主角查看与分析 爬取
对猫眼电影票房进行爬取,首先我们打开猫眼
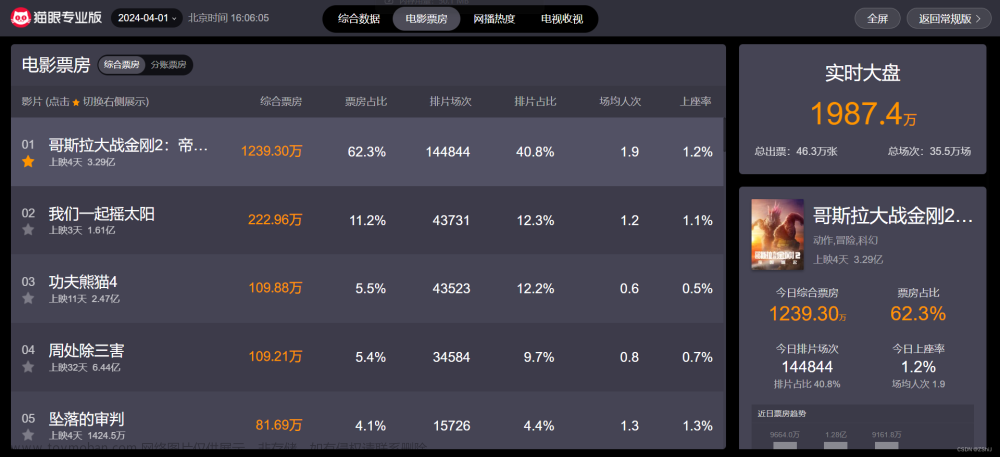
接着我们想要进行数据抓包,就要看网站的具体内容,通过按F12,我们可以看到详细信息。
通过两个对比,我们不难发现User-Agent和 signKey数据是变化的(平台使用了数据加密)
所以我们需要对User-Agent与signKey分别进行解密。
通过造一个content字符串,包含请求方法、时间戳、User-Agent、index等信息,并对其进行MD5加密得到sign。最后将这些参数放入params字典中,准备发送请求。
def getData():
url = 'https://piaofang.maoyan.com/dashboard-ajax/movie'
useragents = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36 Edg/115.0.1901.183'
headers = {
'User-Agent':useragents,
'Referer':'https://piaofang.maoyan.com/dashboard/movie'
}
useragents = str(base64.b64encode(useragents.encode('utf-8')),'utf-8')
index = str(round(random.random() * 1000))
times = str(math.ceil(time.time() * 1000))
content = "method=GET&timeStamp={}&User-Agent={}&index={}&channelId=40009&sVersion=2&key=A013F70DB97834C0A5492378BD76C53A".format(times,useragents,index)
md5 = hashlib.md5()
md5.update(content.encode('utf-8'))
sign = md5.hexdigest()
params = {
'orderType': '0',
'uuid': '17d79b87a00c8-015087c7514df4-5919145b-144000-17d79b87a00c8',
# 时间戳
'timeStamp': times,
# base64加密
'User-Agent': useragents,
# 随机数 * 1000取整
'index': index,
'channelId': '40009',
'sVersion': '2',
# md5加密
'signKey': sign
}
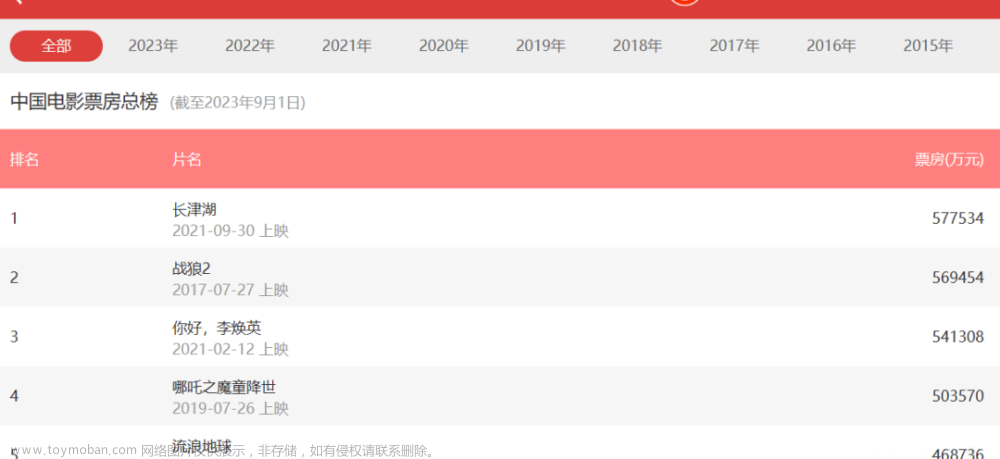
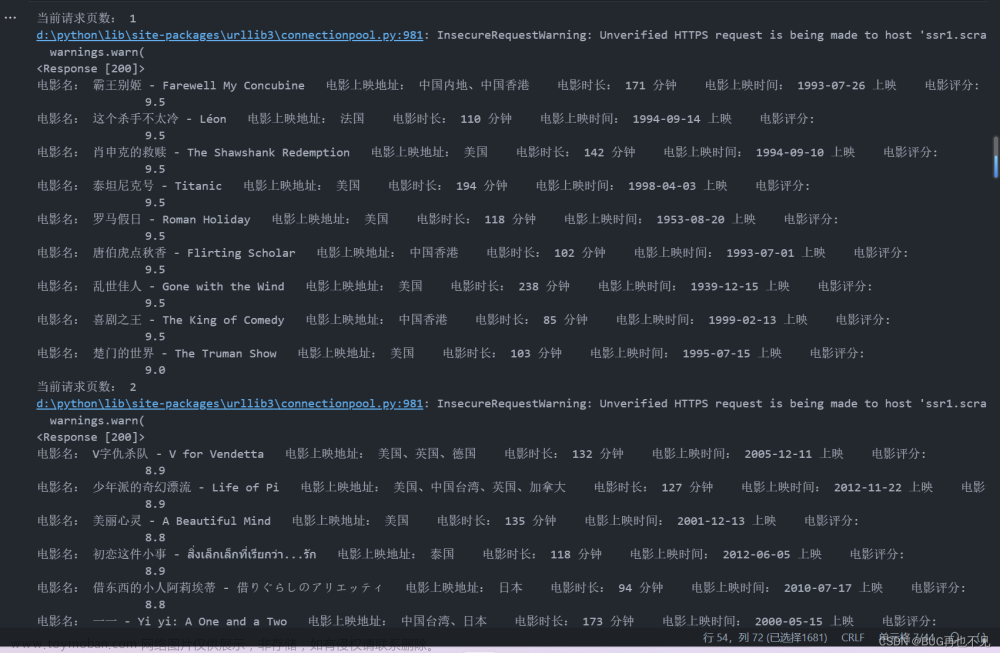
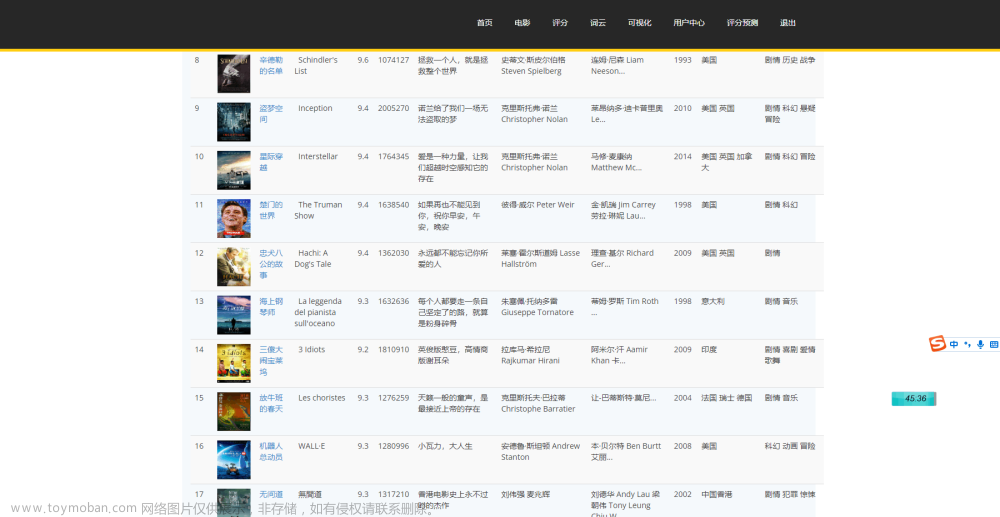
接着我们就可以对于猫眼电影票房数据进行爬取了,比如上座率、场均人次、票房占比、电影名称、上映时间、综合票房、排片场次和排片占比等。
resps = requests.get(url = url , headers = headers, params = params).json()
# print(resps)
# 上座率数据缺省值这么使用数据
data_avgSeatView = jsonpath.jsonpath(resps, '$..avgSeatView')
# print(data_avgSeatView)
# 场均人次
data_avgShowView=jsonpath.jsonpath(resps,'$..avgShowView')
# 票房占比
data_boxRate=jsonpath.jsonpath(resps,'$..boxRate')
# 电影名称
data_name=jsonpath.jsonpath(resps,'$..movieName')
# 上映时间
data_time=jsonpath.jsonpath(resps,'$..releaseInfo')
# 综合票房
data_sumBoxDesc=jsonpath.jsonpath(resps,'$..sumBoxDesc')
# 排片场次
data_showCount=jsonpath.jsonpath(resps,'$..showCount')
# 排片占比
data_showCountRate=jsonpath.jsonpath(resps,'$..showCountRate')
data={'电影名称':data_name,'上映时间':data_time,'上座率':data_avgSeatView,'场均人次':data_avgShowView,
'票房占比':data_boxRate,'综合票房':data_sumBoxDesc,'排片场次':data_showCount,'排片占比':data_showCountRate}
df = pd.DataFrame(pd.DataFrame.from_dict(data, orient='index').values.T, columns=list(data.keys()))
print(df)
df.to_csv("猫眼电影1.csv",index=False,encoding='utf-8')
通过DataFrame输出到控制台我们可以看到爬取成功。
可视化分析
import pandas as pd
data=pd.read_csv("猫眼电影1.csv")

数据缺省值处理
# 去除空值
data.dropna(inplace=True)
data
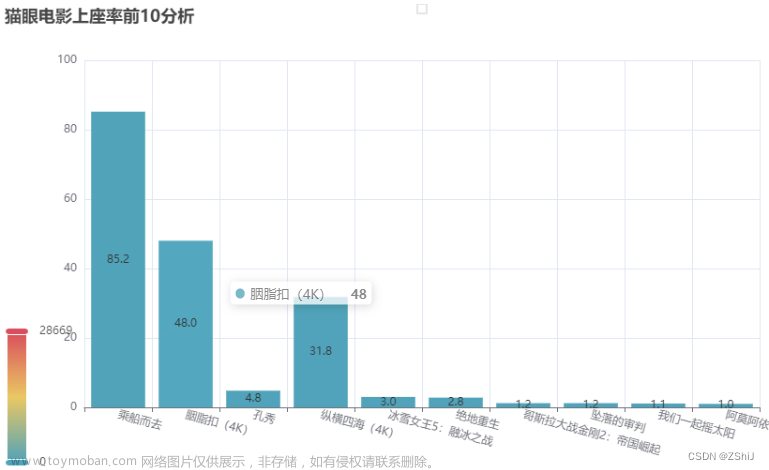
猫眼电影上座率前10分析
data_sorted = data.sort_values(by='上座率', ascending=False)
data_top10=data_sorted.head(10)
data_top10

data_top10['电影名称'].tolist()

percentage=data_top10['上座率'].tolist()
data_shangan=[percentage.replace("%", "") for percentage in percentage]
data_shangan

from pyecharts.charts import Bar,Line,Map,Page,Pie
from pyecharts import options as opts
from pyecharts.globals import SymbolType
from pyecharts.charts import Bar
# from pyecharts.charts import opts
#条形图
#bar1 = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
bar1 = Bar()
bar1.add_xaxis(data_top10['电影名称'].tolist())
bar1.add_yaxis('', data_shangan)
bar1.set_global_opts(title_opts=opts.TitleOpts(title='猫眼电影上座率前10分析'),
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15)),
visualmap_opts=opts.VisualMapOpts(max_=28669)
)
bar1.render_notebook()
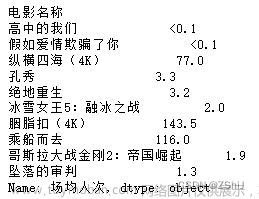
猫眼电影票房场均人次前10分析
data_sum = data.groupby('电影名称')['场均人次'].sum().sort_values(ascending=False)
data_sum[:10]
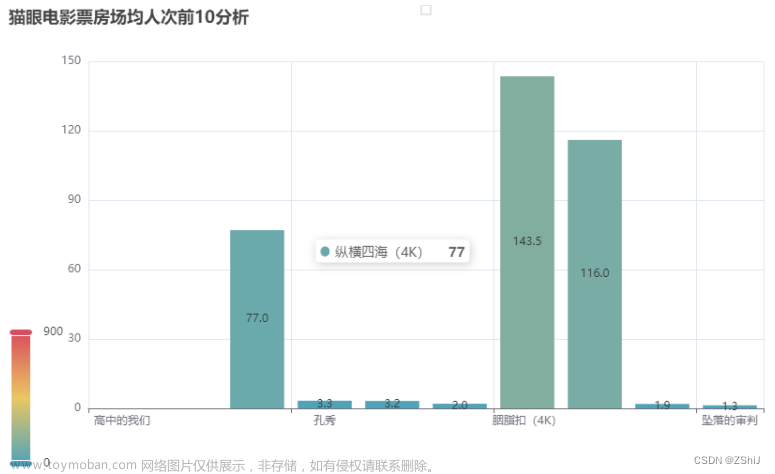
bar3 = Bar()
bar3.add_xaxis(data_sum[:10].index.tolist())
bar3.add_yaxis('', data_sum[:10].values.tolist())
bar3.set_global_opts(title_opts=opts.TitleOpts(title='猫眼电影票房场均人次前10分析'),
visualmap_opts=opts.VisualMapOpts(max_=900))
bar3.render_notebook()
猫眼电影票票房占比分析
data_pf= data.groupby('电影名称')['票房占比'].sum().sort_values(ascending=False)
data_pfzb=data_pf.tail(24)
data_pfzb.head(10)
 文章来源:https://www.toymoban.com/news/detail-856915.html
文章来源:https://www.toymoban.com/news/detail-856915.html
data_pftop10 = [list(z) for z in zip(data_pf.index.tolist(), data_pf.values.tolist())]
# 绘制饼图
pie1 = Pie()
pie1.add('', data_pftop10, radius=['35%', '60%'])
pie1.set_global_opts(title_opts=opts.TitleOpts(title='猫眼电影票票房占比分析'),
legend_opts=opts.LegendOpts(orient='vertical', pos_top='15%', pos_left='2%'))
pie1.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%"))
pie1.set_colors(['#EF9050', '#3B7BA9', '#6FB27C', '#FFAF34', '#D8BFD8', '#00BFFF', '#7FFFAA'])
pie1.render_notebook()
 文章来源地址https://www.toymoban.com/news/detail-856915.html
文章来源地址https://www.toymoban.com/news/detail-856915.html
到了这里,关于Python爬取猫眼电影票房 + 数据可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!