单。你可以使用accuracy_score函数,它接受两个数组作为输入:一个是实际的目标值(y_true),另一个是模型预测的值(y_pred)。然后,它会自动计算并返回准确度。
二、案例学习
下面,我们将通过一个简单的示例来展示如何使用sklearn来训练一个分类模型,并计算其在测试集上的准确度。
首先,我们需要导入必要的库,并加载数据集。在这个例子中,我们将使用sklearn自带的鸢尾花(Iris)数据集,这是一个经典的多类分类问题。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
接下来,我们需要对数据进行预处理。在这个例子中,我们将使用标准缩放(StandardScaler)来使特征具有相同的尺度,这对于许多机器学习算法来说是非常重要的。
# 数据预处理:标准缩放
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
现在,我们可以创建一个分类模型,并使用训练数据进行训练。在这个例子中,我们将使用逻辑回归(Logistic Regression)作为分类器。
# 创建逻辑回归模型
model = LogisticRegression()
# 使用训练数据进行训练
model.fit(X_train, y_train)
训练完成后,我们可以使用模型对测试集进行预测,并使用sklearn的accuracy_score函数来计算准确度。
# 对测试集进行预测
y_pred = model.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# Accuracy: 1.00
在上面的代码中,accuracy_score函数接受实际值(y_test)和预测值(y_pred)作为输入,并返回分类准确度。准确度是一个介于0和1之间的值,越接近1表示模型的分类性能越好。
需要注意的是,准确度虽然是一个直观的指标,但它并不总是最适合衡量模型性能的指标。特别是当数据集的类别分布不平衡时,准确度可能无法准确地反映模型的性能。在这种情况下,我们可能需要考虑其他指标,如精确度(Precision)、召回率(Recall)和F1分数(F1 Score)等。文章来源:https://www.toymoban.com/news/detail-856496.html
三、总结
通过上面的示例,我们展示了如何使用sklearn来训练和评估一个分类模型,并计算其在测试集上的准确度。在实际应用中,我们可以根据具体的问题和数据集选择合适的分类模型和评估指标,以得到更准确的分类结果和性能评估。文章来源地址https://www.toymoban.com/news/detail-856496.html
到了这里,关于sklearn【Accuracy】准确度介绍和案例学习!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!