1.背景介绍
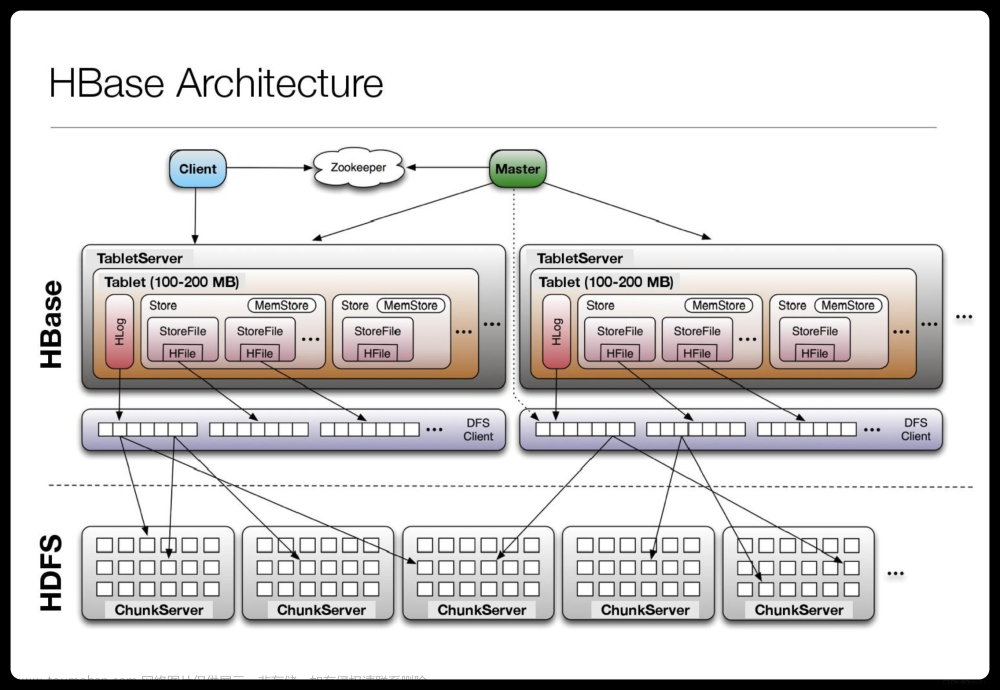
HBase是一个分布式、可扩展、高性能的列式存储系统,基于Google的Bigtable设计。它是Hadoop生态系统的一部分,可以与HDFS、MapReduce、ZooKeeper等其他组件集成。HBase适用于大规模数据存储和实时数据访问场景,如日志记录、实时数据分析、实时数据流处理等。
在HBase中,数据以列族(column family)的形式存储,每个列族包含一组列(column)。HBase支持两种基本操作:Put和Get。Put操作用于插入或更新数据,Get操作用于查询数据。HBase还支持Scan操作,用于查询一组数据。
然而,在大规模数据存储和实时数据访问场景中,单个操作可能无法满足性能要求。因此,需要进行批量操作,即在一次操作中处理多个数据。本文将介绍如何在HBase中进行批量操作。
2.核心概念与联系
在HBase中,批量操作主要包括以下几种:
1.批量插入:将多个Put操作组合成一次操作,以提高插入性能。
2.批量更新:将多个更新操作组合成一次操作,以提高更新性能。
3.批量删除:将多个删除操作组合成一次操作,以提高删除性能。
4.批量查询:将多个Get操作组合成一次操作,以提高查询性能。
5.批量扫描:将多个Scan操作组合成一次操作,以提高扫描性能。
这些批量操作可以提高HBase的性能,降低延迟,提高吞吐量。
3.核心算法原理和具体操作步骤以及数学模型公式详细讲解
3.1 批量插入
批量插入的核心算法原理是将多个Put操作组合成一次操作,以减少HBase的开销。具体操作步骤如下:
1.创建一个Batch对象,用于存储Put操作。
2.为Batch对象添加Put操作。
3.使用Batch对象执行插入操作。
数学模型公式:
$$ BatchSize = n \times (KeySize + ValueSize) + Overhead $$
其中,BatchSize是批量插入的大小,n是Put操作的数量,KeySize是键的大小,ValueSize是值的大小,Overhead是HBase的开销。
3.2 批量更新
批量更新的核心算法原理是将多个更新操作组合成一次操作,以减少HBase的开销。具体操作步骤如下:
1.创建一个Batch对象,用于存储更新操作。
2.为Batch对象添加更新操作。
3.使用Batch对象执行更新操作。
数学模型公式:
$$ BatchSize = n \times (KeySize + ValueSize) + Overhead $$
其中,BatchSize是批量更新的大小,n是更新操作的数量,KeySize是键的大小,ValueSize是值的大小,Overhead是HBase的开销。
3.3 批量删除
批量删除的核心算法原理是将多个删除操作组合成一次操作,以减少HBase的开销。具体操作步骤如下:
1.创建一个Batch对象,用于存储删除操作。
2.为Batch对象添加删除操作。
3.使用Batch对象执行删除操作。
数学模型公式:
$$ BatchSize = n \times (DeletionSize + Overhead) $$
其中,BatchSize是批量删除的大小,n是删除操作的数量,DeletionSize是删除操作的大小,Overhead是HBase的开销。
3.4 批量查询
批量查询的核心算法原理是将多个Get操作组合成一次操作,以减少HBase的开销。具体操作步骤如下:
1.创建一个Batch对象,用于存储Get操作。
2.为Batch对象添加Get操作。
3.使用Batch对象执行查询操作。
数学模型公式:
$$ BatchSize = n \times (RequestSize + Overhead) $$
其中,BatchSize是批量查询的大小,n是Get操作的数量,RequestSize是请求的大小,Overhead是HBase的开销。
3.5 批量扫描
批量扫描的核心算法原理是将多个Scan操作组合成一次操作,以减少HBase的开销。具体操作步骤如下:
1.创建一个Batch对象,用于存储Scan操作。
2.为Batch对象添加Scan操作。
3.使用Batch对象执行扫描操作。
数学模型公式:
$$ BatchSize = n \times (ScanSize + Overhead) $$
其中,BatchSize是批量扫描的大小,n是Scan操作的数量,ScanSize是扫描操作的大小,Overhead是HBase的开销。
4.具体代码实例和详细解释说明
以下是一个使用Java的HBase API进行批量插入的示例代码:
```java import org.apache.hadoop.hbase.client.Batch; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.util.Bytes;
public class BatchInsertExample { public static void main(String[] args) throws Exception { // 创建一个HBase连接 Connection connection = ConnectionFactory.createConnection();
// 创建一个Batch对象
Batch batch = new Batch(connection);
// 创建多个Put操作
Put put1 = new Put(Bytes.toBytes("row1"));
put1.add(Bytes.toBytes("cf1"), Bytes.toBytes("col1"), Bytes.toBytes("value1"));
Put put2 = new Put(Bytes.toBytes("row2"));
put2.add(Bytes.toBytes("cf1"), Bytes.toBytes("col2"), Bytes.toBytes("value2"));
Put put3 = new Put(Bytes.toBytes("row3"));
put3.add(Bytes.toBytes("cf1"), Bytes.toBytes("col3"), Bytes.toBytes("value3"));
// 添加Put操作到Batch对象
batch.add(put1);
batch.add(put2);
batch.add(put3);
// 执行批量插入操作
batch.execute();
// 关闭连接
connection.close();
}} ```
在这个示例中,我们创建了一个HBase连接,然后创建了一个Batch对象。接着,我们创建了三个Put操作,并将它们添加到Batch对象中。最后,我们执行批量插入操作,将三个Put操作一次性地插入到HBase中。
5.未来发展趋势与挑战
随着数据规模的不断增长,HBase需要继续优化其性能和可扩展性。未来的发展趋势和挑战包括:
1.提高HBase的吞吐量,以支持更高的查询速度和更大的并发量。
2.优化HBase的存储格式,以减少存储开销和提高存储效率。
3.提高HBase的可用性,以支持更多的故障转移和容错策略。
4.扩展HBase的功能,以支持更多的数据处理和分析任务。
5.提高HBase的兼容性,以支持更多的数据源和数据格式。
6.附录常见问题与解答
Q: HBase如何实现数据的一致性?
A: HBase使用WAL(Write Ahead Log)机制来实现数据的一致性。当一个Put操作被提交时,HBase会先将其写入WAL,然后再写入磁盘。这样,即使在写入磁盘过程中出现故障,HBase也可以从WAL中恢复数据,保证数据的一致性。
Q: HBase如何实现数据的分区和负载均衡?
A: HBase使用Region和RegionServer机制来实现数据的分区和负载均衡。Region是HBase中的基本数据分区单位,每个Region包含一定范围的数据。当Region的大小达到阈值时,HBase会自动将其拆分成多个子Region。RegionServer是HBase中的数据存储和处理节点,负责存储和处理一定范围的Region。通过这种机制,HBase可以实现数据的分区和负载均衡,提高系统的性能和可扩展性。
Q: HBase如何实现数据的备份和恢复?文章来源:https://www.toymoban.com/news/detail-856550.html
A: HBase使用HDFS(Hadoop Distributed File System)作为底层存储系统,HDFS支持数据的自动备份和恢复。在HBase中,每个Region的数据都会被存储在多个数据节点上,这样即使一个数据节点出现故障,HBase也可以从其他数据节点中恢复数据。此外,HBase还支持手动备份和恢复操作,用户可以通过HBase的API来实现数据的备份和恢复。文章来源地址https://www.toymoban.com/news/detail-856550.html
到了这里,关于数据批量操作:如何在HBase中进行批量操作的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!