系列文章:
大数据- Hadoop入门-CSDN博客
大数据 - Hadoop系列《二》- Hadoop组成-CSDN博客
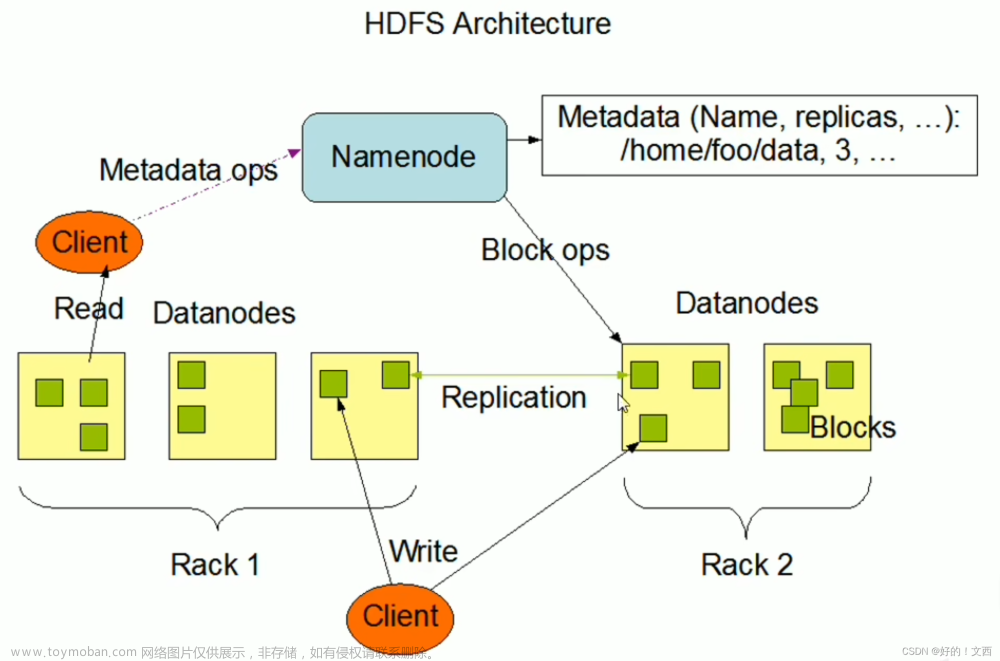
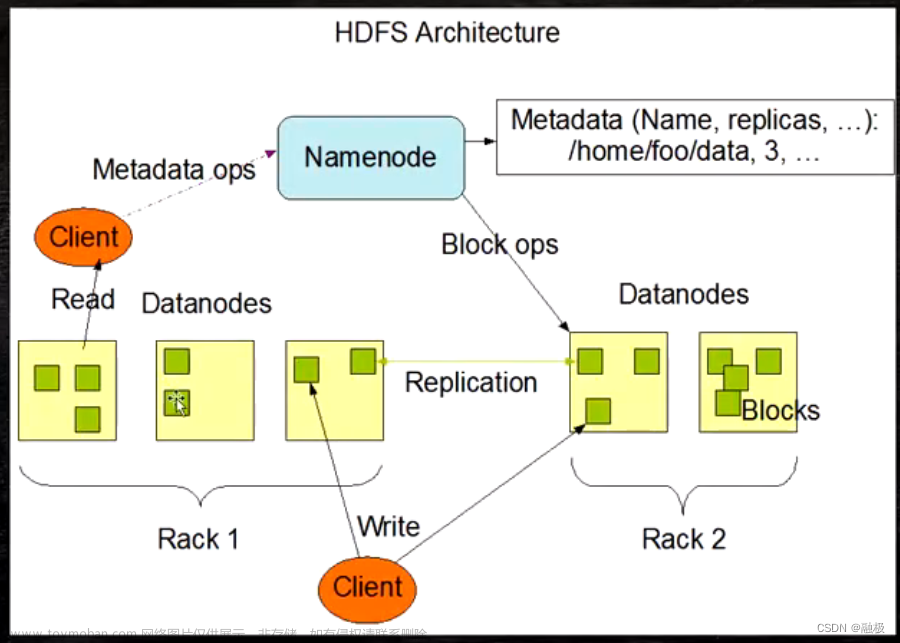
大数据 - Hadoop系列《三》- HDFS(分布式文件系统)概述_大量小文件的存储使用什么分布式文件系统-CSDN博客
大数据 - Hadoop系列《三》- MapReduce(分布式计算引擎)概述-CSDN博客
大数据 - Hadoop系列《四》- MapReduce(分布式计算引擎)的核心思想-CSDN博客
目录
5.1 HDFS文件块大小(面试题)
问题:能不能将块设置的小一些?
问题:不能过小,那能不能过大?
5.2 小文件问题
2. 小文件过多会造成的问题
3. 小文件的解决办法
🥙3.1 使用Hadoop Archive(HAR)将小文件进行归档
🥙3.2 使用SequenceFile合并小文件
🥙3.3 使用CombineFileInputFormat合并小文件:
5.1 HDFS文件块大小(面试题)
HDFS中的文件在物理上是分块存储(Block), 块的大小可以通过配置参数(dfs blocksize)来规定,默认大小在Hadoop2x/3x版本中是128M,1x版本中是64M.

问题:能不能将块设置的小一些?
理论上是可以的,但是如果设置的块大小过小,会占用大量的namenode的元数据空间,而且在读写操作时,加大了寻址时间,所以不建议设置的过小
问题:不能过小,那能不能过大?
不建议,因为设置的过大,传输时间会远远大于寻址时间,增加了网络资源的消耗,而且如果在读写的过程中出现故障,恢复起来也很麻烦,所以不建议
总结:HDFS块的大小设置主要取决于磁盘传输速率。
5.2 小文件问题

1. 小文件是指文件大小明显小于hdfs上块大小的文件
2. 小文件过多会造成的问题
-
HDFS上每个文件都要在NameNode上面创建对应的元数据,这个元数据的大小约为150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用NameNode的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
-
小文件过多,在进行MR计算时,需要启动过多的MapTask,每个MapTask处理的数据量很小,导致MapTask的处理时间比启动时间还小,白白消耗资源。
3. 小文件的解决办法
解决小文件问题的本质就是将小文件进行合并,可以通过以下几种方式解决小文件问题:
注意:和HAR不同的是,这种方式还支持压缩,可以减少减少存储空间的占用。但SequenceFile文件不能追加写入,也不能修改, 适用于一次性写入大量小文件的操作。
🥙3.1 使用Hadoop Archive(HAR)将小文件进行归档
使用Hadoop自带的HAR将小文件进行归档,将多个小文件打包成一个HAR文件,这样NameNode中的元数据也就存储一份。在减少namenode内存使用的同时,仍然可以对文件进行透明的访问。
🥙3.2 使用SequenceFile合并小文件
可以使用SequenceFile格式将大批的小文件合并成一个大文件,再使用MapReduce程序进行操作,从而提高系统性能。
🥙3.3 使用CombineFileInputFormat合并小文件:
在MR读取数据时将多个小文件合并成一个文件进行处理,只开启一个MapTask,提高了任务的执行效率。文章来源:https://www.toymoban.com/news/detail-856882.html
文章来源地址https://www.toymoban.com/news/detail-856882.html
到了这里,关于大数据 - Hadoop系列《五》- HDFS文件块大小及小文件问题的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!