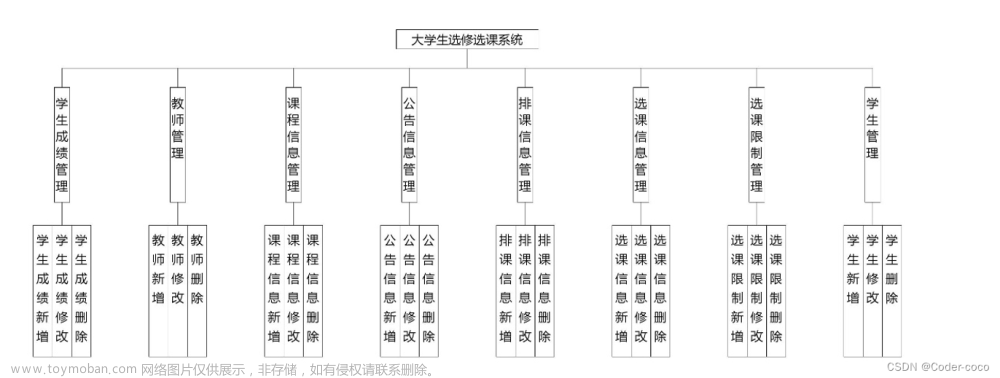
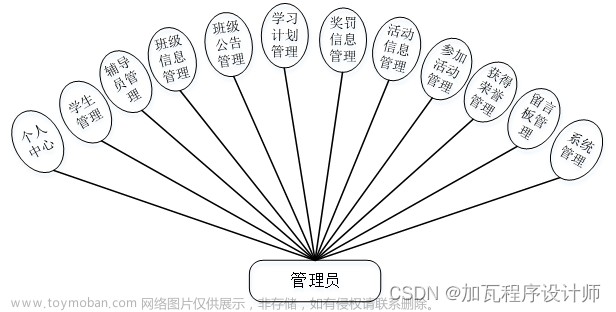
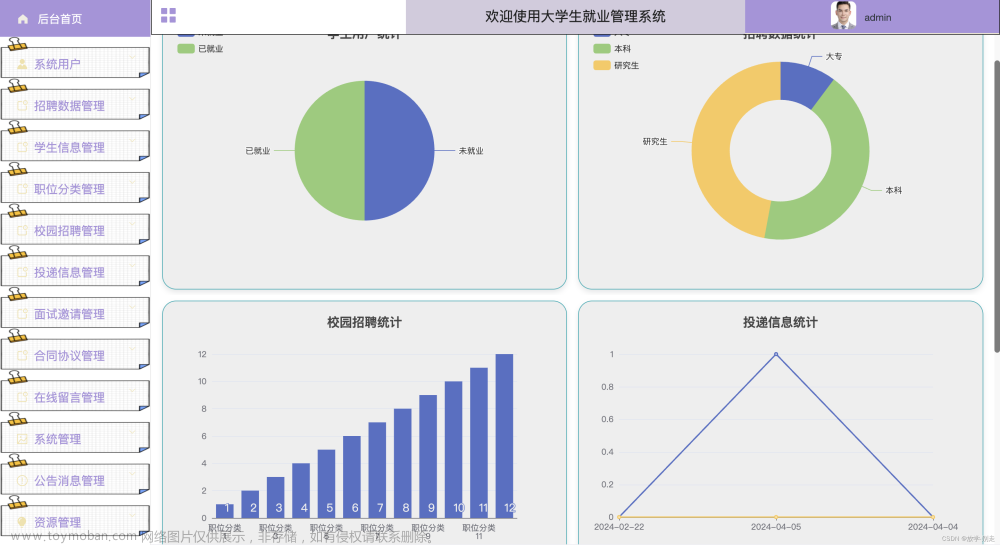
基于spark分析以springboot为后段vue为前端的大学生就业管理系统
大学生就业管理系统是一个针对高校毕业生就业信息管理的有效工具,它能够帮助学校和学生更好地管理就业数据,提供数据驱动的决策支持。本文将介绍如何通过爬虫采集数据,利用Spark进行数据分析处理,再结合Spring Boot后端服务和Vue前端技术,搭建一个功能全面的大学生就业管理系统。


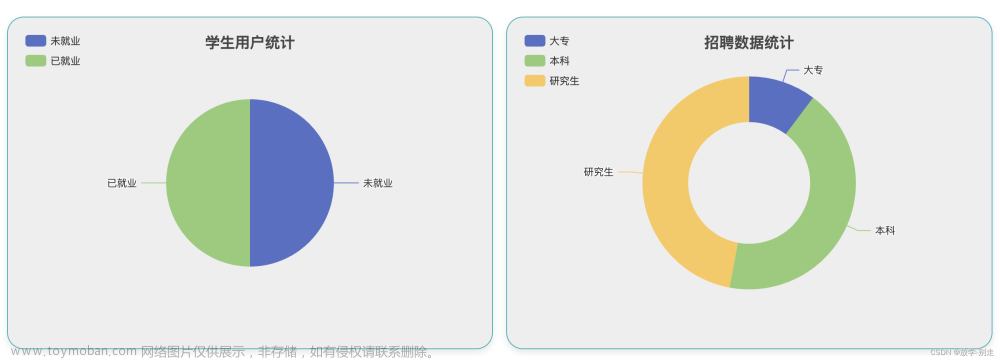

1. 数据采集
1.1 爬虫设计
首先,我们需要设计一个爬虫程序来从猎聘网采集数据。爬虫程序应该具备以下功能:
**数据提取:**精确提取职位描述、要求、薪资等关键信息。
**异常处理:**能够处理网络请求失败、页面结构变化等异常情况。
import csv
import time
import requests
import execjs
from csv2mysql import sync_data2db
# f = open('../storage/data.csv', mode='a', encoding='utf-8')
# csv_writer = csv.DictWriter(f,fieldnames=[
# '职位',
# '城市',
# '薪资',
# '经验',
# '标签',
# '公司',
# '公司领域',
# '公司规模'])
# csv_writer.writeheader()
def read_js_code():
f = open('demo.js', encoding='utf-8')
txt = f.read()
js_code = execjs.compile(txt)
ckId = js_code.call('r', 32)
return ckId
def post_data():
read_js_code()
url = "https://api-c.liepin.com/api/com.liepin.searchfront4c.pc-search-job"
headers = {
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Sec-Ch-Ua-Platform': 'macOS',
'Content-Length': '398',
'Content-Type': 'application/json;charset=UTF-8;',
'Host': 'api-c.liepin.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Origin': 'https://www.liepin.com',
'Referer': 'https://www.liepin.com/',
'Sec-Ch-Ua': '"Google Chrome";v="119", "Chromium";v="119", "Not?A_Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-site',
'X-Client-Type': 'web',
'X-Fscp-Bi-Stat': '{"location": "https://www.liepin.com/zhaopin"}',
'X-Fscp-Fe-Version': '',
'X-Fscp-Std-Info': '{"client_id": "40108"}',
'X-Fscp-Trace-Id': '52262313-e6ca-4cfd-bb67-41b4a32b8bb5',
'X-Fscp-Version': '1.1',
'X-Requested-With': 'XMLHttpRequest',
}
list = ["H01$H0001", "H01$H0002",
"H01$H0003", "H01$H0004", "H01$H0005",
"H01$H0006", "H01$H0007", "H01$H0008",
"H01$H0009", "H01$H00010", "H02$H0018", "H02$H0019", "H03$H0022",
"H03$H0023", "H03$H0024", "H03$H0025", "H04$H0030", "H04$H0031",
"H04$H0032", "H05$H05", "H06$H06", "H07$H07", "H08$H08"]
for name in list:
print("-------{}---------".format(name))
for i in range(10):
print("------------第{}页-----------".format(i))
data = {
"data": {
"mainSearchPcConditionForm":
{
"city": "410", "dq": "410", "pubTime": "", "currentPage": i, "pageSize": 40,
"key": "",
"suggestTag": "", "workYearCode": "1", "compId": "", "compName": "", "compTag": "",
"industry": name, "salary": "", "jobKind": "", "compScale": "", "compKind": "",
"compStage": "",
"eduLevel": ""},
"passThroughForm":
{
"scene": "page", "skId": "z33lm3jhwza7k1xjvcyn8lb8e9ghxx1b",
"fkId": "z33lm3jhwza7k1xjvcyn8lb8e9ghxx1b",
"ckId": read_js_code(),
'sfrom': 'search_job_pc'}}}
response = requests.post(url=url, json=data, headers=headers)
time.sleep(2)
parse_data(response)
def parse_data(response):
try:
jobCardList = response.json()['data']['data']['jobCardList']
sync_data2db(jobCardList)
except Exception as e:
return
def sync_data2db(jobCardList):
try:
with connection.cursor() as cursor:
for job in jobCardList:
placeholders = ', '.join(['%s'] * (8))
insert_query = f"INSERT INTO data1 (title,city,salary,campus_job_kind,labels,compName,compIndustry,compScale) VALUES ({
placeholders})"
print(job['job']['title'], job['job']['dq'].split("-")[0], process_salary(job['job']['salary']),
job['job']['campusJobKind'] if 'campusJobKind' in job['job'] else '应届'
, job['job']['labels'], job['comp']['compName'], job['comp']['compIndustry'], job['comp']['compScale'])
cursor.execute(insert_query,
(job['job']['title'], job['job']['dq'].split("-")[0], process_salary(job['job']['salary']),
job['job']['campusJobKind'] if 'campusJobKind' in job['job'] else '应届'
, job['job']['labels'], job['comp']['compName'], job['comp']['compIndustry'], job['comp']['compScale']))
connection.commit()
finally:
connection.close()
if __name__ == '__main__':
post_data()

2. 数据处理
2.1 数据清洗
采集到的数据可能包含噪声、缺失值或不一致的格式,需要进行数据清洗。使用Apache Spark进行数据处理,它能够高效地处理大规模数据集。这个过程主要通过spark将数据分析处理后的数据写入mysql。
**去除无用信息:**如广告、版权声明等。
**缺失值处理:**填充或删除缺失的数据。文章来源:https://www.toymoban.com/news/detail-856549.html
from pyspark.sql import SparkSession
from pyspark.sql.types import StringType, StructType
def read_data_from_csv(path):
schema = StructType() \
.add("recruitment_positions",StringType(),True) \
.add("recruitment_city",StringType(),True) \
.add("recruitment_salary",StringType(),True) \
.add("recruitment_experience",StringType(),True) \
.add("recruitment_skills",StringType(),True) \
.add("recruitment_company",StringType(),True) \
.add("recruitment_industry",StringType(),True) \
.add("recruitment_scale",StringType(),True)
df = spark.read\
.option("header", True)\
.schema(schema)\
.csv(path)
return df
def data_ana(df):
df.createTempView("job")
df = spark.sql("""
select
recruitment_positions,
recruitment_salary,
recruitment_skills as recruitment_requirements,
recruitment_experience,
'本科' as recruiting_educational_qualifications,
recruitment_company,
recruitment_scale as company_stage,
recruitment_industry,
recruitment_skills,
recruitment_city,
recruitment_city as recruitment_area,
recruitment_city as recruitment_address,
recruitment_scale
from job
""")
df.show()
return df
def write_data2mysql(df):
df.write.format("jdbc") \
.option("url", "jdbc:mysql://localhost:3306/project05928") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("dbtable", "recruitment_data") \
.option("user", "root") \
.option("password", "12345678") \
.mode("append") \
.save()
if __name__ == '__main__':
spark = SparkSession.builder \
.enableHiveSupport()\
.config("spark.driver.extraClassPath","../lib/mysql-connector-java-8.0.30.jar")\
.getOrCreate()
df = read_data_from_csv("../data_prepare/data.csv")
df = data_ana(df)
write_data2mysql(df)
spark.stop()
 文章来源地址https://www.toymoban.com/news/detail-856549.html
文章来源地址https://www.toymoban.com/news/detail-856549.html
- 数据库设计
设计MySQL数据库表结构,存储处理后的数据。
DROP TABLE IF EXISTS `slides`;
CREATE TABLE `slides` (
`slides_id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '轮播图ID:',
`title` varchar(64) DEFAULT NULL COMMENT '标题:',
`content` varchar(255) DEFAULT NULL COMMENT '内容:',
`url` varchar(255) DEFAULT NULL COMMENT '链接:',
`img` varchar(255) DEFAULT NULL COMMENT '轮播图:',
`hits` int(10) unsigned NOT NULL DEFAULT '0' COMMENT '点击量:',
`create_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间:',
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间:',
PRIMARY KEY (`slides_id`) USING BTREE
) ENGINE=MyISAM DEFAULT CHARSET=utf8 ROW_FORMAT=DYNAMIC COMMENT='轮播图';
DROP TABLE IF EXISTS `auth`;
CREATE TABLE `auth` (
`auth_id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT '授权ID:',
`user_group` varchar(64) DEFAULT NULL COMMENT '用户组:',
`mod_name` varchar(64) DEFAULT NULL COMMENT '模块名:',
`table_name` varchar(64) DEFAULT NULL COMMENT '表名:',
`page_title` varchar(255) DEFAULT NULL COMMENT '页面标题:',
`path` varchar到了这里,关于基于spark分析以springboot为后段vue为前端的大学生就业管理系统的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!