Spark 概述
Spark 所需资料
链接:https://pan.baidu.com/s/12iaW68vriL6i-xI1kmr0_g?pwd=m4zc
提取码:m4zc
Spark 是什么
Spark 是一种基于内存的快速、通用、可扩展的大数据分析计算引擎。
Spark and Hadoop
- 首先从时间节点上来看:
- Hadoop
- 2006年1月,Doug Cutting加入Yahoo,领导Hadoop的开发
- 2008年1月,Hadoop成为Apache顶级项目
- 2011年1.0正式发布
- 2012年3月稳定版发布
- 2013年10月发布2.X (Yarn)版本
- Spark
- 2009年,Spark诞生于伯克利大学的AMPLab实验室
- 2010年,伯克利大学正式开源了Spark项目
- 2013年6月,Spark成为了Apache基金会下的项目
- 2014年2月,Spark以飞快的速度成为了Apache的顶级项目
- 2015年至今,Spark变得愈发火爆,大量的国内公司开始重点部署或者使用Spark
- Hadoop
- 从功能上看:
- Hadoop
- Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式
分析应用的开源框架 - 作为Hadoop 分布式文件系统,HDFS处于Hadoop生态圈的最下层,存储着所有
的数据,支持着 Hadoop 的所有服务。它的理论基础源于 Google 的TheGoogleFileSystem 这篇论文,它是GFS的开源实现。 - MapReduce 是一种编程模型,Hadoop根据Google的MapReduce 论文将其实现,
作为Hadoop 的分布式计算模型,是Hadoop的核心。基于这个框架,分布式并行
程序的编写变得异常简单。综合了HDFS的分布式存储和MapReduce的分布式计
算,Hadoop在处理海量数据时,性能横向扩展变得非常容易。 - HBase是对Google 的Bigtable 的开源实现,但又和Bigtable 存在许多不同之处。
HBase 是一个基于HDFS的分布式数据库,擅长实时地随机读/写超大规模数据集。
它也是Hadoop非常重要的组件。
- Hadoop是由java语言编写的,在分布式服务器集群上存储海量数据并运行分布式
- Spark
- Spark是一种由Scala语言开发的快速、通用、可扩展的大数据分析引擎
- Spark Core 中提供了Spark最基础与最核心的功能
- Spark SQL是Spark用来操作结构化数据的组件。通过Spark SQL,用户可以使用
SQL 或者Apache Hive 版本的SQL方言(HQL)来查询数据。 - Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的
处理数据流的API。
- Hadoop
Spark and Hadoop
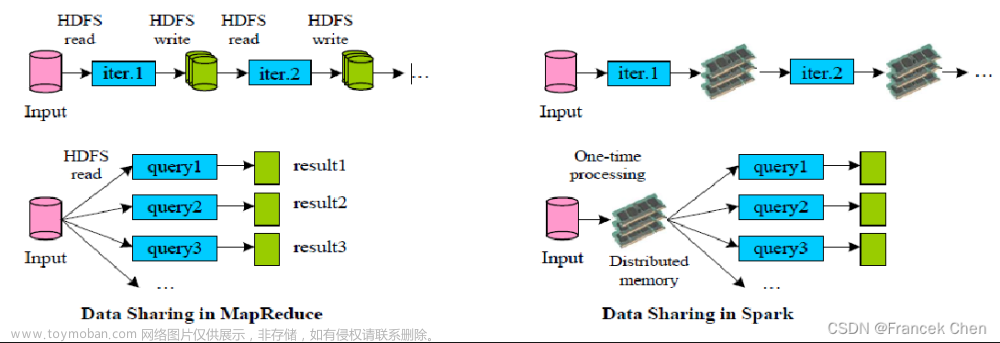
- Hadoop MapReduce 由于其设计初衷并不是为了满足循环迭代式数据流处理,因此在多
并行运行的数据可复用场景(如:机器学习、图挖掘算法、交互式数据挖掘算法)中存
在诸多计算效率等问题。所以Spark应运而生,Spark就是在传统的MapReduce 计算框
架的基础上,利用其计算过程的优化,从而大大加快了数据分析、挖掘的运行和读写速
度,并将计算单元缩小到更适合并行计算和重复使用的RDD计算模型。 - 机器学习中 ALS、凸优化梯度下降等。这些都需要基于数据集或者数据集的衍生数据
反复查询反复操作。MR这种模式不太合适,即使多MR串行处理,性能和时间也是一
个问题。数据的共享依赖于磁盘。另外一种是交互式数据挖掘,MR 显然不擅长。而
Spark 所基于的scala语言恰恰擅长函数的处理。 - Spark 是一个分布式数据快速分析项目。它的核心技术是弹性分布式数据集(Resilient
Distributed Datasets),提供了比 MapReduce 丰富的模型,可以快速在内存中对数据集
进行多次迭代,来支持复杂的数据挖掘算法和图形计算算法。 - Spark和Hadoop的根本差异是多个作业之间的数据通信问题 : Spark多个作业之间数据
通信是基于内存,而Hadoop是基于磁盘。 - Spark Task 的启动时间快。Spark采用fork线程的方式,而Hadoop采用创建新的进程
的方式。 - Spark只有在shuffle的时候将数据写入磁盘,而Hadoop中多个MR作业之间的数据交
互都要依赖于磁盘交互 - Spark的缓存机制比HDFS的缓存机制高效。
Spark 核心模块

- Spark Core
Spark Core 中提供了 Spark 最基础与最核心的功能,Spark其他的功能如:Spark SQL,Spark Streaming,GraphX, MLlib 都是在 Spark Core 的基础上进行扩展的 - Spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。通过Spark SQL,用户可以使用SQL或者Apache Hive 版本的SQL方言(HQL)来查询数据。 - Spark Streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API。 - Spark MLlib
MLlib 是 Spark 提供的一个机器学习算法库。MLlib不仅提供了模型评估、数据导入等额外的功能,还提供了一些更底层的机器学习原语。 - Spark GraphX
GraphX 是Spark 面向图计算提供的框架与算法库。
Spark 简单上手
创建Maven项目
增加 Scala 插件
Spark 由 Scala 语言开发的,所以本课件接下来的开发所使用的语言也为Scala,咱们当前使用的Spark版本为3.0.0,默认采用的Scala编译版本为2.12,所以后续开发时。我们依然采用这个版本。开发前请保证IDEA开发工具中含有Scala开发插件(在Plugins中进行下载)
增加依赖关系
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
</dependencies>
WordCount
创建一个WordCount
在该项目路径下创建一个datas包,创建word.txt文件
// 创建Spark运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
// 创建Spark上下文环境对象(连接对象)
val sc : SparkContext = new SparkContext(sparkConf)
// 读取文件数据
val fileRDD: RDD[String] = sc.textFile("datas/word.txt")
// 将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap( _.split(" ") )
// 转换数据结构 word => (word, 1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_,1))
// 将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_+_)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭Spark连接
sc.stop()
执行过程中,会产生大量的执行日志,如果为了能够更好的查看程序的执行结果,可以在项
目的resources目录中创建log4j.properties文件,并添加日志配置信息:
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistentUDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
异常处理
如果本机操作系统是Windows,在程序中使用了Hadoop相关的东西,比如写入文件到
HDFS,则会遇到如下异常:
Failed to locate the winutils binary in the hadoop binary path
在资料找到WindowsDep查找对应的hadoop版本文章来源:https://www.toymoban.com/news/detail-857017.html
在IDEA中配置Run Configuration,添加HADOOP_HOME变量 文章来源地址https://www.toymoban.com/news/detail-857017.html
文章来源地址https://www.toymoban.com/news/detail-857017.html
到了这里,关于大数据Spark--入门的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!