转载自天地风雷水火山泽
目的
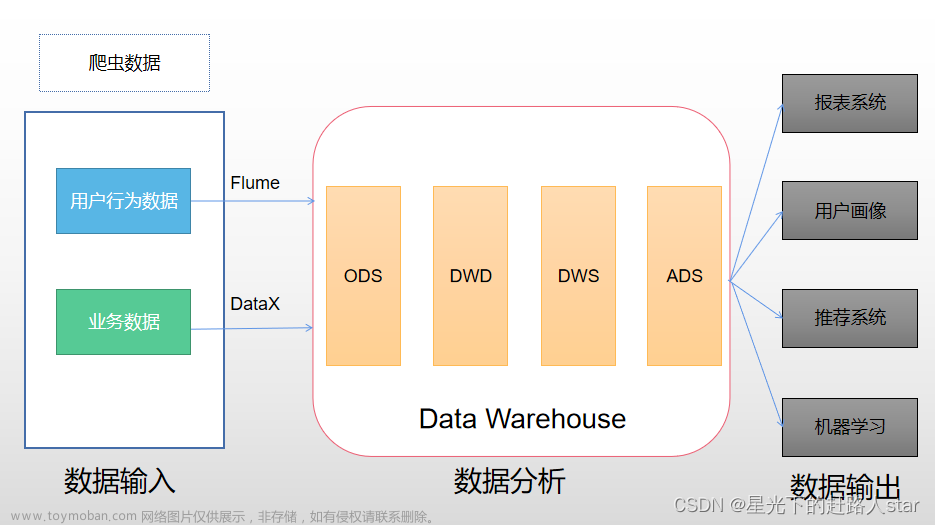
因为我们的数仓数据源是Kafka,离线数仓需要用Flume采集Kafka中的数据到HDFS中。
在实际项目中,我们不可能一直在Xshell中启动Flume任务,一是因为项目的Flume任务很多,二是一旦Xshell页面关闭Flume任务就会停止,这样非常不方便,因此必须在后台启动Flume任务。
所以经过测试后,我发现海豚调度器也可以启动Flume任务。
海豚调度Flume任务配置
(一)Flume在Linux中的路径
(二)Flume任务文件在Linux中的位置以及任务文件名
(三)在海豚中配置运行脚本
#!/bin/bash
source /etc/profile
/usr/local/hurys/dc_env/flume/flume190/bin/flume-ng agent -n a1 -f /usr/local/hurys/dc_env/flume/flume190/conf/statistics.properties
注意:/usr/local/hurys/dc_env/flume/flume190/为Flume在Linux中的安装,根据自己安装路径进行调整
(四)海豚任务配置好后就可以启动海豚任务
(五)在HDFS对应文件夹中验证是否采集到数据
可以看到,Flume采集Kafka数据成功写入到HDFS中,成功实现用Apache DolphinScheduler执行Flume任务的目的!
原文链接:
https://blog.csdn.net/tiantang2renjian/article/details/136399112文章来源:https://www.toymoban.com/news/detail-856794.html
本文由 白鲸开源 提供发布支持!文章来源地址https://www.toymoban.com/news/detail-856794.html
到了这里,关于用DolphinScheduler轻松实现Flume数据采集任务自动化!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!