3D视觉、SLAM、自动驾驶算法经常会碰到多传感器标定、数据对齐的问题,比如下面这个图(CADCD):

上面就包含了7个camera,每个camera的位姿不同,采集到的数据也不同,怎么通过这些数据重建3D场景就需要用到对齐。
下图是human3.6的采集环境配置图:
关于这一块的知识点有点多,容易忘,不记录下下次又得从头再来。
相机成像
首先理理相机模型,以及几个知识点,参考自CS231A camera model。
pinhole camera model
小孔模型,光通过小孔在像平面上形成一个倒立的图像,如下图所示:

小孔模型很简单:
- 光圈
光圈即小孔。放大光圈能增加进光量,但同一个点通过的光线也会增加形成模糊的区域。因此,增加光圈的大小会影响到进光量、图像的清晰度、景深;光圈小,亮度暗,清晰;光圈大,亮度大,模糊; - 像距
像距即光圈到像平面(感光元件或者胶卷)的距离。当像平面大小固定时且足够大时,改变像距会导致投影变大或变小;否则,调整像距会改变FOV;
lens model

透镜模型能解决小孔模型为了成像清晰而光照不足的问题,但会引入另外一个问题,弥散。
上图object中有两个点,红点经过透镜后可以完美的映射到焦平面,而蓝点则形成了一个圆形的扩散区域,即弥散,这个区域的半径就是弥散半径。
弥散会造成模糊,因此,一般会把半径设置在一定的范围内。
焦距
在相机模型里面,焦距就是透镜聚焦平行光的能力,如下图所示:
定焦镜头不能修改焦距,而变焦镜头可以,这个就是变焦(相机的“对焦”和“变焦”,这二者有什么区别?):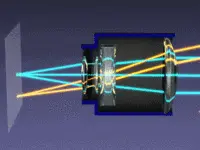
像距
像平面是成像元件所在的平面,成像元件包括图像传感器、胶卷等:
上图像z‘表示像距,f表示焦距。可见:
z
′
=
f
+
z
0
z'=f+z_0
z′=f+z0
不同远近的目标通常不一定能精准的聚焦在焦平面上,因此,调整像距使之匹配就可以让成像清晰,这个过程就叫做变焦。
景深
透镜模型能聚集入射光形成一个焦点,这个焦点所在的平面为焦平面,但是不同远近的目标或者目标点会在焦平面前、后形成焦点,这个时候同样会在焦平面会形成一个弥散圆。如下图所示(from 景深的原理是什么? - 潘安的回答):

上图近点(绿线)的焦点在焦平面后,这个点到焦平面的距离叫做后焦深,远点(红线)的焦点在焦平面前形成,这个点到焦平面的距离叫做前焦深。
从公式可以看出,影响景深的参数有四个:
- 弥散圆。和相机硬件配置有关,一般是固定的。
- 像距。负相关
- 物距。正相关
- 光圈。负相关
FOV
FOV的公式也很简单,定焦镜头下,H为像平面的高,W为宽,f为焦距:
f
o
v
H
=
a
r
c
t
a
n
(
H
f
)
fovH = arctan(\frac{H}{f})
fovH=arctan(fH)
f
o
v
W
=
a
r
c
t
a
n
(
W
f
)
fovW = arctan(\frac{W}{f})
fovW=arctan(fW)
从公式可以看出
- H和W,正i相关
- f,负相关

世界坐标系和相机坐标系转换
下图是常见的四个坐标系(from pytorch3D ):
world->camera
本质是把世界坐标系的原点经过旋转和平移变换到相机坐标系原点(镜头中心),这两个坐标系都是以米作为单位。
P
c
=
R
P
t
+
T
P_{c} = RP_{t} + T
Pc=RPt+T
R和T为相机外参,通过相机标定得到。
世界坐标系的原点可以任意指定,比如车头某个点、或者车身中心。
如果两者重合,那旋转矩阵为 I I I,平移参数为[0, 0, 0]。
举个例子,图1中的两个可见光相机cam_01和 cam_07,如果, R 01 R_{01} R01 和 T 01 T_{01} T01 分别表示cam_01的外参矩阵,则:
P
01
=
R
01
∗
P
w
+
T
01
P_{01} = R_{01}*P_{w} + T_{01}
P01=R01∗Pw+T01
如果知道这两个相机的变换矩阵
R
01
−
>
02
R_{01->02}
R01−>02 和
T
01
−
>
02
T_{01->02}
T01−>02(一般相机之间的安装相对固定):
P
02
=
R
01
−
>
02
∗
P
01
+
T
01
−
>
02
P_{02} = R_{01->02}*P_{01} + T_{01->02}
P02=R01−>02∗P01+T01−>02
camera->NDC
光经过透镜的折射聚集后投影在图像传感器上,这个传感器所在的平面就是NDC。传感器大多以英寸作为单位:
变换矩阵可以通过三角形定理可以可到:
[
x
n
d
c
y
n
d
c
0
]
=
[
f
x
/
z
x
0
0
0
f
y
/
z
y
0
0
0
0
]
∗
[
x
c
a
m
y
c
a
m
0
]
\begin{bmatrix} x_{ndc} \\ y_{ndc} \\ 0 \end{bmatrix} = \begin{bmatrix} f_{x}/z_{x} & 0 & 0 \\ 0 & f_{y}/z_{y} & 0 \\ 0 & 0 & 0 \end{bmatrix} * \begin{bmatrix} x_{cam} \\ y_{cam} \\ 0 \end{bmatrix}
xndcyndc0
=
fx/zx000fy/zy0000
∗
xcamycam0
camera - > screen
很好理解,唯一要注意的就是关于像素和长度的换算问题,不同的分辨率对应不同的缩放系数:
k
x
=
i
m
g
_
w
i
d
t
h
/
W
k_x = img\_width / W
kx=img_width/W
k
y
=
i
m
g
_
h
e
i
g
h
t
/
H
k_y = img\_height / H
ky=img_height/H
screen坐标系的原点在中心,因此还要计算偏移量
u
u
u 和
v
v
v,最后公式如下:
[
x
s
c
r
e
e
n
y
s
c
r
e
e
n
0
]
=
[
k
x
f
x
/
z
x
0
u
0
k
y
f
y
/
z
y
v
0
0
0
]
∗
[
x
c
a
m
y
c
a
m
0
]
\begin{bmatrix} x_{screen} \\ y_{screen} \\ 0 \end{bmatrix} = \begin{bmatrix} k_{x}f_{x}/z_{x} & 0 & u \\ 0 & k_{y}f_{y}/z_{y} & v \\ 0 & 0 & 0 \end{bmatrix} * \begin{bmatrix} x_{cam} \\ y_{cam} \\ 0 \end{bmatrix}
xscreenyscreen0
=
kxfx/zx000kyfy/zy0uv0
∗
xcamycam0
示例
下面是videopose3d关于human3.6M的部分代码,具体见原代码:文章来源:https://www.toymoban.com/news/detail-856791.html
pos_3d = world_to_camera(anim['positions'], R=cam['orientation'], t=cam['translation'])
pos_2d = wrap(project_to_2d, pos_3d, cam['intrinsic'], unsqueeze=True)
pos_2d_pixel_space = image_coordinates(pos_2d, w=cam['res_w'], h=cam['res_h'])
positions_2d.append(pos_2d_pixel_space.astype('float32'))
最后,可能还会涉及四元数、欧拉角等,知识点有点多,以后再慢慢补充。文章来源地址https://www.toymoban.com/news/detail-856791.html
到了这里,关于笔记:立体视觉涉及的相机模型、参数、3D坐标系、内外参计算等的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!