参考:
https://pytorch.org/blog/accelerating-generative-ai-3/
https://colab.research.google.com/drive/1jZ5UZXk7tcpTfVwnX33dDuefNMcnW9ME?usp=sharing#scrollTo=jueYhY5YMe22
大概GPU资源8G-16G;另外模型资源下载慢可以在国内镜像:https://aifasthub.com/ 文章来源:https://www.toymoban.com/news/detail-856620.html
文章来源:https://www.toymoban.com/news/detail-856620.html
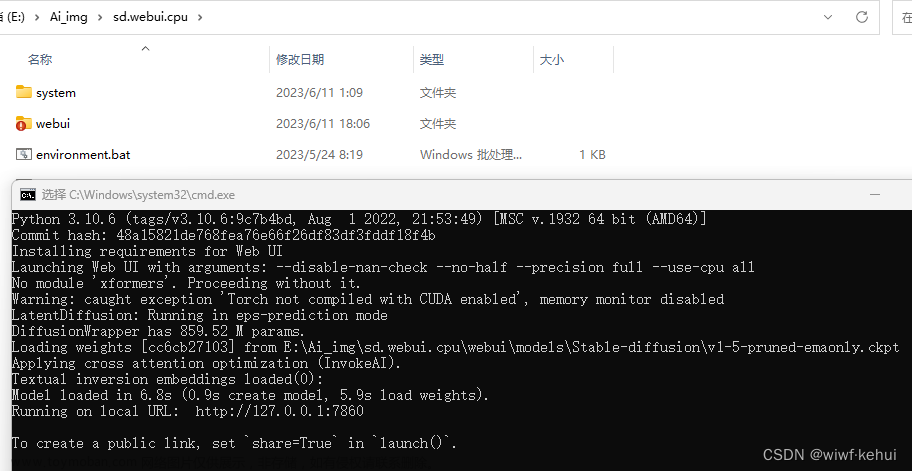
1、加速代码
能加速到2秒左右文章来源地址https://www.toymoban.com/news/detail-856620.html
from diffusers import StableDiffusionXLPipeline
import torch
pipe = StableDiffusionXLPipeline.from_pretrained(
"stabilityai/stable-diffusion-xl-base-1.0<到了这里,关于diffusers加速文生图速度;stable-diffusion、PixArt-α模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!