阿里云和腾讯云都曾出现过因一个组件故障而导致所有可用区同时瘫痪的情况。本文将探讨如何从架构设计的角度减小故障域,在故障发生时最小化业务损失,并以 Sealos 的稳定性实践为例,分享经验教训。
抛弃主从,拥抱点对点架构
从腾讯云故障报告中可以看出来多可用区一起挂基本都是因为一些集中化的组件造成,比如统一 API,统一鉴权认证之类的系统故障。

所以这个 X 系统一挂,故障域就会非常大。
相比之下,去中心化的点对点架构能够很好地规避这一风险。以比特币网络为例,由于不存在中心节点,其稳定性远高于传统的主从式集群,几乎很难挂机。

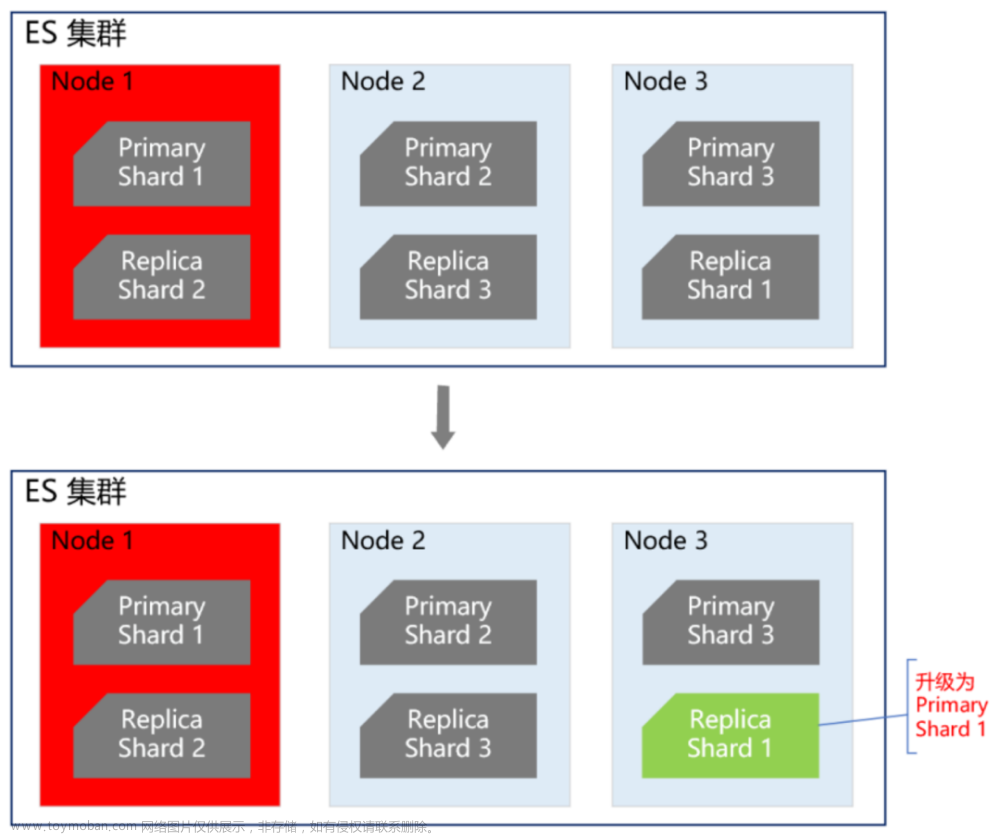
所以 Sealos 在设计多可用区的时候就充分吸取了阿里云腾讯云的教训,采用了一种无主的架构,所有可用区都是自治的,主要问题是像用户账户这些数据如何在多可用区同步的问题。变成了这样的一种架构:

各可用区完全自治,仅在关键的共享数据 (如用户账户信息) 上通过跨区域分布式数据库 (我们使用的是 CockroachDB) 进行同步。每个可用区都连接分布式数据库 CockroachDB 在本地的节点。
这样一来,单个可用区的故障就不会影响其他区域的业务连续性。只有在分布式数据库集群整体发生问题时,才会导致所有可用区的控制面不可用。好在 CockroachDB 本身在容错、灾备、应对网络分区等方面有着出色的表现,大大降低了这种情况的发生概率。这样整体的架构就简单了,集中精力把数据库的稳定性做好就行,监控,破坏性测试都做好。
这样做的另外一个好处是为灰度发布、差异化运营提供了便利。例如,新功能可以先在部分区域进行小流量验证,待稳定后再全量上线;不同区域也可以根据客户群体的特点,提供定制化的服务,而不必保持完全一致。
绝对稳定的系统不存在
大家对云的稳定性喷的比较多,但凡是个云厂商无一例外都出现过故障,我们也出现过过非常多的故障,这里最重要的是如何收敛,他不仅是个技术问题,也是个组织管理问题,同样也还是个成本问题,这块我结合创业过程中我们遇到的具体例子来给大家做个分享。
Sealos 从故障中汲取的教训
2023.3.17 日 Laf 重大故障
这是创业首次遇到的重大故障,产品上线还没两天就给我们当头一棒,时间记的这么清楚是因为刚好是公司一周年庆祝,蛋糕都没有时间切,一直恢复到夜里三点多。
最终故障原因很奇葩,是我们贪图便宜用了轻量服务器,轻量服务器上做容器的网络虚拟化会导致丢包,最终我们把整个集群迁移到了正常的一个 VPC 服务器上,所以很多时候解决稳定性和成本分不开。
所以很多都觉得公有云贵什么的,很多时候为了解决剩下的那 10% 的问题确实要花很多倍的成本。
Laf 后续有出现了一系列数据库相关的稳定性问题,因为使用的是多租户共享一个 MongoDB 库的模型,最终论证的结论是这条路我们走不通,数据库隔离性问题我们很难解决,所以现在全部采用了独立数据库的方式,问题得到最终解决。
还有网关上的稳定性问题,我们一开始选了某个不靠谱的 Ingress 控制器,问题频发,具体是哪家就不点名了,最终换成了 Higress,彻底解决这个问题,目前不仅资源占用更少,而且更稳定,这里也非常感谢阿里 Higress 团队的贴身支持,我们暴露的问题也更好的帮助了 Higress 的更成熟,双赢。
2023 年 6 月我们 Sealos 公有云正式上线,遇到一个最大的问题就是被攻击,流量很大的 CC 攻击,加防护能解决但是也意味着成本的飙升,所以在这两者之间的权衡就很纠结了,不防稳定性难解决,防了卖的钱收不回成本。后来我们把网关换掉之后,发现 Envoy 是真的强,居然能把攻击的流量抗下来了,在那之前用的是 Nginx,一挂挂一片。而且 K8s 厉害的的地方就是自愈能力强,即便网关挂了 5min 内也能实现自愈,只要不是同时挂,业务基本不受影响。
稳定性不断收敛的最佳实践
故障处理的流程
为了让系统稳定性不断收敛提升,Sealos 在内部建立了一套严格的故障管理流程:
每次故障发生后,都要详细记录,并持续跟进。很多公司走到故障复盘就结束了,但事实上复盘不是目的,关键要形成切实可行的整改措施,并予以落实,彻底防止类似故障再次发生。故障处置完成后仍需持续观察一段时间,直至确认问题不再出现。
在管理目标上,一开始我们在 2024 Q1 OKR 中这样去定义了稳定性收敛的目标:

后来发现这种笼统的口号式 OKR 并不靠谱,稳定性的收敛需要更具体,这个 KR 的结果是我们没达成,几乎没起到什么效果。在收敛的过程你并不需要全面开花,每个季度聚焦在几个核心点上,持续迭代几个季度就会收敛的非常好。
所以在 Q2 时我们定了更具体的目标:

对稳定性的设定,不能仅停留于设定个指标,也不能过于笼统,需要具体可见的措施,需要具体的衡量办法。
比如,如果设定 99.9%,如何达到?那么当前的可用性是多少?当前的核心问题是什么?如何测量?需要做些什么?谁来做?设定不局限于可用时长,要列细一些,比如故障等级、故障次数、故障时长、大客户故障观测等等。
要分出专项类别,列出优先级,比如:数据库稳定性、网关稳定性、大客户服务可用性指标、CPU/内存资源过载故障。
还要重点监测大客户,比如自走棋、FastGPT 商业大客户、匆匆雪工作室等 (月使用 30 核以上,挑出 5 个典型)。
稳定性问题就那么多,当服务好了这些大客户基本就能覆盖掉小客户,不追求多,聚焦解决当前最核心的稳定性问题,然后一定要建立起一个完善的跟踪流程。
造成故障的同学可能会收到惩罚,扣奖金,甚至开除。我们作为创业公司通常不会用惩罚的措施,因为当事人也不想造成故障,而且大家都也确实很辛苦的在解决问题,真正能打仗的都是负过伤的,我们更倾向正面的激励,比如如果季度故障频率降低,就适当给些激励。
大道至简的架构设计
系统架构从设计开始就关系到了稳定性,越复杂的架构越容易出问题,所以很多公司没有重视到这一点,我经常参与公司架构设计和评审,通常发现设计过于复杂在我这都很难过得去,就感觉哪不对,Sealos 多可用区就是一个非常好的例子,把一个复杂的事情变成一个简单的 CRUD,那只需要把数据库稳定性做好,数据库表结构设计简单很多稳定性问题就被扼杀在摇篮中了。
我们的计量系统也是这样,起初设计了怕有十几个 CRD,折腾了大半年稳定性也收敛不下来,最后重新设计选型,差不多两周开发完了,一个月就稳定上线了。
所以:大道至简的设计对稳定性至关重要!
适度监控,有的放矢
监控是把双刃剑,过犹不及。Sealos 很多次故障都是因为监控造成的,Prometheus 占用资源过大,API Server 不堪重负,反而引发了新的稳定性问题。吸取教训后,我们改用 VictoriaMetrics 这种更轻量级的监控方案,同时严格控制监控指标的数量。类似 Uptime Kuma 这种工具就很实用,跨区域相互拨测,及时发现问题。
on call 也是如此,每天几千条告警,on call 什么东西?所以这里基本是从 0 开始慢慢做加法,比如我们是先从 “大客户业务最终稳定性” 这个视角去做的,比如一个容器故障推出了这个如果要 on call 的话那估计电话响个不停。再慢慢加上比如主机 not ready 这些。主机 not ready 理论上不应该影响业务,随着系统的逐渐成熟,最终可以做到 not ready 也不需要 on call。
故障通报不能怕丢人
腾讯云的复盘报告就做得非常好,如实说明故障发生的原因,客观分析哪些地方做得还不够,并承诺积极整改。这种坦诚、负责的态度,其实更容易赢得用户的信任。相比之下,对问题讳莫如深,生怕舆论发酵,无异于饮鸩止渴,反而让用户觉得是个不透明的黑盒,今后还不知会出什么幺蛾子。真正热爱你的产品、愿意与你相伴成长的客户,是能够包容非原则性错误的。关键要拿出实实在在改进的诚意和行动。
总结
Sealos 公有云服务上线一年多来,已经积累了十多万注册用户。凭借出色的功能、体验和性价比,不少开发者青睐有加,部分大客户也开始尝试将业务迁移到我们 Sealos 云上。这其中不乏一些大型互联网产品,例如《开心自走棋》游戏就有 400 多万活跃用户。文章来源:https://www.toymoban.com/news/detail-856619.html
放眼未来,我们相信通过系统化的故障管理不断收敛稳定性,通过简洁高效的架构设计、稳扎稳打的监控策略,再辅之以开诚布公的沟通态度,Sealos 这个由国内开源小公司孕育发展起来的云一定会变成一朵非常先进的云!文章来源地址https://www.toymoban.com/news/detail-856619.html
到了这里,关于如何从架构层面降低公有云多可用区同时故障的概率的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!